Regression discontinuity design
In statistics, econometrics, political science, epidemiology, and related disciplines, a regression discontinuity design (RDD) is a quasi-experimental pretest-posttest design that elicits the causal effects of interventions by assigning a cutoff or threshold above or below which an intervention is assigned. By comparing observations lying closely on either side of the threshold, it is possible to estimate the local Average treatment effect in environments in which randomization was unfeasible. First applied by Donald Thistlewaite and Donald Campbell to the evaluation of scholarship programs,[1] the RDD has become increasingly popular in recent years.[2]
Example
The intuition behind the RDD is well illustrated using the evaluation of merit-based scholarships. The main problem with estimating the causal effect of such an intervention is the endogeneity of assignment to treatment (e.g. scholarship award): Since high-performing students are more likely to be awarded the merit scholarship and continue performing well at the same time, comparing the outcomes of awardees and non-recipients would lead to an upward bias of the estimates. Even if the scholarship did not improve grades at all, awardees would have performed better than non-recipients, simply because scholarships were given to students who were performing well ex ante.
Despite the absence of an experimental design, a RDD can exploit exogenous characteristics of the intervention to elicit causal effects. If all students above a given grade—for example 80%—are given the scholarship, it is possible to elicit the local treatment effect by comparing students around the 80% cut-off: The intuition here is that a student scoring 79% is likely to be very similar to a student scoring 81%—given the pre-defined threshold of 80%, however, one student will receive the scholarship while the other will not. Comparing the outcome of the awardee (treatment group) to the counterfactual outcome of the non-recipient (control group) will hence deliver the local treatment effect.
Methodology
The two most common approaches to estimation using a RDD are nonparametric and parametric (normally polynomial regression).
Non-parametric estimation
The most common non-parametric method used in the RDD context is a local linear regression. This is of the form:
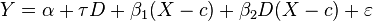
where 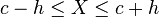 Where
Where  is the treatment cut-off,
is the treatment cut-off, 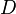 is a binary variable equal to one if
is a binary variable equal to one if 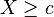 , and
, and 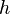 is the bandwidth of data used. Different slopes and intercepts fit data on either side of the cutoff. Typically either a rectangular kernel (no weighting) or a triangular kernel are used. Research favors the triangular kernel[3] but the rectangular kernel has a more straightforward interpretation.[4]
is the bandwidth of data used. Different slopes and intercepts fit data on either side of the cutoff. Typically either a rectangular kernel (no weighting) or a triangular kernel are used. Research favors the triangular kernel[3] but the rectangular kernel has a more straightforward interpretation.[4]
The major benefit of using non-parametric methods in a RDD is that they provide estimates based on data closer to the cut-off, which is intuitively appealing. This reduces some bias that can result from using data farther away from the cutoff to estimate the discontinuity at the cutoff.[4] More formally, local linear regressions are preferred because they have better bias properties[3] and have better convergence.[5] However, the use of both types estimation, if feasible, is a useful way to argue that the estimated results do not rely too heavily on the particular approach taken.
Parametric estimation
Other examples
- Policies in which treatment is determined by an age eligibility criterion (e.g. pensions, minimum legal drinking age).[6][7]
- Elections in which one politician wins by a marginal majority.[8]
- Placement scores within education that sort students into treatment programs.[9]
Required assumptions
Regression discontinuity design requires that treatment assignment is "as good as random" at the threshold for treatment.[8] If this holds, then it guarantees that those who just barely received treatment are comparable to those who just barely did not receive treatment, as treatment status is effectively random.
Treatment assignment at the threshold can be "as good as random" if there is randomness in the assignment variable and the agents considered (individuals, firms, etc.) cannot perfectly manipulate their treatment status. For example, if the treatment is passing an exam, where a grade of 50% is required, then this example is a valid regression discontinuity design so long as grades are somewhat random, due either to randomness of grading or randomness of student performance.
Students must not also be able to perfectly manipulate their grade so as to perfectly determine their treatment status. Two examples include students being able to convince teachers to "mercy pass" them, or students being allowed to re-take the exam until they pass. In the former case, those students who barely fail but are able to secure a "mercy pass" may differ from those who just barely fail but cannot secure a "mercy pass". This leads to selection bias, as the treatment and control groups now differ. In the later case, some students may decide to retake the exam, stopping once they pass. This also leads to selection bias since only some students will decide to retake the exam.[4]
Testing the validity of the assumptions
It is impossible to definitively test for if agents are able to perfectly determine their treatment status. However, there are some tests that can provide evidence that either supports or discounts the validity of the regression discontinuity design.
