Qualitative variation
An index of qualitative variation (IQV) is a measure of statistical dispersion in nominal distributions. There are a variety of these, but they have been relatively little-studied in the statistics literature. The simplest is the variation ratio, while more complex indices include the information entropy.
Properties
There several types of index used for the analysis of nominal data. Several are standard statistics that are used elsewhere - range, standard deviation, variance, mean deviation, coefficient of variation, median absolute deviation, interquartile range and quartile deviation.
In addition to these several statistics have been developed with nominal data in mind. A number have been summarized and devised by Wilcox (Wilcox 1967), (Wilcox 1973), who requires the following standardization properties to be satisfied:
- Variation varies between 0 and 1.
- Variation is 0 if and only if all cases belong to a single category.
- Variation is 1 if and only if cases are evenly divided across all category.[1]
In particular, the value of these standardized indices does not depend on the number of categories or number of samples.
For any index, the closer to uniform the distribution, the larger the variance, and the larger the differences in frequencies across categories, the smaller the variance.
Indices of qualitative variation are then analogous to information entropy, which is minimized when all cases belong to a single category and maximized in a uniform distribution. Indeed, information entropy can be used as an index of qualitative variation.
One characterization of a particular index of qualitative variation (IQV) is as a ratio of observed differences to maximum differences.
Wilcox's indexes
Wilcox gives a number of formulae for various indices of QV (Wilcox 1973), the first, which he designates DM for "Deviation from the Mode", is a standardized form of the variation ratio, and is analogous to variance as deviation from the mean.
ModVR
The formula for the variation around the mode (ModVR) is derived as follows:
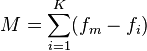
where fm is the modal frequency, K is the number of categories and fi is the frequency of the ith group.
This can be simplified to
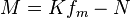
where N is the total size of the sample.
Freeman's index (or variation ratio) is[2]
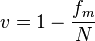
This is related to M as follows:
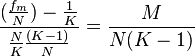
The ModVR is defined as
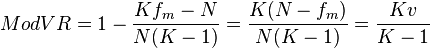
where v is Freeman's index.
Low values of ModVR correspond to small amount of variation and high values to larger amounts of variation.
When K is large, ModVR is approximately equal to Freeman's index v.
RanVR
This is based on the range around the mode. It is defined to be
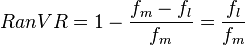
where fm is the modal frequency and fl is the lowest frequency.
AvDev
This is an analog of the mean deviation. It is defined as the arithmetic mean of the absolute differences of each value from the mean.
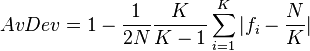
MNDif
This is an analog of the mean difference - the average of the differences of all the possible pairs of variate values, taken regardless of sign. The mean difference differs from the mean and standard deviation because it is dependent on the spread of the variate values among themselves and not on the deviations from some central value.[3]
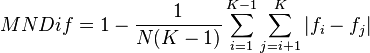
where fi and fj are the ith and jth frequencies respectively.
The MNDif is the Gini coefficient applied to qualitative data.
VarNC
This is an analog of the variance.
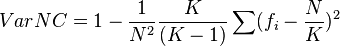
It is the same index as Mueller and Schussler's Index of Qualitative Variation[4] and Gibbs' M2 index.
It is distributed as a chi square variable with K - 1 degrees of freedom.[5]
StDev
Wilson has suggested two versions of this statistic.
The first is based on AvDev.
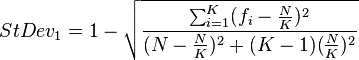
The second is based on MNDif
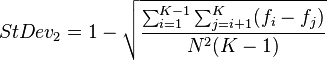
HRel
This index was originally developed by Claude Shannon for use in specifying the properties of comnmunication channels.
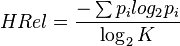
where pi = fi / N.
Gibb's indices and related formulae
Gibbs et al proposed six indexes.[6]
M1
The unstandardized index (M1) (Gibbs 1975, p. 471) is
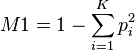
where K is the number of categories and 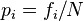 is the proportion of observations that fall in a given category i.
is the proportion of observations that fall in a given category i.
M1 can be interpreted as one minus the likelihood that a random pair of samples will belong to the same category (Lieberson 1969, p. 851), so this formula for IQV is a standardized likelihood of a random pair falling in the same category. This index has also referred to as the index of differentiation, the index of sustenance differentiation and the geographical differentiation index depending on the context it has been used in.
M2
A second index is the M2[7](Gibbs 1975, p. 472) is:
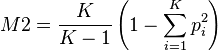
where K is the number of categories and is the proportion of observations that fall in a given category i. The factor of 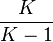 is for standardization.
is for standardization.
M1 and M2 can be interpreted in terms of variance of a multinomial distribution (Swanson 1976) (there called an "expanded binomial model"). M1 is the variance of the multinomial distribution and M2 is the ratio of the variance of the multinomial distribution to the variance of a binomial distribution.
M4
The M4 index is
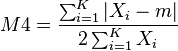
where m is the mean.
