Order-maintenance problem
In Computer Science the Order-Maintenance Problem involves maintaining a totally ordered set supporting the following operations:
-
insert(X, Y), which inserts X immediately after Y in the total order; -
order(X, Y), which determines if X precedes Y in the total order; and -
delete(X), which removes X from the set.
The first data structure for order-maintenance was given by Dietz in
1982.[1] This data
structure supports insert(X, Y) in 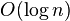 amortized time and
amortized time and order(X, Y) in constant time but does
not support deletion. Tsakalidis published a data structure in 1984
based on BB[α] trees with the same performance bounds that supports
deletion in and showed how indirection can be
used to improve insertion and deletion performance to
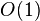 amortized time.[2] In 1987 Dietz and Sleator published the first data
structure supporting all operations in worst-case constant time.[3]
amortized time.[2] In 1987 Dietz and Sleator published the first data
structure supporting all operations in worst-case constant time.[3]
Efficient data structures for order-maintenance have applications in many areas, including data structure persistence,[4] graph algorithms[5][6] and fault-tolerant data structures.[7]
List-labeling
A problem related to the order-maintenance problem is the
list-labeling problem in which instead of the order(X,
Y) operation the solution must maintain an assignment of labels
from a universe of integers 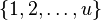 to the
elements of the set such that X precedes Y in the total order if and
only if X is assigned a lesser label than Y. It must also support an
operation
to the
elements of the set such that X precedes Y in the total order if and
only if X is assigned a lesser label than Y. It must also support an
operation label(X) returning the label of any node X.
Note that order(X, Y) can be implemented simply by
comparing label(X) and label(Y) so that any
solution to the list-labeling problem immediately gives one to the
order-maintenance problem. In fact, most solutions to the
order-maintenance problem are solutions to the list-labeling problem
augmented with a level of data structure indirection to improve
performance. We will see an example of this below.
For efficiency, it is desirable for the size 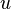 of the
universe be bounded in the number of elements
of the
universe be bounded in the number of elements  stored in
the data structure. In the case where is required to be
linear in the problem is known as the packed-array maintenance or dense sequential file maintenance problem.
Consider the elements as entries in a file and the labels as giving
the addresses where each element is stored. Then an efficient solution
to the packed-array maintenance problem would allow efficient
insertions and deletions of entries into the middle of a file with no
asymptotic space overhead.[8][9][10][11][12] This usage has recent applications in
cache-oblivious data structures[13]
and optimal worst-case in-place sorting.[14]
stored in
the data structure. In the case where is required to be
linear in the problem is known as the packed-array maintenance or dense sequential file maintenance problem.
Consider the elements as entries in a file and the labels as giving
the addresses where each element is stored. Then an efficient solution
to the packed-array maintenance problem would allow efficient
insertions and deletions of entries into the middle of a file with no
asymptotic space overhead.[8][9][10][11][12] This usage has recent applications in
cache-oblivious data structures[13]
and optimal worst-case in-place sorting.[14]
However, under some restrictions, 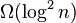 lower
bounds have been found on the performance of insertion in solutions of
the list-labeling problem with linear universes[15] whereas we
will see below that a solution with a polynomial universe can perform
insertions in time.
lower
bounds have been found on the performance of insertion in solutions of
the list-labeling problem with linear universes[15] whereas we
will see below that a solution with a polynomial universe can perform
insertions in time.
List-labeling and binary search trees
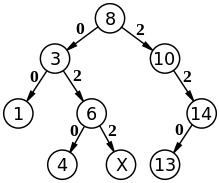
List-labeling in a universe of size polynomial in the number
of elements in the total order is connected to the
problem of maintaining balance in a binary search tree. Note that
every node X of a binary search tree is implicitly labeled with an
integer that corresponds to its path from the root of the tree. We
call this integer the path label of X and define it as follows.
Let 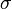 be the sequence of left and right descents in
this path. For example,
be the sequence of left and right descents in
this path. For example, 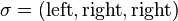 if X is the right child of the right child of the
left child of the root of the tree. Then X is labeled with the integer
whose base 3 representation is given by replacing every
occurrence of
if X is the right child of the right child of the
left child of the root of the tree. Then X is labeled with the integer
whose base 3 representation is given by replacing every
occurrence of 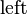 in with 0,
replacing every occurrence of
in with 0,
replacing every occurrence of 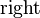 in
with 2 and appending 1 to the end of the resulting
string. Then in the previous example, the path label of X is
02213 which is equal to 25 in base 10. Note that path
labels preserve tree-order and so can be used to answer order queries
in constant time.
in
with 2 and appending 1 to the end of the resulting
string. Then in the previous example, the path label of X is
02213 which is equal to 25 in base 10. Note that path
labels preserve tree-order and so can be used to answer order queries
in constant time.