Density test
_Density_Test_on_Data_from_Lee%2C_Moretti%2C_and_Butler_(2004).png)
McCrary (2008) suggested examining the density of observations of the assignment variable.[10] If there is a discontinuity in the density of the assignment variable at the threshold for treatment, then this may suggest that some agents were able to perfectly manipulate their treatment status.
For example, if several students are able to get a "mercy pass", then there will be more students who just barely passed the exam than who just barely failed. Similarly, if students are allowed to retake the exam until they pass, then there will be a similar result. In both cases, this will likely show up when the density of exam grades is examined. "Gaming the system" in this manner could bias the treatment effect estimate.
Continuity of observable variables
Since the validity of the regression discontinuity design relies on those who were just barely treated being the same as those who were just barely not treated, it makes sense to examine if these groups are similar based on observable variables. For the earlier example, one could test if those who just barely passed have different characteristics (demographics, family income, etc.) than those who just barely failed. Although some variables may differ for the two groups based on random chance, most of these variables should be the same.[11]
Falsification tests
Predetermined variables
Similar to the continuity of observable variables, one would expect there to be continuity in predetermined variables at the treatment cut-off. Since these variables were determined before the treatment decision, treatment status should have no effect on them. Consider the earlier merit-based scholarship example. If the outcome of interest is future grades, then we would not expect the scholarship to affect earlier grades. If a discontinuity in predetermined variables is present at the treatment cut-off, then this puts the validity of the regression discontinuity design into question.
Other discontinuities
If discontinuities are present at other points of the assignment variable, where these are not expected, then this may make the regression discontinuity design suspect. Consider the example of Carpenter and Dobkin (2011) who studied the effect of legal access to alcohol in the United States.[7] As access to alcohol increases at age 21, this leads to changes in various outcomes, such as mortality rates and morbidity rates. If mortality and morbidity rates also increase discontinuously at other ages, then it throws the interpretation of the discontinuity at age 21 into question.
Inclusion and exclusion of covariates
If parameter estimates are sensitive to removing or adding covariates to the model, then this may cast doubt on the validity of the regression discontinuity design. A significant change may suggest that those who just barely got treatment differ in these covariates from those who just barely did not get treatment. Including covariates would remove some of this bias. If a large amount of bias is present, and the covariates explain a significant amount of this, then their inclusion or exclusion would significantly change the parameter estimate.[4]
Advantages
- When properly implemented and analyzed, the RDD yields an unbiased estimate of the local treatment effect.[12] The RDD can be almost as good as a randomised experiment in measuring a treatment effect.
- RDD, as a quasi-experiment, does not require ex ante randomization and circumvents ethical issues of random assignment.
- Well-executed RDD studies can generate treatment effect estimates similar to estimates from randomized studies.
Disadvantages
- The statistical power is considerably lower than a randomized experiment of the same sample size, increasing the risk of erroneously dismissing significant effects of the treatment (Type II error)[13]
- The estimated effects are only unbiased if the functional form of the relationship between the treatment and outcome is correctly modelled. The most popular caveats are non-linear relationships that are mistaken as a discontinuity.
- Contamination by other treatments. If another treatment occurs at the same cut-off value of the same assignment variable, then the measured discontinuity in the outcome variable may be partially attributed to this other treatment. For example, suppose a researcher wishes to study the impact of legal access to alcohol on mental health using a regression discontinuity design at the minimum legal drinking age. The measured impact could be confused with legal access to gambling, which may occur at the same age.
Extensions
Fuzzy RDD
The identification of causal effects hinges on the crucial assumption that there is indeed a sharp cut-off, around which there is a discontinuity in the probability of assignment from 0 to 1. In reality, however, cut-offs are often not strictly implemented (e.g. exercised discretion for students who just fell short of passing the threshold) and the estimates will hence be biased.
In contrast to the sharp regression discontinuity design, a fuzzy regression discontinuity design (FRDD) does not require a sharp discontinuity in the probability of assignment but is applicable as long as the probability of assignment is different. The intuition behind it is related to the instrumental variable strategy and intention to treat.