M6
The formula for M6 is
![M6 = K \left[ 1 - \frac{ \sum_{ i = 1 }^K | X_i - m | }{ 2 N } \right]](../I/m/23caf5a7ddf4034c955db183fd17a7bf.png)
where K is the number of categories, Xi is the number of data points in the ith category, N is the total number of data points, || is the absolute value (modulus) and
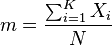
This formula can be simplified
![M6 = K\left[ 1 - \frac{ \sum_{ i = 1 }^K | p_i - \frac{ 1 }{ N } | }{ 2 } \right]](../I/m/c54b1d10c6d04009a32afc29ebc79125.png)
where pi is the proportion of the sample in the ith category.
In practice M1 and M6 tend to be highly correlated which militates against their combined used.
Related indices
The sum
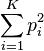
has also found application. This is known as the Simpson index in ecology and as the Herfindahl index or the Herfindahl-Hirschman index (HHI) in economics. A variant of this is known as the Hunter–Gaston index in microbiology[8]
In linguistics and cryptanalysis this sum is known as the repeat rate. The incidence of coincidence (IC) is an unbiased estimator of this statistic[9]
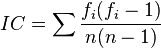
where fi is the count of the ith grapheme in the text and n is the total number of graphemes in the text.
- M1
The M1 statistic defined above has been proposed several times in a number of different settings under a variety of names. These include Gini's index of mutability,[10] Simpson's measure of diversity,[11] Bachi's index of linguistic homogeneity,[12] Mueller and Schuessler's index of qualitative variation,[13] Gibbs and Martin's index of industry diversification,[14] Lieberson's index.[15] and Blau's index in sociology, psychology and management studies.[16] The formulation of all these indices are identical.
Simpson's D is defined as
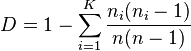
where n is the total sample size and ni is the number of items in the ith category.
For large n we have
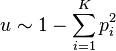
Another statistic that has been proposed is the coefficient of unalikeability which ranges between 0 and 1.[17]
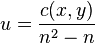
where n is the sample size and c(x,y) = 1 if x and y are alike and 0 otherwise.
For large n we have
where K is the number of categories.
Another related statistic is the quadratic entropy
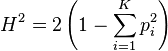
which is itself related to the Gini index.
- M2
Greenberg's monolingual non weighted index of linguistic diversity[18] is the M2 statistic defined above.
- M7
Another index – the M7 – was created based on the M4 index of Gibbs et al.[19]
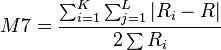
where
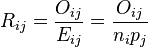
and
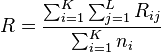
where K is the number of categories, L is the number of subtypes, Oij and Eij are the number observed and expected respectively of subtype j in the ith category, ni is the number in the ith category and pj is the proportion of subtype j in the complete sample.
Note: This index was designed to measure women's participation in the work place: the two subtypes it was developed for were male and female.
Other single sample indices
These indices are summary statistics of the variation within the sample.
Berger–Parker index
The Berger–Parker index equals the maximum 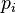 value in the dataset, i.e. the proportional abundance of the most abundant type.[20] This corresponds to the weighted generalized mean of the values when q approaches infinity, and hence equals the inverse of true diversity of order infinity (1/∞D).
value in the dataset, i.e. the proportional abundance of the most abundant type.[20] This corresponds to the weighted generalized mean of the values when q approaches infinity, and hence equals the inverse of true diversity of order infinity (1/∞D).
Brillouin index of diversity
This index is strictly applicable only to entire populations rather than to finite samples. It is defined as
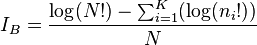
where N is total number of individuals in the population, ni is the number of individuals in the ith category and N! is the factorial of N. Brillouin's index of evenness is defined as
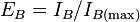
where IB(max) is the maximum value of IB.
Hill's diversity numbers
Hill suggested a family of diversity numbers[21]
![N_a = \frac{1}{ \left[ \sum_{ i = 1 }^K p_i^a \right]^{ a - 1 } }](../I/m/eeabe838bf2c2013cf83187dcb6d5b29.png)
For given values of a several of the other indices can be computed
- a = 0: Na = species richness
- a = 1: Na = Shannon's index
- a = 2: Na = 1/Simpson's index (without the small sample correction)
- a = 3: Na = 1/Berger–Parker index
Hill also suggested a family of evenness measures
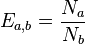
where a > b.
Hill's E4 is
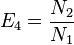
Hill's E5 is
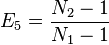
Margalef's index
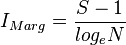
where S is the number of data types in the sample and N is the total size of the sample.[22]
Menhinick's index
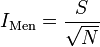
where S is the number of data types in the sample and N is the total size of the sample.[23]
In linguistics this index is the identical with the Kuraszkiewicz index (Guiard index) where S is the number of distinct words (types) and N is the total number of words (tokens) in the text being examined.[24][25] This index can be derived as a special case of the Generalised Torquist function.[26]
Q statistic
This is a statistic invented by Kempton and Taylor.[27] and involves the quartiles of the sample. It is defined as
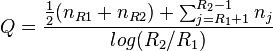
where R1 and R1 are the 25% and 75% quartiles respectively on the cumulative species curve, nj is the number of species in the jth category, nRi is the number of species in the class where Ri falls (i = 1 or 2).
