Potentially all pairwise rankings of all possible alternatives
Potentially all pairwise rankings of all possible alternatives (PAPRIKA) is a method for multi-criteria decision making (MCDM) or conjoint analysis based on decision-makers’ preferences as expressed using pairwise rankings of alternatives.[1][2]
The PAPRIKA method – implemented via decision-making software known as 1000Minds – is used to calculate point values (or ‘weights’) on the criteria or attributes for decision problems involving ranking, prioritising or choosing between alternatives. Point values represent the relative importance of the criteria or attributes to decision-makers.
As well as representing decision-makers’ preferences, the point values are used to rank alternatives – enabling decision-makers to prioritise or choose between them (perhaps subject to a budget constraint). Examples of applications of the PAPRIKA method appear in the next section.
Applications
Applications of the PAPRIKA method in the area of health care decision-making include:
- Prioritising patients for access to elective (non-urgent) surgery in New Zealand and Canada[3][4]
- Referring patients for rheumatology, nephrology, geriatrics and gastroenterology services in Canada[5][6][7]
- Classifying individuals by their risks of suffering from rheumatoid arthritis[8]
- Developing diagnostic criteria for systemic sclerosis[9][10][11]
- Health technology prioritisation[12][13]
- Measuring patient responses in clinical trials for chronic gout[14][15]
- Deriving tests of physical function for patients following hip or knee replacement[16]
- Developing key educational messages for people with osteoarthritis[17]
Applications in other areas include:
- Corporate strategic management[18]
- Revealing central bankers’ monetary-policy preferences with respect to tradeoffs between inflation and GDP volatility, interest rates and exchange rates[19]
- Discovering agronomists’ preferred grass breeding traits for pasture plant species in Australia[20][21]
- Characterising the ‘ideal’ sheep to breed in terms of traits preferred by sheep farmers in Ireland[22]
- Incorporating climate change and mitigation information into environmental resources management for the ocean[23]
- Revealing the public's preferences over competing uses of near-shore marine areas, including marine protected areas[24]
- Selecting endangered plant species for conservation restoration[25]
- Creating a framework for ethical ecology research[26]
- Evaluating decision-making software[27]
- Helping people choose energy-efficiency improvements for their homes[28]
- Researching what matters to people when donating money to countries in need of aid[29]
Additive multi-attribute value models (or ‘points systems’)
The PAPRIKA method specifically applies to additive multi-attribute value models with performance categories[30] – also known as ‘points’, ‘scoring’, ‘point-count’ or ‘linear’ systems or models.
As the name implies, additive multi-attribute value models with performance categories – hereinafter referred to simply as ‘value models’ – consist of multiple criteria (or ‘attributes’), with two or more performance categories (or ‘levels’) within each criterion, that are combined additively. Each category is worth a certain number of points that is intended to reflect both the relative importance (‘weight’) of the criterion and its degree of achievement. For each alternative being considered, the point values are summed across the criteria to get a total score (thus these are additive value models), by which the alternatives are prioritised or ranked (or otherwise classified) relative to each other.
Thus, a value model (or ‘points system’) is simply a schedule of criteria and point values (for an example, see Table 1 in the sub-section below) for the decision problem at hand. This representation is equivalent to the more traditional approach involving normalised criterion weights and ‘single-criterion value functions’ to represent the relative importance of the criteria and to combine values overall (see weighted sum model). The unweighted points system representation is easier to use and helps inform the explanation of the PAPRIKA method below.
An example of an unweighted points system
One example application for an unweighted points system is ranking candidates applying for a job.
Imagine that ‘Tom’, ‘Dick’ and ‘Harry’ are three candidates and that they are to be ranked with respect to their overall suitability for the job using the value model in Table 1 below. Suppose that after being assessed they are scored on the five criteria (see Table 1) like this:
- Tom’s education is excellent, he has > 5 years of experience, but his references, social skills and enthusiasm are all poor.
- Dick’s education is poor, he has 2 - 5 years of experience, and his references, social skills and enthusiasm are all good.
- Harry’s education is good, he has < 2 years of experience, and his references, social skills and enthusiasm are all good.
Table 1: Example of a value model (points system) for ranking job candidates
| Criterion | Category | Points |
|---|---|---|
| Education | poor | 0 |
| good | 8 | |
| very good | 20 | |
| excellent | 40 | |
| Experience | < 2 years | 0 |
| 2 – 5 years | 3 | |
| > 5 years | 10 | |
| References | poor | 0 |
| good | 27 | |
| Social skills | poor | 0 |
| good | 10 | |
| Enthusiasm | poor | 0 |
| good | 13 | |
Summing the point values in Table 1 corresponding to the descriptions for Tom, Dick and Harry gives their total scores:
- Tom’s total score = 40 + 10 + 0 + 0 + 0 = 50 points
- Dick’s total score = 0 + 3 + 27 + 10 + 13 = 53 points
- Harry’s total score = 8 + 0 + 27 + 10 + 13 = 58 points
Clearly, Harry has the highest total score. Therefore, according to the value model (and how the candidates were assessed) he is the best of the three candidates. (Though, clearly, relative to other candidates who could potentially have applied for the job, Harry is not as good as the best hypothetically-possible candidate – who would score a ‘perfect’ 40 + 10 + 27 + 10 + 13 = 100 points.)