If the tree has height 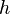 then these integers come from
the universe
then these integers come from
the universe 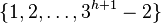 . Then if the
tree is self-balancing so that
it maintains a height no greater than
. Then if the
tree is self-balancing so that
it maintains a height no greater than 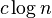 then the
size of the universe is polynomial in .
then the
size of the universe is polynomial in .
Therefore, the list-labeling problem can be solved by maintaining a
balanced binary search tree on the elements in the list augmented with
path labels for each node. However, since every rebalancing operation
of the tree would have to also update these path labels, not every
self-balancing tree data structure is suitable for this application.
Note, for example, that rotating a node with a subtree of size
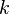 , which can be done in constant time under usual
circumstances, requires
, which can be done in constant time under usual
circumstances, requires 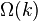 path label updates. In
particular, if the node being rotated is the root then the rotation
would take time linear in the size of the whole tree. With that much
time the entire tree could be rebuilt. We will see below that there
are self-balancing binary search tree data structures that cause an
appropriate number of label updates during rebalancing.
path label updates. In
particular, if the node being rotated is the root then the rotation
would take time linear in the size of the whole tree. With that much
time the entire tree could be rebuilt. We will see below that there
are self-balancing binary search tree data structures that cause an
appropriate number of label updates during rebalancing.
Data structure
The list-labeling problem can be solved with a universe of size
polynomial in the number of elements by augmenting a
scapegoat tree with the path labels described above. Scapegoat
trees do all of their rebalancing by rebuilding subtrees. Since it
takes time to rebuild a subtree of size
, relabeling that subtree in 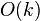 time
after it is rebuilt does not change the asymptotic performance of the
rebalancing operation.
time
after it is rebuilt does not change the asymptotic performance of the
rebalancing operation.
Order
Given two nodes X and Y, order(X, Y) determines their
order by comparing their path labels.
Insert
Given a new node for X and a pointer to the node Y, insert(X,
Y) inserts X immediately after Y in the usual way. If a
rebalancing operation is required, the appropriate subtree is rebuilt,
as usual for a scapegoat tree. Then that subtree is traversed depth
first and the path labels of each of its nodes is updated. As
described above, this asymptotically takes no longer than the usual
rebuilding operation.
Delete
Deletion is performed similarly to insertion. Given the node X to be
deleted, delete(X) removes X as usual. Any subsequent
rebuilding operation is followed by a relabeling of the rebuilt
subtree.
Analysis
It follows from the argument above about the rebalancing performance
of a scapegoat tree augmented with path labels that the insertion and
deletion performance of this data structure are asymptotically no
worse than in a regular scapegoat tree. Then, since insertions and
deletions take amortized time in scapegoat
trees, the same holds for this data structure.
Furthermore, since a scapegoat tree with parameter α maintains a
height of at most 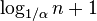 , the path labels
have size at most
, the path labels
have size at most 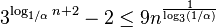 . For the typical value of
. For the typical value of
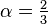 then the labels are at most
then the labels are at most
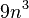 .
.
Of course, the order of two nodes can be determined in constant time
by comparing their labels. A closer inspection shows that this holds
even for large . Specifically, if the word size of the
machine is 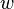 bits, then typically it can address at most
bits, then typically it can address at most
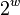 nodes so that
nodes so that 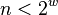 . It follows that
the universe has size at most
. It follows that
the universe has size at most 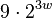 and so that
the labels can be represented with a constant number of (at most
and so that
the labels can be represented with a constant number of (at most 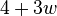 ) bits.
) bits.
Lower bound on list-labeling
It has been shown that any solution to the list-labeling problem with
a universe polynomial in the number of elements will have insertion
and deletion performance no better than 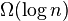 .[16] Then, for list-labeling, the above solution is
asymptotically optimal. Incidentally, this also proves an
lower bound on the amortized rebalancing
time of an insertion or deletion in a scapegoat tree.
.[16] Then, for list-labeling, the above solution is
asymptotically optimal. Incidentally, this also proves an
lower bound on the amortized rebalancing
time of an insertion or deletion in a scapegoat tree.
However, this lower bound does not apply to the order-maintenance problem and, as stated above, there are data structures that give worst-case constant time performance on all order-maintenance operations.
O(1) amortized insertion via indirection
Indirection is a technique used in data structures in which a problem
is split into multiple levels of a data structure in order to improve
efficiency. Typically, a problem of size is split into
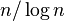 problems of size
problems of size 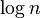 . For
example, this technique is used in y-fast tries. This
strategy also works to improve the insertion and deletion performance
of the data structure described above to constant amortized time. In
fact, this strategy works for any solution of the list-labeling
problem with amortized insertion and deletion
time.