Shannon–Wiener index
This is taken from information theory
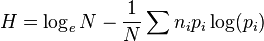
where N is the total number in the sample and pi is the proportion in the ith category.
In ecology where this index is commonly used, H usually lies between 1.5 and 3.5 and only rarely exceeds 4.0.
An approximate formula for the standard deviation (SD) of H is
![SD( H ) = \frac{ 1 }{ N } \left[ \sum p_i [ \log_e( p_i ) ]^2 - H^2 \right]](../I/m/4b1b0e3c74d2c22bc9a357f80cb481e2.png)
where pi is the proportion made up by the ith category and N is the total in the sample.
A more accurate approximate value of the variance of H(var(H)) is given by[28]
![\operatorname{var}( H ) = \frac{ \sum p_i [ \log( p_i ) ]^2 - \left[ \sum p_i \log( p_i ) \right]^2 } { N } + \frac{ K - 1 }{ 2N^2 } + \frac{ -1 + \sum p_i^2 - \sum p_i^{ -1 } \log( p_i ) + \sum p_i^{ -1 }\sum p_i \log( p_i ) }{ 6N^3 }](../I/m/1f745cac1dae1eb7ffa5b494b5d90d45.png)
where N is the sample size and K is the number of categories.
A related index is the Pielou J defined as
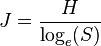
One difficulty with this index is that S is unknown for a finite sample. In practice S is usually set to the maximum present in any category in the sample.
Rényi entropy
The Rényi entropy is a generalization of the Shannon entropy to other values of q than unity. It can be expressed:
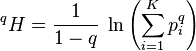
which equals
![{}^qH = \ln\left ( { 1 \over \sqrt[ q - 1 ]{{ \sum_{ i = 1 }^K p_i p_i^{ q - 1 } } } } \right ) = \ln( {}^q\!D )](../I/m/d462518badecf6a95231603aad03df26.png)
This means that taking the logarithm of true diversity based on any value of q gives the Rényi entropy corresponding to the same value of q.
The value of 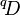 is also known as the Hill number.[21]
is also known as the Hill number.[21]
McIntosh's D and E
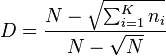
where N is the total sample size and ni is the number in the ith category.
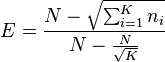
where K is the number of categories.
Fisher's alpha
This was the first index to be derived for diversity.[29]
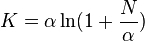
where K is the number of categories and N is the number of data points in the sample. Fisher's α has to be estimated numerically from the data.
The expected number of individuals in the rth category where the categories have been placed in increasing size is
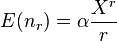
where X is an empirical parameter lying between 0 and 1. While X is best estimated numerically an approximate value can be obtained by solving the following two equations
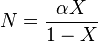
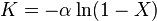
where K is the number of categories and N is the total sample size.
The variance of α is approximately[30]
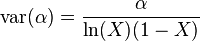
Strong's index
This index (Dw) is the distance between the Lorenz curve of species distribution and the 45 degree line. It is closely related to the Gini coefficient.[31]
In symbols it is
![D_w = max[ \frac{ c_i }{ K } - \frac{ i }{ N } ]](../I/m/fb6c26d68bf0d67000e6d1abd6cd1ec8.png)
where max() is the maximum value taken over the N data points, K is the number of categories (or species) in the data set and ci is the cumulative total up and including the ith category.
Simpson's E
This is related to Simpson's D and is defined as
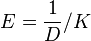
where D is Simpson's D and K is the number of categories in the sample.
Smith & Wilson's indices
Smith and Wilson suggested a number of indices based on Simpson's D.
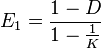
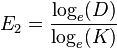
where D is Simpson's D and K is the number of categories.
Heip's index
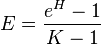
where H is the Shannon entropy and K is the number of categories.
This index is closely related to Sheldon's index which is
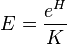
where H is the Shannon entropy and K is the number of categories.
Camargo's index
This index was created by Camargo in 1993.[32]
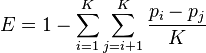
where K is the number of categories and pi is the proportion in the ith category.
Smith & Wilson's B
This index was proposed by Smith and Wilson in 1996.[33]
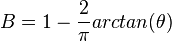
where θ is the slope of the log(abundance)-rank curve.
Nee, Harvey and Cotgreave's index
This is the slope of the log(abundance)-rank curve.
Bulla's E
There are two versions of this index - one for continuous distributions (Ec) and the other for discrete (Ed).[34]
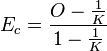
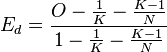
where
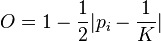
is the Schoener-Czekanoski index, K is the number of categories and N is the sample size.
Horn's information theory index
This index (Rik) is based on Shannon's entropy.[35] It is defined as
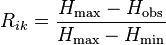
where
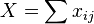
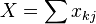
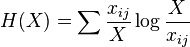
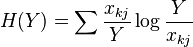
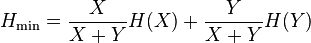
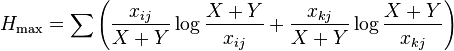
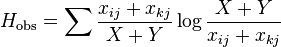
In these equations xij and xkj are the number of times the jth data type appears in the ith or kth sample respectively.