In general terms, having specified the criteria and categories for a given value model, the challenge is to derive point values that accurately reflect the relative importance of the criteria and categories to the decision-maker. Deriving valid and reliable point values is arguably the most difficult task when creating a value model. The PAPRIKA method does this based on decision-makers’ preferences as expressed using pairwise rankings of alternatives.
Overview of the PAPRIKA method
As mentioned at the start of the article, PAPRIKA is a (partial) acronym for ‘Potentially All Pairwise RanKings of all possible Alternatives’.
The PAPRIKA method pertains both to value models for ranking particular alternatives that are known to decision-makers (e.g. as in the job candidates example above) and to models for ranking potentially all hypothetically possible alternatives in a pool that is changing over time (e.g. patients presenting for medical care). The following explanation is centred on this second type of application because it is more general.
PAPRIKA is based on the fundamental principle that an overall ranking of all possible alternatives representable by a given value model – i.e. all possible combinations of the categories on the criteria – is defined when all pairwise rankings of the alternatives vis-à-vis each other are known (provided the rankings are consistent).
(As an analogy, suppose you wanted to rank all competitors at the next Olympic Games from the youngest to the oldest. If you knew how each person was pairwise ranked relative to everyone else with respect to their ages – i.e. for each possible pair of individuals, you identified who is the younger of the two individuals or that they’re the same age – then you could produce an overall ranking of competitors from the youngest to the oldest.)
However, depending on the number of criteria and categories, the number of pairwise rankings of all possible alternatives is potentially in the millions or even billions. Of course, though, many of these pairwise rankings are automatically resolved due to one alternative in the pair having a higher category for at least one criterion and none lower for the other criteria than for the other alternative – known as ‘dominated pairs’. But this still leaves potentially millions or billions of ‘undominated pairs’ – pairs of alternatives where one has a higher ranked category for at least one criterion and a lower ranked category for at least one other criterion than the other alternative, and hence a judgment is required for the alternatives to be pairwise ranked. With reference to the example of ranking job candidates in the previous section, an example of an undominated pair (of candidates) would be where one person in the pair is, say, highly educated but inexperienced whereas the other person is uneducated but highly experienced, and so a judgement is required to pairwise rank this pair.
If there are n possible alternatives, there are n(n−1)/2 pairwise rankings. For example, for a value model with eight criteria and four categories within each criterion, and hence 48 = 65,536 possible alternatives, there are 65,536 x 65,535 / 2 = 2,147,450,880 pairwise rankings. Even after eliminating the 99,934,464 dominated pairs, there are still 2,047,516,416 undominated pairs to be ranked.[1] Clearly, performing anywhere near this number of pairwise rankings is impossible without a special method.
PAPRIKA solves this problem by ensuring that the number of pairwise rankings that decision-makers need to perform is kept to a minimum – only a small fraction of the potentially millions or billions of undominated pairs – so that the method is practicable. It does this by, for each undominated pair explicitly ranked by decision-makers, identifying (and eliminating) all undominated pairs implicitly ranked as corollaries of this and other explicitly ranked pairs (via the transitivity property of additive value models, as illustrated in the simple demonstration later below).
The method begins with the decision-maker pairwise ranking undominated pairs defined on just two criteria at-a-time (where, in effect, all other criteria’s categories are pairwise identical). Again with reference to the example of ranking job candidates, an example of such a pairwise-ranking question is: “Who would you prefer to hire, someone whose education is poor but he or she has > 5 years of experience or another person whose education is excellent but he or she has < 2 years of experience, all else the same?” (see Figure 1).
Figure 1: Example of a pairwise-ranking question (a screenshot from 1000Minds)
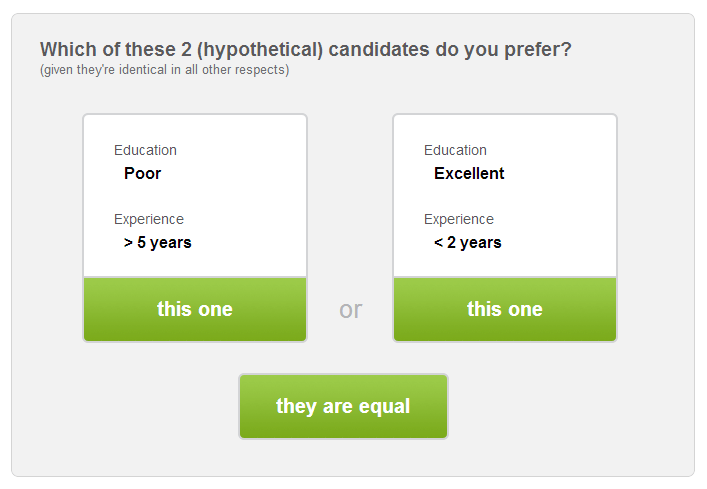
Each time the decision-maker ranks a pair (such as the example above), all undominated pairs implicitly ranked as corollaries are identified and discarded. After having completed ranking undominated pairs defined on just two criteria at-a-time, this is followed, if the decision-maker chooses to continue (she can stop at any time), by pairs with successively more criteria, until potentially all undominated pairs are ranked. Thus, Potentially All Pairwise RanKings of all possible Alternatives (hence the PAPRIKA acronym) are identified: as either dominated pairs (given) or undominated pairs explicitly ranked by the decision-maker or implicitly ranked as corollaries. From the explicitly ranked pairs, point values are obtained via linear programming; although multiple solutions to the linear program are possible, the resulting point values all reproduce the same overall ranking of alternatives.