. For
example, this technique is used in y-fast tries. This
strategy also works to improve the insertion and deletion performance
of the data structure described above to constant amortized time. In
fact, this strategy works for any solution of the list-labeling
problem with amortized insertion and deletion
time.
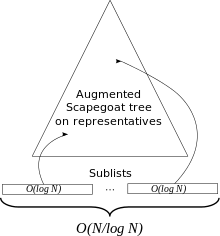
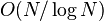 contiguous sublists of size
contiguous sublists of size 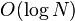 , each of which has a representative in the scapegoat tree.
, each of which has a representative in the scapegoat tree.The new data structure is completely rebuilt whenever it grows too
large or too small. Let 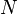 be the number of elements of
the total order when it was last rebuilt. The data structure is
rebuilt whenever the invariant
be the number of elements of
the total order when it was last rebuilt. The data structure is
rebuilt whenever the invariant 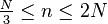 is
violated by an insertion or deletion. Since rebuilding can be done in
linear time this does not affect the amortized performance of
insertions and deletions.
is
violated by an insertion or deletion. Since rebuilding can be done in
linear time this does not affect the amortized performance of
insertions and deletions.
During the rebuilding operation, the elements of the
total order are split into contiguous
sublists, each of size 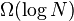 . A path-labeled
scapegoat tree is constructed on a set of nodes representing each of
the sublists in their original list order. For each sublist a
doubly-linked of its elements is built storing with each element a
pointer to its representative in the tree as well as a local integer
label. These local labels are independent of the labels used in the
tree and are used to compare any two elements of the same sublist. The
elements of a sublist are given the local labels
. A path-labeled
scapegoat tree is constructed on a set of nodes representing each of
the sublists in their original list order. For each sublist a
doubly-linked of its elements is built storing with each element a
pointer to its representative in the tree as well as a local integer
label. These local labels are independent of the labels used in the
tree and are used to compare any two elements of the same sublist. The
elements of a sublist are given the local labels 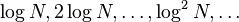 , in their original list order.
, in their original list order.
Order
Given the sublist nodes X and Y, order(X, Y) can be
answered by first checking if the two nodes are in the same
sublist. If so, their order can be determined by comparing their local
labels. Otherwise the path labels of their representatives in the tree
are compared. This takes constant time.
Insert
Given a new sublist node for X and a pointer to the sublist node Y,
insert(X, Y) inserts X immediately after Y in the sublist
of Y. If X is inserted at the end of the sublist, it is given the
local label 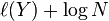 , where
, where 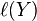 is the local label of Y; otherwise, if possible, it is labeled with
the floor of the average of the local labels of its two neighbours.
This easy case takes constant time.
is the local label of Y; otherwise, if possible, it is labeled with
the floor of the average of the local labels of its two neighbours.
This easy case takes constant time.
In the hard case, the neighbours of X have contiguous local labels and
the sublist has to be rebuilt. However, in this case at least
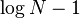 elements have been added to the sublist since
it was first built. Then we can afford to spend a linear amount of
time in the size of the sublist to rebuild it and possibly split it
into smaller sublists without affecting the amortized cost of
insertion by any more than a constant.
elements have been added to the sublist since
it was first built. Then we can afford to spend a linear amount of
time in the size of the sublist to rebuild it and possibly split it
into smaller sublists without affecting the amortized cost of
insertion by any more than a constant.
If the sublist has size then we split it into
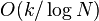 contiguous sublists of size , locally labeling each new sublist as described above and
pointing each element of a sublist to a new representative node to be
inserted into the tree. It takes time to construct
the sublists. Since we do not allow empty sublists, there are at most
contiguous sublists of size , locally labeling each new sublist as described above and
pointing each element of a sublist to a new representative node to be
inserted into the tree. It takes time to construct
the sublists. Since we do not allow empty sublists, there are at most
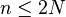 of them and so a representative can be inserted
into the tree in time. Hence, it takes
time to insert all of the new representatives into
the tree.
of them and so a representative can be inserted
into the tree in time. Hence, it takes
time to insert all of the new representatives into
the tree.
Delete
Given a sublist node X to be deleted, delete(X) simply
removes X from its sublist in constant time. If this leaves the
sublist empty, then we need to remove the representative of the
sublist from the tree. Since at least
elements were deleted from the sublist since it was first built we can afford to spend the time it takes to remove the representative without affecting the amortized cost of deletion by any more than a constant.