Rarefaction index
In a rarefied sample a random subsample n in chosen from the total N items. In this sample some groups may be necessarily absent from this subsample. Let 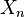 be the number of groups still present in the subsample of n items. is less than K the number of categories whenever at least one group is missing from this subsample.
be the number of groups still present in the subsample of n items. is less than K the number of categories whenever at least one group is missing from this subsample.
The rarefaction curve, 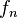 is defined as:
is defined as:
![f_n = E[ X_n ] = K - \binom{ N }{ n }^{ -1 } \sum_{ i = 1 }^K \binom{ N - N_i }{ n }](../I/m/687cafecd6f5ec6f008d595f6c70b000.png)
Note that 0 ≤ f(n) ≤ K.
Furthermore
-
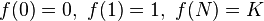 .
.
Despite being defined at discrete values of n, these curves are most frequently displayed as continuous functions.[36]
This index is discussed further in Rarefaction (ecology).
Caswell's V
This is a z type statistic based on Shannon's entropy.[37]
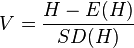
where H is the Shannon entropy, E(H) is the expected Shannon entropy for a neutral model of distribution and SD(H) is the standard deviation of the entropy. The standard deviation is estimated from the formula derived by Pielou
where pi is the proportion made up by the ith category and N is the total in the sample.
Lloyd & Ghelardi's index
This is
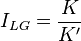
where K is the number of categories and K' is the number of categories according to MacArthur's broken stick model yielding the observed diversity.
Average taxonomic distinctness index
This index is used to compare the relationship between hosts and their parasites.[38] It incorporates information about the phylogenetic relationship amongst the host species.
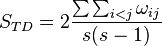
where s is the number of host species used by a parasite and ωij is the taxonomic distinctness between host species i and j.
Indices for comparison of two or more data types within a single sample
Several of these indexes have been developed to document the degree to which different data types of interest may coexist within a geographic area.
Index of dissimilarity
Let A and B be two types of data item. Then the index of dissimilarity is
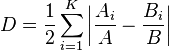
where
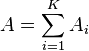
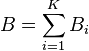
Ai is the number of data type A at sample site i, Bi is the number of data type B at sample site i, K is the number of sites sampled and || is the absolute value.
This index is probably better known as the index of dissimilarity (D).[39] It is closely related to the Gini index.
This index is biased as its expectation under a uniform distribution is > 0.
A modification of this index has been proposed by Gorard and Taylor.[40] Their index (GT) is
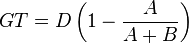
Index of segregation
The index of segregation (IS)[41] is
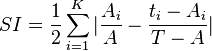
where
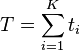
and K is the number of units, Ai and ti is the number of data type A in unit i and the total number of all data types in unit i.
Hutchen's square root index
This index (H) is defined as[42]
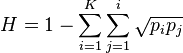
where pi is the proportion of the sample composed of the ith variate.
Lieberson's isolation index
This index ( Lxy ) was invented by Lieberson in 1981.[43]
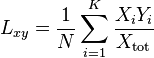
where Xi and Yi are the variables of interest at the ith site, K is the number of sites examined and Xtot is the total number of variate of type X in the study.
Bell's index
This index is defined as[44]
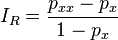
where px is the proportion of the sample made up of variates of type X and
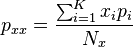
where Nx is the total number of variates of type X in the study, K is the number of samples in the study and xi and pi are the number of variates and the proportion of variates of type X respectively in the ith sample.
Index of isolation
The index of isolation is
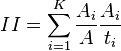
where K is the number of units in the study, Ai and ti is the number of units of type A and the number of all units in ith sample.
A modified index of isolation has also been proposed
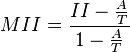
The MII lies between 0 and 1.
Gorard's index of segregation
This index (GS) is defined as
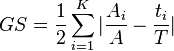
where
and Ai and ti are the number of data items of type A and the total number of items in the ith sample.
Index of exposure
This index is defined as
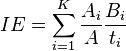
where
and Ai and Bi are the number of types A and B in the ith category and ti is the total number of data points in the ith category.
Indices for comparison between two or more samples
Czekanowski's quantitative index
This is also known as the Bray–Curtis index, Schoener's index, least common percentage index, index of affinity or proportional similarity. It is related to the Sørensen similarity index.
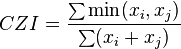
where xi and xj are the number of species in sites i and j respectively and the minimum is taken over the number of species in common between the two sites.
Canberra metric
The Canberra distance is a weighted version of the L1 metric. It was introduced by introduced in 1966[45] and refined in 1967[46] by G. N. Lance and W. T. Williams. It is used to defined a distance bwteen two vectors - here two sites with K categories within each site.
The Canberra distance d between vectors p and q in an K-dimensional real vector space is
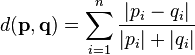
where pi and qi are the values of the ith category of the two vectors.
Sorensen's coefficient of community
This is used to measure similarities between communities.
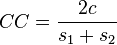
where s1 and s2 are the number of species in community 1 and 2 and c is the number of species common to both areas.