Simulations of PAPRIKA’s use reveal that if the decision-maker stops after having ranked undominated pairs defined on just two criteria at-a-time, the resulting overall ranking of all possible alternatives is very highly correlated with the decision-maker’s ‘true’ overall ranking obtained if all undominated pairs (involving more than two criteria) were ranked.[1]
Therefore, for most practical purposes decision-makers are unlikely to need to rank pairs defined on more than two criteria, thereby reducing the elicitation burden. For example, approximately 95 pairwise rankings are required for the value model with eight criteria and four categories each referred to above; 25 pairwise rankings for a model with five criteria and three categories each; and so on.[1] The real-world applications of PAPRIKA referred to earlier suggest that decision-makers are able to rank comfortably more than 50 and up to at least 100 pairs, and relatively quickly, and that this is sufficient for most applications.
Theoretical antecedents
The PAPRIKA method’s closest theoretical antecedent is Pairwise Trade-off Analysis,[31] a precursor to Adaptive Conjoint Analysis in marketing research.[32] Like the PAPRIKA method, Pairwise Trade-off Analysis is based on the idea that undominated pairs that are explicitly ranked by the decision-maker can be used to implicitly rank other undominated pairs. Pairwise Trade-off Analysis was abandoned in the late 1970s, however, because it lacked a method for systematically identifying implicitly ranked pairs.
The ZAPROS method (from Russian for ‘Closed Procedure Near References Situations’) was also proposed;[33] however, with respect to pairwise ranking all undominated pairs defined on two criteria “it is not efficient to try to obtain full information”.[34] As explained in the present article, the PAPRIKA method overcomes this efficiency problem.
A simple demonstration of the PAPRIKA method
The PAPRIKA method can be easily demonstrated via the simple example of determining the point values for a value model with just three criteria – denoted by ‘a’, ‘b’ and ‘c’ – and two categories within each criterion – ‘1’ and ‘2’, where 2 is the higher ranked category.[1]
This value model’s six point values (two for each criterion) can be represented by the variables a1, a2, b1, b2, c1, c2 (a2 > a1, b2 > b1, c2 > c1), and the eight possible alternatives (23 = 8) as ordered triples of the categories on the criteria (abc): 222, 221, 212, 122, 211, 121, 112, 111. These eight alternatives and their total score equations – derived by simply adding up the variables corresponding to the point values (which are as yet unknown: to be determined by the method being demonstrated here) – are listed in Table 2.
Undominated pairs are represented as ‘221 vs (versus) 212’ or, in terms of the total score equations, as ‘a2 + b2 + c1 vs a2 + b1 + c2’, etc. [Recall, as explained earlier, an ‘undominated pair’ is a pair of alternatives where one is characterised by a higher ranked category for at least one criterion and a lower ranked category for at least one other criterion than the other alternative, and hence a judgement is required for the alternatives to be pairwise ranked. Conversely, the alternatives in a ‘dominated pair’ (e.g. 121 vs 111 – corresponding to a1 + b2 + c1 vs a1 + b1 + c1) are inherently pairwise ranked due to one having a higher category for at least one criterion and none lower for the other criteria (and no matter what the point values are, given a2 > a1, b2 > b1 and c2 > c1, the pairwise ranking will always be the same).]
‘Scoring’ this model involves determining the values of the six point value variables (a1, a2, b1, b2, c1, c2) so that the decision-maker’s preferred ranking of the eight alternatives is realised.
For many readers, this simple value model can perhaps be made more concrete by considering an example to which most people can probably relate: a model for ranking job candidates consisting of the three criteria (for example) (a) education, (b) experience, and (c) references, each with two ‘performance’ categories, (1) poor or (2) good. (This is a simplified version of the illustrative value model in Table 1 earlier in the article.)
Accordingly, each of this model’s eight possible alternatives can be thought of as being a ‘type’ (or profile) of candidate who might ever, hypothetically, apply. For example, ‘222’ denotes a candidate who is good on all three criteria; ‘221’ is a candidate who is good on education and experience but poor on references; ‘212’ a third who is good on education, poor on experience, and good on references; etc.
Finally, with respect to undominated pairs, 221 vs 212, for example, represents candidate 221 who has good experience and poor references whereas 212 has the opposite characteristics (and they both have good education). Thus, which is the better candidate ultimately depends on the decision-maker’s preferences with respect to the relative importance of experience vis-à-vis references.
Table 2: The eight possible alternatives and their total-score equations
| Alternative | Total-score equation |
|---|---|
| 222 | a2 + b2 + c2 |
| 221 | a2 + b2 + c1 |
| 212 | a2 + b1 + c2 |
| 122 | a1 + b2 + c2 |
| 211 | a2 + b1 + c1 |
| 121 | a1 + b2 + c1 |
| 112 | a1 + b1 + c2 |
| 111 | a1 + b1 + c1 |
Identifying undominated pairs
PAPRIKA’s first step is to identify the undominated pairs. With just eight alternatives this can be done by pairwise comparing all of them vis-à-vis each other and discarding dominated pairs.