See also
References
- ↑ Dietz, Paul F. (1982), "Maintaining order in a linked list", Proceedings of the 14th Annual ACM Symposium on Theory of Computing (STOC '82), New York, NY, USA: ACM, pp. 122–127, doi:10.1145/800070.802184.
- ↑ Tsakalidis, Athanasios K. (1984), "Maintaining order in a generalized linked list", Acta Informatica 21 (1): 101–112, doi:10.1007/BF00289142, MR 747173.
- ↑ Dietz, P.; Sleator, D. (1987), "Two algorithms for maintaining order in a list", Proceedings of the 19th Annual ACM Symposium on Theory of Computing (STOC '87), New York, NY, USA: ACM, pp. 365–372, doi:10.1145/28395.28434. Full version, Tech. Rep. CMU-CS-88-113, Carnegie Mellon University, 1988.
- ↑ Driscoll, James R.; Sarnak, Neil; Sleator, Daniel D.; Tarjan, Robert E. (1989), "Making data structures persistent", Journal of Computer and System Sciences 38 (1): 86–124, doi:10.1016/0022-0000(89)90034-2, MR 990051.
- ↑ Eppstein, David; Galil, Zvi; Italiano, Giuseppe F.; Nissenzweig, Amnon (1997), "Sparsification—a technique for speeding up dynamic graph algorithms", Journal of the ACM 44 (5): 669–696, doi:10.1145/265910.265914, MR 1492341.
- ↑ Katriel, Irit; Bodlaender, Hans L. (2006), "Online topological ordering", ACM Transactions on Algorithms 2 (3): 364–379, doi:10.1145/1159892.1159896, MR 2253786.
- ↑ Aumann, Yonatan; Bender, Michael A. (1996), "Fault tolerant data structures", Proceedings of the 37th Annual Symposium on Foundations of Computer Science (FOCS 1996), pp. 580–589, doi:10.1109/SFCS.1996.548517.
- ↑ Itai, Alon; Konheim, Alan; Rodeh, Michael (1981), "A sparse table implementation of priority queues", Automata, Languages and Programming: Eighth Colloquium Acre (Akko), Israel July 13–17, 1981, Lecture Notes in Computer Science 115, pp. 417–431, doi:10.1007/3-540-10843-2_34.
- ↑ Willard, Dan E. (1981), Inserting and deleting records in blocked sequential files, Technical Report TM81-45193-5, Bell Laboratories.
- ↑ Willard, Dan E. (1982), "Maintaining dense sequential files in a dynamic environment (Extended Abstract)", Proceedings of the 14th ACM Symposium on Theory of Computing (STOC '82), New York, NY, USA: ACM, pp. 114–121, doi:10.1145/800070.802183.
- ↑ Willard, Dan E. (1986), "Good worst-case algorithms for inserting and deleting records in dense sequential files", Proceedings of the 1986 ACM SIGMOD International Conference on Management of Data (SIGMOD '86), SIGMOD Record 15(2), New York, NY, USA: ACM, pp. 251–260, doi:10.1145/16894.16879.
- ↑ Willard, Dan E. (1992), "A density control algorithm for doing insertions and deletions in a sequentially ordered file in a good worst-case time", Information and Computation 97 (2): 150–204, doi:10.1016/0890-5401(92)90034-D.
- ↑ Bender, Michael A.; Demaine, Erik D.; Farach-Colton, Martin (2005), "Cache-oblivious B-trees", SIAM Journal on Computing 35 (2): 341–358, doi:10.1137/S0097539701389956, MR 2191447.
- ↑ Franceschini, Gianni; Geffert, Viliam (2005), "An in-place sorting with O(n log n) comparisons and O(n) moves", Journal of the ACM 52 (4): 515–537, doi:10.1145/1082036.1082037, MR 2164627.
- ↑ Dietz, Paul F.; Zhang, Ju (1990), "Lower bounds for monotonic list labeling", SWAT 90 (Bergen, 1990), Lecture Notes in Computer Science 447, Berlin: Springer, pp. 173–180, doi:10.1007/3-540-52846-6_87, MR 1076025.
- ↑ Dietz, Paul F.; Seiferas, Joel I.; Zhang, Ju (1994), "A tight lower bound for on-line monotonic list labeling", Algorithm theory—SWAT '94 (Aarhus, 1994), Lecture Notes in Computer Science 824, Berlin: Springer, pp. 131–142, doi:10.1007/3-540-58218-5_12, MR 1315312.
External links
- Two simplified algorithms for maintaining order in a list. - This paper presents a list-labeling data structure with amortized performance that does not explicitly store a tree. The analysis given is simpler than the one given by (Dietz and Sleator, 1987) for a similar data structure.
- Open Data Structures - Chapter 8 - Scapegoat trees