Jaccard's index
This is a measure of the similarity between two samples:
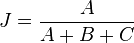
where A is the number of data points shared between the two samples and B and C are the data points found only in the first and second samples respectively.
Dice's index
This is a measure of the similarity between two samples:
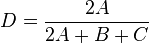
where A is the number of data points shared between the two samples and B and C are the data points found only in the first and second samples respectively.
Match coefficient
This is a measure of the similarity between two samples:
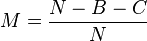
where N is the number of data points in the two samples and B and C are the data points found only in the first and second samples respectively.
Morisita's index
Morisita’s index of dispersion ( Im ) is the scaled probability that two points chosen at random from the whole population are in the same sample.[47] Higher values indicate a more clumped distribution.
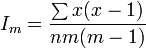
An alternative formulation is
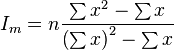
where n is the total sample size, m is the sample mean and x are the individual values with the sum taken over the whole sample. It is also equal to
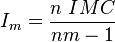
where IMC is Lloyd's index of crowding.[48]
This index is relatively independent of the population density but is affected by the sample size.
Morisita showed that the statistic[47]
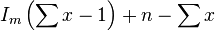
is distributed as a chi-squared variable with n − 1 degrees of freedom.
A alternative significance test for this index has been developed for large samples.[49]
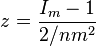
where m is the overall sample mean, n is the number of sample units and z is the normal distribution abscissa. Significance is tested by comparing the value of z against the values of the normal distribution.
Standardised Morisita’s index
Smith-Gill developed a statistic based on Morisita’s index which is independent of both sample size and population density and bounded by −1 and +1. This statistic is calculated as follows[50]
First determine Morisita's index ( Id ) in the usual fashion. Then let k be the number of units the population was sampled from. Calculate the two critical values
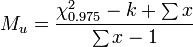
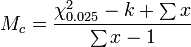
where χ2 is the chi square value for n − 1 degrees of freedom at the 97.5% and 2.5% levels of confidence.
The standardised index ( Ip ) is then calculated from one of the formulae below
When Id ≥ Mc > 1
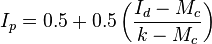
When Mc > Id ≥ 1
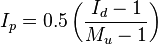
When 1 > Id ≥ Mu
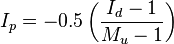
When 1 > Mu > Id
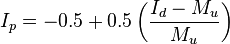
Ip ranges between +1 and −1 with 95% confidence intervals of ±0.5. Ip has the value of 0 if the pattern is random; if the pattern is uniform, Ip < 0 and if the pattern shows aggregation, Ip > 0.
Peet's evenness indices
These indices are a measure of evenness between samples.[51]
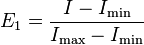
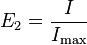
where I is an index of diversity, Imax and Imin are the maximum and minimum values of I between the samples being compared.
Euclidean distance
While this is usually used in quantitative work it may also be used in qualitative work. This is defined as
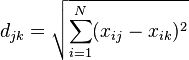
where djk is the distance between xij and xik.
Manhattan distance
While this is more commonly used in quantitative work it may also be used in qualitative work. This is defined as
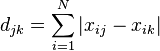
where djk is the distance between xij and xik and || is the absolute value of the difference between xij and xik.
Prevosti’s distance
This is related to the Manhatten distance. It was described by Prevosti et al and was used to compare differences between chromosomes.[52] Let P and Q be two collections of r finite probability distributions. Let these distributions have values that are divided into k catagories. Then the distance DPQ is
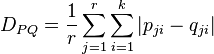
where r is the number of discrete probability distributions in each population, kj is the number of categories in distributions Pj and Qj and pji (respectively qji) is the theoretical probability of category i in distribution Pj (Qj) in population P(Q).
Its statistical properties were examined by Sanchez et al[53] who recommended a bootstrap procedure to estimate confidence intervals when testing for differences between samples.
Other metrics
Let
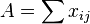
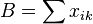
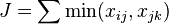
where min(x,y) is the lesser value of the pair x and y.
Then
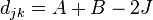
is the Manhattan distance,
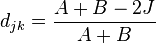
is the Bray−Curtis distance,
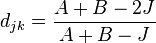
is the Jaccard (or Ruzicka) distance and
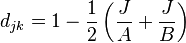
is the Kulczynski distance.
Ordinal data
If the categories are at least ordinal then a number of other indices may be computed.
Leik's D
Leik's measure of dispersion (D) is one such index.[54] Let there be K categories and let pi be fi/N where fi is the number in the ith category and let the categories be arranged in ascending order. Let
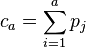
where a ≤ K. Let da = ca if ca ≤ 0.5 and 1 − ca ≤ 0.5 otherwise. Then
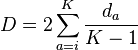
Normalised Herfindahl measure
This is the square of the coefficient of variation divided by N - 1 where N is the sample size.
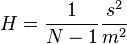
where m is the mean and s is the standard deviation.
Potential for Conflict Index
The Potential for Conflict Index (PCI) describes the ratio of scoring on either side of a rating scale’s centre point.[55] This index requires at least ordinal data. This ratio is often be displayed as a bubble graph.