This simple approach can be represented by the matrix in Figure 2, where the eight possible alternatives (in bold) are listed down the left-hand side and also along the top. Each alternative on the left-hand side is pairwise compared with each alternative along the top with respect to which of the two alternatives is higher ranked (i.e. in the present example, which candidate is more desirable for the job). The cells with hats (^) denote dominated pairs (where no judgement is required) and the empty cells are either the central diagonal (each alternative pairwise ranked against itself) or the inverse of the non-empty cells containing the undominated pairs (where a judgement is required).
Figure 2: Undominated pairs identified by pairwise comparing the eight possible alternatives (emboldened)
| vs | 222 | 221 | 212 | 122 | 112 | 121 | 211 | 111 |
| 222 | ^ | ^ | ^ | ^ | ^ | ^ | ^ | |
| 221 | (i) b2 + c1 vs b1 + c2 | (ii) a2 + c1 vs a1 + c2 | (iv) a2 + b2 + c1 vs a1 + b1 + c2 | ^ | ^ | ^ | ||
| 212 | (iii) a2 + b1 vs a1 + b2 | ^ | (v) a2 + b1 + c2 vs a1 + b2 + c1 | ^ | ^ | |||
| 122 | ^ | ^ | (vi) a1 + b2 + c2 vs a2 + b1 + c1 | ^ | ||||
| 112 | (*i) b1 + c2 vs b2 + c1 | (*ii) a1 + c2 vs a2 + c1 | ^ | |||||
| 121 | (*iii) a1 + b2 vs a2 + b1 | ^ | ||||||
| 211 | ^ | |||||||
| 111 |
Figure 2 notes: ^ denotes dominated pairs. The undominated pairs are labelled with Roman numerals; the three with asterisks are duplicates of pairs (i)-(iii).
As summarised in Figure 2, there are nine undominated pairs (labelled with Roman numerals). However, three are duplicates after any variables common to a pair are ‘cancelled’ (e.g. pair *i is a duplicate of pair i, etc.). Thus, there are six unique undominated pairs (without asterisks in Figure 2, and listed later below).
The cancellation of variables common to undominated pairs can be illustrated as follows. When comparing alternatives 121 and 112, for example, a1 can be subtracted from both sides of a1 + b2 + c1 vs a1 + b1 + c2. Similarly, when comparing 221 and 212, a2 can be subtracted from both sides of a2 + b2 + c1 vs a2 + b1 + c2. For both pairs this leaves the same ‘cancelled’ form: b2 + c1 vs b1 + c2.
Formally, these subtractions reflect the ‘joint-factor’ independence property of additive value models:[35] the ranking of undominated pairs (in uncancelled form) is independent of their tied rankings on one or more criteria. Notationally, undominated pairs in their cancelled forms, like b2 + c1 vs b1 + c2, are also representable as _21 ‘‘vs’’ _12 – i.e. where ‘_’ signifies identical categories for the identified criterion.
In summary, here are the six undominated pairs for the value model:
- (i) b2 + c1 vs b1 + c2
- (ii) a2 + c1 vs a1 + c2
- (iii) a2 + b1 vs a1 + b2
- (iv) a2 + b2 + c1 vs a1 + b1 + c2
- (v) a2 + b1 + c2 vs a1 + b2 + c1
- (vi) a1 + b2 + c2 vs a2 + b1 + c1
The task is to pairwise rank these six undominated pairs, with the objective that the decision-maker is required to perform the fewest pairwise rankings possible (thereby minimising the elicitation burden).
Ranking undominated pairs and identifying implicitly ranked pairs
Undominated pairs with just two criteria are intrinsically the least cognitively difficult for the decision-maker to pairwise rank relative to pairs with more criteria. Thus, arbitrarily beginning here with pair (i) b2 + c1 vs b1 + c2, the decision-maker is asked: “Which alternative do you prefer, _21 or _12 (i.e. given they’re identical on criterion a), or are you indifferent between them?” This choice, in other words, is between a candidate with good experience and poor references and another with poor experience and good references, all else the same.
Suppose the decision-maker answers: “I prefer _21 to _12” (i.e. good experience and poor references is preferred to poor experience and good references). This preference can be represented by ‘_21 ≻_12’, which corresponds, in terms of total score equations, to b2 + c1 > b1 + c2 [where ‘≻’ and ‘~’ (used later) denote strict preference and indifference respectively, corresponding to the usual relations ‘>’ and ‘=’ for the total score equations].
Central to the PAPRIKA method is the identification of all undominated pairs implicitly ranked as corollaries of the explicitly ranked pairs. Thus, given a2 > a1 (i.e. good education ≻ poor education), it is clear that (i) b2 + c1 > b1 + c2 (as above) implies pair (iv) (see Figure 2) is ranked as a2 + b2 + c1 > a1 + b1 + c2. This reflects the transitivity property of (additive) value models. Specifically, 221≻121 (by dominance) and 121≻112 (i.e. pair i _21≻_12, as above) implies (iv) 221≻112; equivalently, 212≻112 and 221≻212 implies 221≻112.