Regression kink design
When the assignment variable is continuous (e.g. student aid) and depends predictably on another observed variable (e.g. family income), one can identify treatment effects using sharp changes in the slope of the treatment function. This technique was coined regression kink design by Nielsen, Sørensen, and Tabe (2010), though they cite similar earlier analyses.[14] They write, "This approach resembles the regression discontinuity idea. Instead of a discontinuity of in the level of the stipend-income function, we have a discontinuity in the slope of the function." Rigorous theoretical foundations were provided by Card et al. (2012).[15]
Note that regression kinks (or kinked regression) can also mean a type of segmented regression, which is a different type of analysis.
See also
- Quasi-experiment
- Design of quasi-experiments
References
- ↑ Thistlewaite, D.; Campbell, D. (1960). "Regression-Discontinuity Analysis: An alternative to the ex post facto experiment". Journal of Educational Psychology 51 (6): 309–317. doi:10.1037/h0044319.
- ↑ Imbens, G.; Lemieux, T. (2008). "Regression Discontinuity Designs: A Guide to Practice". Journal of Econometrics 142 (2): 615–635. doi:10.1016/j.jeconom.2007.05.001.
- ↑ 3.0 3.1 Fan; Gijbels (1996). Local Polynomial Modelling and Its Applications. London: Chapman and Hall. ISBN 0-412-98321-4.
- ↑ 4.0 4.1 4.2 4.3 Lee; Lemieux (2010). "Regression Discontinuity Designs in Economics". Journal of Economic Literature 48 (2): 281–355. doi:10.1257/jel.48.2.281.
- ↑ Porter (2003). "Estimation in the Regression Discontinuity Model" (PDF). Unpublished Manuscript.
- ↑ Duflo (2003). "Grandmothers and Granddaughters: Old-age Pensions and Intrahousehold Allocation in South Africa". World Bank Economic Review 17 (1): 1–25. doi:10.1093/wber/lhg013.
- ↑ 7.0 7.1 Carpenter; Dobkin (2011). "The Minimum Legal Drinking Age and Public Health". Journal of Economic Perspectives 25 (2): 133–156. doi:10.1257/jep.25.2.133. JSTOR 23049457. PMC 3182479. PMID 21595328.
- ↑ 8.0 8.1 Lee (2008). "Randomized Experiments from Non-random Selection in U.S. House Elections". Journal of Econometrics 142 (2): 675–697. doi:10.1016/j.jeconom.2007.05.004.
- ↑ Moss, B. G.; Yeaton, W. H.; Lloyd, J.E. (2014). "Evaluating the Effectiveness of Developmental Mathematics by Embedding a Randomized Experiment Within a Regression Discontinuity Design.". Educational Evaluation and Policy Analysis 36 (2): 170–185. doi:10.3102/0162373713504988.
- ↑ 10.0 10.1 McCrary (2008). "Manipulation of the Running Variable in the Regression Discontinuity Design: A Density Test". Journal of Economic Literature 142 (2): 698–714. doi:10.1016/j.jeconom.2007.05.005.
- ↑ 11.0 11.1 Lee; Moretti; Butler (2004). "Do Voters Affect or Elect Policies? Evidence from the U.S. House". Quarterly Journal of Economics 119 (3): 807–859. doi:10.1162/0033553041502153.
- ↑ Rubin (1977). "Assignment to Treatment on the Basis of a Covariate". Journal of Educational and Behavioural Statistics 2 (1): 1–26. doi:10.3102/10769986002001001.
- ↑ Angrist; Pischke (2008). "Getting a Little Jumpy: Regression Discontinuity Designs". Mostly Harmless Econometrics: An Empiricist's Companion. Princeton University Press. pp. 251–268. ISBN 978-0-691-12035-5.
- ↑ Nielsen, H. S.; Sørensen, T.; Taber, C. R. (2010). "Estimating the Effect of Student Aid on College Enrollment: Evidence from a Government Grant Policy Reform". American Economic Journal: Economic Policy 2 (2): 185–215. doi:10.1257/pol.2.2.185. JSTOR 25760068.
- ↑ Card, David; Lee, David S.; Pei, Zhuan; Weber, Andrea (2012). "Nonlinear Policy Rules and the Identification and Estimation of Causal Effects in a Generalized Regression Kink Design". NBER Working Paper No. w18564. SSRN 2179402.
Further reading
- Imbens, Guido W.; Wooldridge, Jeffrey M. (2009). "Recent Developments in the Econometrics of Program Evaluation". Journal of Economic Literature 47 (1): 5–86. doi:10.1257/jel.47.1.5.
External links
- Regression-Discontinuity Analysis at Research Methods Knowledge Base
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||