The PCI uses an ordinal scale with an odd number of rating points (−n to +n) centred at 0. It is calculated as follows
![PCI = \frac{ X_t }{ Z } \left[ 1 - \left| \frac{ \sum_{ i = 1 }^{ r_+ } X_+ }{ X_t } - \frac{ \sum _{ i = 1 }^{ r_- } X_-} { X_t } \right| \right]](../I/m/aef23e4ec91810189b6b189e96124ee5.png)
where Z = 2n, || is the absolute value (modulus), r+ is the number of responses in the positive side of the scale, r- is the number of responses in the negative side of the scale, X+ are the responses on the positive side of the scale, X- are the responses on the negative side of the scale and
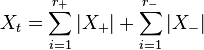
Theoretical difficulties are known to exist with the PCI. The PCI can be computed only for scales with a neutral center point and an equal number of response options on either side of it. Also a uniform distribution of responses does not always yield the midpoint of the PCI statistic but rather varies with the number of possible responses or values in the scale. For example, five-, seven- and nine-point scales with a uniform distribution of responses give PCIs of 0.60, 0.57 and 0.50 respectively.
The first of these problems is relatively minor as most ordinal scales with an even number of response can be extended (or reduced) by a single value to give an odd number of possible responses. Scale can usually be recentred if this is required. The second problem is more difficult to resolve and may limit the PCI's applicability.
The PCI has been extended[56]
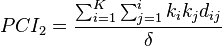
where K is the number of categories, ki is the number in the ith category, dij is the distance between the ith and ith categories, and δ is the maximum distance on the scale multiplied by the number of times it can occur in the sample. For a sample with an even number of data points
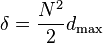
and for a sample with an odd number of data points
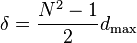
where N is the number of data points in the sample and dmax is the maximum distance between points on the scale.
Vaske et al suggest a number of possible distance measures for use with this index.[56]
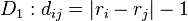
if the signs (+ or −) of ri and rj differ. If the signs are the same dij = 0.
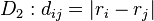
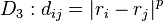
where p is an arbitrary real number > 0.
![Dp_{ ij }: d_{ ij } = [ | r_i - r_j | - ( m - 1 ) ]^p](../I/m/b5ecd068188b6d24582a0819580d1948.png)
if sign(ri ) ≠ sign(ri ) and p is a real number > 0. If the signs are the same then dij = 0. m is D1, D2 or D3.
The difference between D1 and D2 is that the first does not include neutrals in the distance while the latter does. For example respondents scoring −2 and +1 would have a distance of 2 under D1 and 3 under D2.
The use of a power (p) in the distances allows for the rescaling of extreme responses. These differences can be highlighted with p > 1 or diminished with p < 1.
In simulations with a variates drawn from a uniform distribution the PCI2 has a symmetric unimodal distribution.[56] The tails of its distribution are larger than those of a normal distribution.
Vaske et al suggest the use of a t test to compare the values of the PCI between samples if the PCIs are approximately normally distributed.
van der Eijk's A
This measure is a weighted average of the degree of agreement the frequency distribution.[57] A ranges from −1 (perfect bimodality) to +1 (perfect unimodality). It is defined as
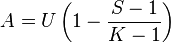
where U is the unimodality of the distribution, S the number of categories that have nonzero frequencies and K the total number of categories.
The value of U is 1 if the distribution has any of the three following characteristics:
- all responses are in a single category
- the responses are evenly distributed among all the categories
- the responses are evenly distributed among two or more contiguous categories, with the other categories with zero responses
With distributions other than these the data must be divided into 'layers'. Within a layer the responses are either equal or zero. The categories do not have to be contiguous. A value for A for each layer (Ai) is calculated and a weighted average for the distribution is determined. The weights (wi) for each layer are the number of responses in that layer. In symbols
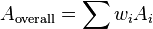
A uniform distribution has A = 0: when all the responses fall into one category A = +1.
One theoretical problem with this index is that it assumes that the intervals are equally spaced. This may limit its applicability.
Related statistics
Birthday problem
If there are n units in the sample and they are randomly distributed into k categories (n ≤ k), this can be considerer a variant of the birthday problem.[58] The probability (p) of all the categories having only one unit is
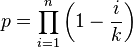
If c is large and n is small compared with c2/3 then to a good approximation
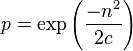
This approximation follows from the exact formula as follows:
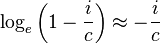
- Sample size estimates
For p = 0.5 and p = 0.05 respectively the following estimates of n may be useful
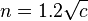
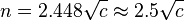
This analysis can be extended to multiple categories. For p = 0.5 and p 0.05 we have respectively
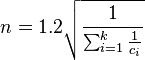
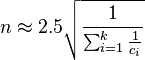
where ci is the size of the ith category. This analysis assumes that the categories are independent.
If the data is ordered in some fashion then for at least one event occurring in two categories lying within j categories of each other than a probability of 0.5 or 0.05 requires a sample size (n) respectively of<ref name=Sevast'yanov1972>Sevast'yanov BA (1972) Poisson limit law for a scheme of sums of dependent random variables. (trans. S. M. Rudolfer) Theory of probability and its applications, 17: 695−699</ref>
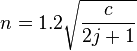
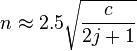
where c is the number of categories.