Next, corresponding to pair (ii) a2 + c1 vs a1 + c2, suppose the decision-maker is asked: “Which alternative do you prefer, 1_2 or 2_1 (given they’re identical on criterion b), or are you indifferent between them?” This choice, in other words, is between a candidate with poor education and good references and another with good education and poor references, all else the same.
Suppose the decision-maker answers: “I prefer 1_2 to 2_1” (i.e. poor education and good references is preferred to good education and poor references). This corresponds to a1 + c2 > a2 + c1. Also, given b2 > b1 (good experience ≻ poor experience), this implies pair (vi) is ranked as a1 + b2 + c2 > a2 + b1 + c1.
Furthermore, the two explicitly ranked pairs (i) b2 + c1 > b1 + c2 and (ii) a1 + c2 > a2 + c1 imply pair (iii) is ranked as a1 + b2 > a2 + b1. This can easily be seen by adding the corresponding sides of the inequalities for pairs (i) and (ii) and cancelling common variables. Again, this reflects the transitivity property: (i) 121≻112 and (ii) 112≻211 implies (iii) 121≻211; equivalently, 122≻221 and 221≻212 implies 122≻212.
As a result of two explicit pairwise comparisons – i.e. explicitly performed by the decision-maker – five of the six undominated pairs have been ranked. The decision-maker may cease ranking whenever she likes (before all undominated pairs are ranked), but let’s suppose she continues and ranks the remaining pair (v) as a2 + b1 + c2 > a1 + b2 + c1 (i.e. in response to an analogous question to the two spelled out above).
Thus, all six undominated pairs have been ranked as a result of the decision-maker explicitly ranking just three:
- (i) b2 + c1 > b1 + c2
- (ii) a1 + c2 > a2 + c1
- (v) a2 + b1 + c2 > a1 + b2 + c1
The overall ranking of alternatives and point values
Because the three pairwise rankings above are consistent – and all n (n−1)/2 = 28 pairwise rankings (n = 8) for this simple value model are known – a complete overall ranking of all eight possible alternatives is defined (1st to 8th): 222, 122, 221, 212, 121, 112, 211, 111.
Simultaneously solving the three inequalities above (i, ii, v), subject to a2 > a1, b2 > b1 and c2 > c1, gives the point values (i.e. the ‘points system’), reflecting the relative importance of the criteria to the decision-maker. For example, one solution is: a1 = 0, a2 = 2, b1 = 0, b2 = 4, c1 = 0 and c2 = 3 (or normalised so the ‘best’ alternative, 222, scores 100 points: a1 = 0, a2 = 22.2, b1 = 0, b2 = 44.4, c1 = 0 and c2 = 33.3).
Thus, in the context of the example of a value model for ranking candidates for a job, the most important criterion is revealed to be (good) experience (b, 4 points) followed by references (c, 3 points) and, least important, education (a, 2 points). Although multiple solutions to the three inequalities are possible, the resulting point values all reproduce the same overall ranking of alternatives as listed above and reproduced here with their total scores:
- 1st 222: 2 + 4 + 3 = 9 points (or 22.2 + 44.4 + 33.3 = 100 points normalised) – i.e. total score from adding the point values above.
- 2nd 122: 0 + 4 + 3 = 7 points (or 0 + 44.4 + 33.3 = 77.8 points normalised)
- 3rd 221: 2 + 4 + 0 = 6 points (or 22.2 + 44.4 + 0 = 66.7 points normalised)
- 4th 212: 2 + 0 + 3 = 5 points (or 22.2 + 0 + 33.3 = 55.6 points normalised)
- 5th 121: 0 + 4 + 0 = 4 points (or 0 + 44.4 + 0 = 44.4 points normalised)
- 6th 112: 0 + 0 + 3 = 3 points (or 0 + 0 + 33.3 = 33.3 points normalised)
- 7th 211: 2 + 0 + 0 = 2 points (or 22.2 + 0 + 0 = 22.2 points normalised)
- 8th 111: 0 + 0 + 0 = 0 points (or 0 + 0 + 0 = 0 points normalised)
Other things worthwhile noting
First, the decision-maker may decline to explicitly rank any given undominated pair (thereby excluding it) on the grounds that at least one of the alternatives considered corresponds to an impossible combination of the categories on the criteria. Also, if the decision-maker cannot decide how to explicitly rank a given pair, she may skip it – and the pair may eventually be implicitly ranked as a corollary of other explicitly ranked pairs (via transitivity).
Second, in order for all undominated pairs to be ranked, the decision-maker will usually be required to perform fewer pairwise ranking if some indicate indifference rather than strict preference. For example, if the decision-maker had ranked pair (i) above as _21~_12 (i.e. indifference) instead of _21≻_12 (as above), then she would have needed to rank only one more pair rather than two (i.e. just two explicitly ranked pairs in total). On the whole, indifferently ranked pairs generate more corollaries with respect to implicitly ranked pairs than pairs that are strictly ranked.
Finally, the order in which the decision-maker ranks the undominated pairs affects the number of rankings required. For example, if the decision-maker had ranked pair (iii) before pairs (i) and (ii) then it is easy to show that all three would have had to be explicitly ranked, as well as pair (v) (i.e. four explicitly ranked pairs in total). However, determining the optimal order is problematical as it depends on the rankings themselves, which are unknown beforehand.
