Relevance vector machine
In mathematics, a relevance vector machine (RVM) is a machine learning technique that uses Bayesian inference to obtain parsimonious solutions for regression and probabilistic classification.[1] The RVM has an identical functional form to the support vector machine, but provides probabilistic classification.
It is actually equivalent to a Gaussian process model with covariance function:
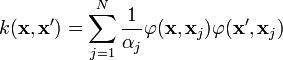
where 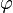 is the kernel function (usually Gaussian),
is the kernel function (usually Gaussian),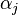 's as the variances of the prior on the weight vector
's as the variances of the prior on the weight vector
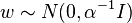 ,and
,and 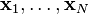 are the input vectors of the training set.
are the input vectors of the training set.
Compared to that of support vector machines (SVM), the Bayesian formulation of the RVM avoids the set of free parameters of the SVM (that usually require cross-validation-based post-optimizations). However RVMs use an expectation maximization (EM)-like learning method and are therefore at risk of local minima. This is unlike the standard sequential minimal optimization (SMO)-based algorithms employed by SVMs, which are guaranteed to find a global optimum (of the convex problem).
The relevance vector machine is patented in the United States by Microsoft.[2]
See also
- Kernel trick
- Platt scaling: turns an SVM into a probability model
References
- ↑ Tipping, Michael E. (2001). "Sparse Bayesian Learning and the Relevance Vector Machine". Journal of Machine Learning Research 1: 211–244.
- ↑ US 6633857, Michael E. Tipping, "Relevance vector machine"