Birthday-death day problem
Whether or not there is a relation between birthdays and death days has been investigated with the following statistic[59]
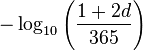
where d is the number of days in the year between the birthday and the death day.
Evaluation of indices
Different indices give different values of variation, and may be used for different purposes: several are used and critiqued in the sociology literature especially.
If one wishes to simply make ordinal comparisons between samples (is one sample more or less varied than another), the choice of IQV is relatively less important, as they will often give the same ordering.
Where the data is ordinal a method that may be of use in comparing samples is ORDANOVA.
In some cases it is useful to not standardize an index to run from 0 to 1, regardless of number of categories or samples (Wilcox 1973, pp. 338), but one generally so standardizes it.
See also
- Categorical data
- Diversity index
- Information entropy
- Logarithmic distribution
- Statistical dispersion
- Variation ratio
- Whipple's index
Notes
- ↑ This can only happen if the number of cases is a multiple of the number of categories.
- ↑ Freemen LC (1965) Elementary applied statistics. New York: John Wiley and Sons pp 40–43
- ↑ Kendal MC, Stuart A (1958) The advanced theory of statistics. Hafner Publishing Company p46
- ↑ Mueller JE, Schuessler KP (1961) Statistical reasoning in sociology. Boston: Houghton Mifflin Company. pp 177–179
- ↑ Wilcox AR (1967) Indices of qualitative variation
- ↑ Gibbs JP, Poston Jr, Dudley L (1975) The division of labor: Conceptualization and related measures. Social Forces 53 (3) 468–476 doi:10.2307/2576589
- ↑ IQV at xycoon
- ↑ Hunter PR, Gaston MA (1988) Numerical index of the discriminatory ability of typing systems: an application of Simpson's index of diversity. J Clin Microbiol 26(11): 2465–2466
- ↑ Friedman WF (1925) The incidence of coincidence and its applications in cryptanalysis. Technical Paper. Office of the Chief Signal Officer. United States Government Printing Office.
- ↑ Gini CW (1912) Variability and mutability, contribution to the study of statistical distributions and relations. Studi Economico-Giuricici della R. Universita de Cagliari
- ↑ Simpson EH (1949) Measurement of diversity. Nature 163:688
- ↑ Bachi R (1956) A statistical analysis of the revival of Hebrew in Israel. In: Bachi R (ed) Scripta Hierosolymitana, Vol III, Jerusalem: Magnus press pp 179–247
- ↑ Mueller JH, Schuessler KF (1961) Statistical reasoning in sociology. Boston: Houghton Mifflin
- ↑ Gibbs JP, Martin, WT (1962) Urbanization, technology and division of labor: International patterns. American Sociological Review 27: 667–677
- ↑ Lieberson S (1969) Measuring population diversity. American Sociological Review 34(6) 850–862
- ↑ Blau P (1977) Inequality and Heterogeneity. Free Press, New York
- ↑ Perry M, Kader G (2005) Variation as unalikeability. Teaching Stats 27 (2) 58–60
- ↑ Greenberg JH (1956) The measurement of linguistic diversity. Language 32: 109–115
- ↑ Lautard EH (1978) PhD thesis
- ↑ Berger WH, Parker FL (1970) Diversity of planktonic Foramenifera in deep sea sediments. Science 168:1345–1347
- ↑ 21.0 21.1 Hill, M O. 1973. Diversity and evenness: a unifying notation and its consequences. Ecology 54:427–431
- ↑ Margalef R (1958) Temporal succession and spatial heterogeneity in phytoplankton. In: Perspectives in marine biology. Buzzati-Traverso (ed) Univ Calif Press, Berkeley pp 323–347
- ↑ Menhinick EF (1964) A comparison of some species-individuals diversity indices applied to samples of field insects. Ecology 45 (4) 859–861
- ↑ Kuraszkiewicz W (1951) Nakladen Wroclawskiego Towarzystwa Naukowego
- ↑ Guiraud P (1954) Les caractères statistiques du vocabulaire. Presses Universitaires de France, Paris
- ↑ Panas E (2001) The Generalized Torquist: Specification and estimation of a new vocabulary-text size function. J Quant Ling 8(3) 233–252
- ↑ Kempton RA, Taylor LR (1976) Models and statistics for species diversity. Nature 262: 818–820
- ↑ Hutcheson K (1970) A test for comparing diversities based on the Shannon formula. J Theo Biol 29: 151–154
- ↑ Fisher RA, Corbet A, Williams CB (1943) The relation between the number of species and the number of individuals in a random sample of an animal population. Animal Ecol 12: 42–58
- ↑ Anscombe (1950) Sampling theory of the negative binomial and logarithmic series distributions. Biometrika 37: 358–382
- ↑ Strong WL (2002) Assessing species abundance uneveness within and between plant communities. Community Ecology 3: 237–246
- ↑ Camargo JA (1993) Must dominance increase with the number of subordinate species in competitive interactions? J. Theor Biol 161 537–542
- ↑ Smith, Wilson (1996)
- ↑ Bulla L (1994) An index of evenness and its associated diversity measure. Oikos 70:167–171
- ↑ Horn HS (1966) Measurement of 'overlap' in comparative ecological studies. Am Nat 100 (914): 419–423
- ↑ Siegel, Andrew F (2006) Rarefaction curves. Encyclopedia of Statistical Sciences 10.1002/0471667196.ess2195.pub2.