Applying PAPRIKA to ‘larger’ value models
Of course, most real-world value models have more criteria and categories than the simple example above, which means they have many more undominated pairs. For example, the value model referred to earlier with eight criteria and four categories within each criterion (and 48 = 65,536 possible alternatives) has 2,047,516,416 undominated pairs in total (analogous to the nine identified in Figure 2), of which, excluding replicas, 402,100,560 are unique (analogous to the six in the example above).[1] (As mentioned earlier, for a model of this size the decision-maker is required to explicitly rank approximately 95 pairs defined on two criteria at-a-time, which most decision-makers are likely to be comfortable with.)
For such real-world value models, the simple pairwise-comparisons approach to identifying undominated pairs used in the previous sub-section (represented in Figure 2) is highly impractical. Likewise, identifying all pairs implicitly ranked as corollaries of the explicitly ranked pairs becomes increasingly intractable as the numbers of criteria and categories increase. The PAPRIKA method, therefore, relies on computationally efficient processes for identifying unique undominated pairs and implicitly ranked pairs respectively. The details of these processes are beyond the scope of this article, but are available elsewhere.[1]
How does PAPRIKA compare with traditional scoring methods?
PAPRIKA entails a greater number of judgments (but typically fewer than 100 and often fewer than 50[1]) than most ‘traditional’ scoring methods, such as direct rating,[36] SMART,[37] SMARTER[38] and the Analytic Hierarchy Process.[39] Clearly, though, different types of judgments are involved. For PAPRIKA, the judgements entail pairwise comparisons of undominated pairs (usually defined on just two criteria at-a-time), whereas most traditional methods involve interval scale or ratio scale measurements of the decision-maker’s preferences with respect to the relative importance of criteria and categories respectively. Arguably, the judgments for PAPRIKA are simpler and more natural, and therefore they might reasonably be expected to reflect decision-makers’ preferences more accurately.
See also
- Decision-making software
- Decision making
- Multi-criteria decision analysis
- Conjoint analysis (marketing)
References
- ↑ 1.0 1.1 1.2 1.3 1.4 1.5 1.6 1.7 Hansen, Paul; Ombler, Franz (2008). "A new method for scoring additive multi-attribute value models using pairwise rankings of alternatives". Journal of Multi-Criteria Decision Analysis 15 (3–4): 87. doi:10.1002/mcda.428.
- ↑ Wagstaff, Jeremy (21 September 2005). "Asian Innovation Awards: Contenders Stress Different Ways of Thinking". The Asian Wall Street Journal.
- ↑ Taylor, William J.; Laking, George (2010). "Value for money – recasting the problem in terms of dynamic access prioritisation". Disability & Rehabilitation 32 (12): 1020. doi:10.3109/09638281003775535.
- ↑ Hansen, Paul; Hendry, Alison; Naden, Ray; Ombler, Franz; Stewart, Ralph (2012). "A new process for creating points systems for prioritising patients for elective health services". Clinical Governance: an International Journal 17 (3): 200. doi:10.1108/14777271211251318.
- ↑ Fitzgerald, Avril; Spady, Barbara Conner; DeCoster, Carolyn; Naden, Ray; Hawker, Gillian A.; Noseworthy, Thomas (October 2009). "WCWL Rheumatology Priority Referral Score Reliability and Validity Testing". Arthritis & Rheumatism 60 (Suppl 10): 54. doi:10.1002/art.25137 (inactive 2015-01-09).
- ↑ Fitzgerald, Avril; De Coster, Carolyn; McMillan, Stewart; Naden, Ray; Armstrong, Fraser; Barber, Alison; Cunning, Les; Conner-Spady, Barbara; Hawker, Gillian; Lacaille, Diane; Lane, Carolyn; Mosher, Dianne; Rankin, Jim; Sholter, Dalton; Noseworthy, Tom (2011). "Relative urgency for referral from primary care to rheumatologists: The Priority Referral Score". Arthritis Care & Research 63 (2): 231–9. doi:10.1002/acr.20366. PMID 20890984.
- ↑ Noseworthy, T; De Coster, C; Naden, R (2009). Priority-setting tools for improving access to medical specialists. 6th Health Technology Assessment International Annual Meeting. Annals, Academy of Medicine, Singapore 38 (Singapore): S78.
- ↑ Neogi, Tuhina; Aletaha, Daniel; Silman, Alan J.; Naden, Raymond L.; Felson, David T.; Aggarwal, Rohit; Bingham, Clifton O.; Birnbaum, Neal S.; Burmester, Gerd R.; Bykerk, Vivian P.; Cohen, Marc D.; Combe, Bernard; Costenbader, Karen H.; Dougados, Maxime; Emery, Paul; Ferraccioli, Gianfranco; Hazes, Johanna M. W.; Hobbs, Kathryn; Huizinga, Tom W. J.; Kavanaugh, Arthur; Kay, Jonathan; Khanna, Dinesh; Kvien, Tore K.; Laing, Timothy; Liao, Katherine; Mease, Philip; Ménard, Henri A.; Moreland, Larry W.; Nair, Raj; Pincus, Theodore (2010). "The 2010 American College of Rheumatology/European League Against Rheumatism classification criteria for rheumatoid arthritis: Phase 2 methodological report". Arthritis & Rheumatism 62 (9): 2582. doi:10.1002/art.27580.