- ↑ Caswell H (1976) Community structure: a neutral model analysis. Ecol Monogr 46: 327–354
- ↑ Poulin R, Mouillot D (2003) Parasite specialization from a phylogenetic perspective: a new index of host specificity. Parasitology 126: 473–480
- ↑ Duncan OD, Duncan B (1955) A methodological analysis of segregation indexes. Am Sociol Review, 20: 210–217
- ↑ Gorard S, Taylor C (2002b) What is segregation? A comparison of measures in terms of 'strong' and 'weak' compositional invariance. Sociology, 36(4), 875–895
- ↑ Massey DS, Denton NA (1988) The dimensions of residential segregation. Social Forces 67: 281–315
- ↑ Hutchens RM (2004) One measure of segregation. International Economic Review 45: 555–578
- ↑ Lieberson S (1981) An asymmetrical approach to segregation. In: Peach C, Robinson V, Smith S (ed.s) Ethnic segregation in cities. London: Croom Helmp. 61–82
- ↑ Bell W (1954) A probability model for the measurement of ecological segregation. Social Forces 32:357–364
- ↑ Lance, G. N.; Williams, W. T. (1966). "Computer programs for hierarchical polythetic classification ("similarity analysis").". Computer Journal 9 (1): 60–64. doi:10.1093/comjnl/9.1.60.
- ↑ Lance, G. N.; Williams, W. T. (1967). "Mixed-data classificatory programs I.) Agglomerative Systems". Australian Computer Journal: 15–20.
- ↑ 47.0 47.1 Morisita M (1959) Measuring the dispersion and the analysis of distribution patterns. Memoires of the Faculty of Science, Kyushu University Series E. Biol 2:215–235
- ↑ Lloyd M (1967) Mean crowding. J Anim Ecol 36: 1–30
- ↑ Pedigo LP & Buntin GD (1994) Handbook of sampling methods for arthropods in agriculture. CRC Boca Raton FL
- ↑ Smith-Gill S J (1975) Cytophysiological basis of disruptive pigmentary patterns in the leopard frog Rana pipiens. II. Wild type and mutant cell specific patterns. J Morphol 146, 35–54
- ↑ Peet (1974) The measurements of species diversity. Ann Rev Ecol System 5: 285–307
- ↑ Prevosti A, Ribo, G, Serra L, Aguade M, Balanya J, Monclus M, Mestres F (1988) Colonization of America by Drosophila subobscura: experiment in natural populations that supports the adaptive role of chromosomal inversion polymorphism. Proc Natl Acad Sci USA 85: 5597–5600
- ↑ Sanchez A, Ocana J, Utzetb F, Serrac L (2003) Comparison of Prevosti genetic distances. Journal of Statistical Planning and Inference 109 (2003) 43–65
- ↑ Leik R (1966) A measure of ordinal consensus. Pacific sociological review 9 (2): 85–90
- ↑ Manfredo M, Vaske, JJ, Teel TL (2003) The potential for conflict index: A graphic approach tp practical significance of human dimensions research. Human Dimensions of Wildlife 8: 219–228
- ↑ 56.0 56.1 56.2 Vaske JJ, Beaman J, Barreto H, Shelby LB (2010) An extension and further validation of the potential for conflict index. Leisure Sciences 32: 240–254
- ↑ Van der Eijk C (2001) Measuring agreement in ordered rating scales. Quality and quantity 35(3): 325–341
- ↑ Von Mises R (1939) Uber Aufteilungs-und Besetzungs-Wahrcheinlichkeiten. Revue de la Facultd des Sciences de de I'Universite d'lstanbul NS 4: 145−163
- ↑ Hoaglin DC, Mosteller, F and Tukey, JW (1985) Exploring data tables, trends, and shapes, New York: John Wiley
References
- Gibbs, Jack P.; Poston, Jr., Dudley L. (March 1975), "The Division of Labor: Conceptualization and Related Measures", Social Forces 53 (3): 468–476, doi:10.2307/2576589, JSTOR 2576589
- Lieberson, Stanley (December 1969), "Measuring Population Diversity", American Sociological Review 34 (6): 850–862, doi:10.2307/2095977, JSTOR 2095977
- Swanson, David A. (September 1976), "A Sampling Distribution and Significance Test for Differences in Qualitative Variation", Social Forces 55 (1): 182–184, doi:10.2307/2577102, JSTOR 2577102
- Wilcox, Allen R. (1967), Indices of qualitative variation (PDF)
- Wilcox, Allen R. (June 1973), "Indices of Qualitative Variation and Political Measurement", The Western Political Quarterly 26 (2): 325–343, doi:10.2307/446831, JSTOR 446831