- ↑ Van Den Hoogen, F.; Khanna, D.; Fransen, J.; Johnson, S. R.; Baron, M.; Tyndall, A.; Matucci-Cerinic, M.; Naden, R. P.; Medsger, T. A.; Carreira, P. E.; Riemekasten, G.; Clements, P. J.; Denton, C. P.; Distler, O.; Allanore, Y.; Furst, D. E.; Gabrielli, A.; Mayes, M. D.; Van Laar, J. M.; Seibold, J. R.; Czirjak, L.; Steen, V. D.; Inanc, M.; Kowal-Bielecka, O.; Müller-Ladner, U.; Valentini, G.; Veale, D. J.; Vonk, M. C.; Walker, U. A. et al. (2013). "2013 Classification Criteria for Systemic Sclerosis: An American College of Rheumatology/European League Against Rheumatism Collaborative Initiative". Arthritis & Rheumatism 65 (11): 2737. doi:10.1002/art.38098.
- ↑ Van Den Hoogen, F.; Khanna, D.; Fransen, J.; Johnson, S. R.; Baron, M.; Tyndall, A.; Matucci-Cerinic, M.; Naden, R. P.; Medsger, T. A.; Carreira, P. E.; Riemekasten, G.; Clements, P. J.; Denton, C. P.; Distler, O.; Allanore, Y.; Furst, D. E.; Gabrielli, A.; Mayes, M. D.; Van Laar, J. M.; Seibold, J. R.; Czirjak, L.; Steen, V. D.; Inanc, M.; Kowal-Bielecka, O.; Muller-Ladner, U.; Valentini, G.; Veale, D. J.; Vonk, M. C.; Walker, U. A. et al. (2013). "2013 classification criteria for systemic sclerosis: An American college of rheumatology/European league against rheumatism collaborative initiative". Annals of the Rheumatic Diseases 72 (11): 1747–55. doi:10.1136/annrheumdis-2013-204424. PMID 24092682.
- ↑ Johnson, S. R.; Naden, R. P.; Fransen, J.; Van Den Hoogen, F.; Pope, J. E.; Baron, M.; Tyndall, A.; Matucci-Cerinic, M.; Denton, C. P.; Distler, O.; Gabrielli, A.; Van Laar, J. M.; Mayes, M.; Steen, V.; Seibold, J. R.; Clements, P.; Medsger, T. A.; Carreira, P. E.; Riemekasten, G.; Chung, L.; Fessler, B. J.; Merkel, P. A.; Silver, R.; Varga, J.; Allanore, Y.; Mueller-Ladner, U.; Vonk, M. C.; Walker, U. A.; Cappelli, S.; Khanna, D. (2014). "Multicriteria decision analysis methods with 1000Minds for developing systemic sclerosis classification criteria". Journal of Clinical Epidemiology 67 (6): 706. doi:10.1016/j.jclinepi.2013.12.009.
- ↑ Golan, Ofra; Hansen, Paul; Kaplan, Giora; Tal, Orna (2011). "Health technology prioritization: Which criteria for prioritizing new technologies and what are their relative weights?". Health Policy 102 (2–3): 126–35. doi:10.1016/j.healthpol.2010.10.012. PMID 21071107.
- ↑ Golan, Ofra G; Hansen, Paul (2012). "Which health technologies should be funded? A prioritization framework based explicitly on value for money". Israel Journal of Health Policy Research 1 (1): 44. doi:10.1186/2045-4015-1-44. PMC 3541977. PMID 23181391.
- ↑ Taylor, W. J.; Singh, J. A.; Saag, K. G.; Dalbeth, N.; MacDonald, P. A.; Edwards, N. L.; Simon, L. S.; Stamp, L. K.; Neogi, T.; Gaffo, A. L.; Khanna, P. P.; Becker, M. A.; Schumacher Jr, H. R. (2011). "Bringing It All Together: A Novel Approach to the Development of Response Criteria for Chronic Gout Clinical Trials". The Journal of Rheumatology 38 (7): 1467–70. doi:10.3899/jrheum.110274. PMID 21724718.
- ↑ Taylor, William J.; Brown, Melanie; Aati, Opetaia; Weatherall, Mark; Dalbeth, Nicola (2013). "Do Patient Preferences for Core Outcome Domains for Chronic Gout Studies Support the Validity of Composite Response Criteria?". Arthritis Care & Research 65 (8): 1259. doi:10.1002/acr.21955.
- ↑ Dobson, F.; Hinman, R.S.; Roos, E.M.; Abbott, J.H.; Stratford, P.; Davis, A.M.; Buchbinder, R.; Snyder-Mackler, L.; Henrotin, Y.; Thumboo, J.; Hansen, P.; Bennell, K.L. (2013). "OARSI recommended performance-based tests to assess physical function in people diagnosed with hip or knee osteoarthritis". Osteoarthritis and Cartilage 21 (8): 1042–52. doi:10.1016/j.joca.2013.05.002. PMID 23680877.
- ↑ Nicolson, P. J.; French, S. D.; Hinman, R. S.; Hodges, P. W.; Dobson, F. L.; Bennell, K. L. (2014). "Developing key messages for people with osteoarthritis: A delphi study". Osteoarthritis and Cartilage 22: S305. doi:10.1016/j.joca.2014.02.569.
- ↑ Ruhland, Johannes (2006). "Strategic mobilization: What strategic management can learn from social movement research". Management 11 (44): 23–31.
- ↑ Smith, C (2009), "Revealing monetary policy preferences", Reserve Bank of New Zealand Discussion Paper Series, DP2009/01;
- ↑ Smith, K. F.; Fennessy, P. F. (2011). "The use of conjoint analysis to determine the relative importance of specific traits as selection criteria for the improvement of perennial pasture species in Australia". Crop and Pasture Science 62 (4): 355–65. doi:10.1071/CP10320.
- ↑ Smith, K. F.; Fennessy, P. F. (2014). "Utilizing Conjoint Analysis to Develop Breeding Objectives for the Improvement of Pasture Species for Contrasting Environments when the Relative Values of Individual Traits Are Difficult to Assess". Sustainable Agriculture Research 3 (2). doi:10.5539/sar.v3n2p44.
- ↑ Byrne, T. J.; Amer, P. R.; Fennessy, P. F.; Hansen, P.; Wickham, B. W. (2011). "A preference-based approach to deriving breeding objectives: Applied to sheep breeding". Animal 6 (5): 778–88. doi:10.1017/S1751731111002060. PMID 22558925.
- ↑ Boyd, Philip; Law, Cliff; Doney, Scott (2011). "A Climate Change Atlas for the Ocean". Oceanography 24 (2): 13–6. doi:10.5670/oceanog.2011.42.
- ↑ Chhun, Sophal; Thorsnes, Paul; Moller, Henrik (2013). "Preferences for Management of Near-Shore Marine Ecosystems: A Choice Experiment in New Zealand". Resources 2 (3): 406–438. doi:10.3390/resources2030406.
- ↑ Graff, P.; McIntyre, S. (2014). "Using ecological attributes as criteria for the selection of plant species under three restoration scenarios". Austral Ecology: n/a. doi:10.1111/aec.12156.
- ↑ Crozier, G. K. D.; Schulte-Hostedde, A. I. (2014). "Towards Improving the Ethics of Ecological Research". Science and Engineering Ethics. doi:10.1007/s11948-014-9558-4.
- ↑ Uldana Baizyldayeva; Oleg Vlasov; Abu A. Kuandykov; Turekhan B. Akhmetov (2013). "Multi-Criteria Decision Support Systems. Comparative Analysis". Middle-East Journal of Scientific Research 16 (12): 1725–1730. doi:10.5829/idosi.mejsr.2013.16.12.12103 (inactive 2015-01-09). ISSN 1990-9233.
- ↑ Karlin, B.; Davis, N.; Sanguinetti, A.; Gamble, K.; Kirkby, D.; Stokols, D. (2012). "Dimensions of Conservation: Exploring Differences Among Energy Behaviors". Environment and Behavior 46 (4): 423. doi:10.1177/0013916512467532.
- ↑ Hansen, P.; Kergozou, N.; Knowles, S.; Thorsnes, P. (2014). "Developing Countries in Need: Which Characteristics Appeal most to People when Donating Money?". The Journal of Development Studies: 1. doi:10.1080/00220388.2014.925542.
- ↑ Belton, V and Stewart, TJ, Multiple Criteria Decision Analysis: An Integrated Approach, Kluwer: Boston, 2002.
- ↑ Johnson, Richard M. (1976). "Beyond conjoint measurement: A method of pairwise trade-off analysis". Advances in Consumer Research 3: 353–8.
- ↑ Green, P. E.; Krieger, A. M.; Wind, Y. (2001). "Thirty Years of Conjoint Analysis: Reflections and Prospects". Interfaces 31 (3_supplement): S56. doi:10.1287/inte.31.3s.56.9676.
- ↑ Larichev, O.I.; Moshkovich, H.M. (1995). "ZAPROS-LM — A method and system for ordering multiattribute alternatives". European Journal of Operational Research 82 (3): 503. doi:10.1016/0377-2217(93)E0143-L.
- ↑ Moshkovich, Helen M; Mechitov, Alexander I; Olson, David L (2002). "Ordinal judgments in multiattribute decision analysis". European Journal of Operational Research 137 (3): 625. doi:10.1016/S0377-2217(01)00106-0.
- ↑ Krantz, D. H. (1972). "Measurement Structures and Psychological Laws". Science 175 (4029): 1427–35. Bibcode:1972Sci...175.1427K. doi:10.1126/science.175.4029.1427. PMID 17842276.
- ↑ Von Winterfeldt, D and Edwards, W, Decision Analysis and Behavioral Research, Cambridge University Press: New York, 1986.
- ↑ Edwards, Ward (1977). "How to Use Multiattribute Utility Measurement for Social Decisionmaking". IEEE Transactions on Systems, Man, and Cybernetics 7 (5): 326. doi:10.1109/TSMC.1977.4309720.
- ↑ Edwards, Ward; Barron, F.Hutton (1994). "SMARTS and SMARTER: Improved Simple Methods for Multiattribute Utility Measurement". Organizational Behavior and Human Decision Processes 60 (3): 306. doi:10.1006/obhd.1994.1087.
- ↑ Saaty, TL, The Analytic Hierarchy Process, McGraw-Hill: New York, 1980.