Optimal matching
Optimal matching is a sequence analysis method used in social science, to assess the dissimilarity of ordered arrays of tokens that usually represent a time-ordered sequence of socio-economic states two individuals have experienced. Once such distances have been calculated for a set of observations (e.g. individuals in a cohort) classical tools (such as cluster analysis) can be used. The method was tailored to social sciences[1] from a technique originally introduced to study molecular biology (protein or genetic) sequences (see sequence alignment). Optimal matching uses the Needleman-Wunsch algorithm.
Algorithm
Let 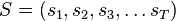 be a sequence of states
be a sequence of states 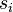 belonging to a finite set of possible states. Let us denote
belonging to a finite set of possible states. Let us denote  the sequence space, i.e. the set of all possible sequences of states.
the sequence space, i.e. the set of all possible sequences of states.
Optimal matching algorithms work by defining simple operator algebras that manipulate sequences, i.e. a set of operators 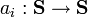 . In the most simple approach, a set composed of only three basic operations to transform sequences is used:
. In the most simple approach, a set composed of only three basic operations to transform sequences is used:
- one state
 is inserted in the sequence
is inserted in the sequence 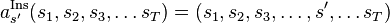
- one state is deleted from the sequence
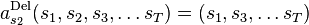 and
and - a state
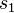 is replaced (substituted) by state
is replaced (substituted) by state 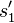 ,
, 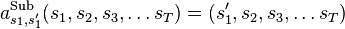 .
.
Imagine now that a cost 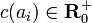 is associated
to each operator. Given two sequences
is associated
to each operator. Given two sequences  and
and  ,
the idea is to measure the cost of obtaining from
using operators from the algebra. Let
,
the idea is to measure the cost of obtaining from
using operators from the algebra. Let 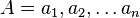 be a sequence of operators such that the application of all the operators of this sequence
be a sequence of operators such that the application of all the operators of this sequence 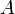 to the first sequence gives the second sequence :
to the first sequence gives the second sequence :
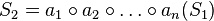 where
where 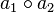 denotes the compound operator.
To this set we associate the cost
denotes the compound operator.
To this set we associate the cost 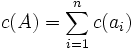 , that
represents the total cost of the transformation. One should consider at this point that there might exist different such sequences that transform into ; a reasonable choice is to select the cheapest of such sequences. We thus
call distance
, that
represents the total cost of the transformation. One should consider at this point that there might exist different such sequences that transform into ; a reasonable choice is to select the cheapest of such sequences. We thus
call distance
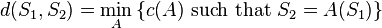
that is, the cost of the least expensive set of transformations that turn into . Notice that 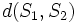 is by definition nonnegative since it is the sum of positive costs, and trivially
is by definition nonnegative since it is the sum of positive costs, and trivially 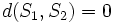 if and only if
if and only if 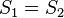 , that is there is no cost. The distance function is symmetric if insertion and deletion costs are equal
, that is there is no cost. The distance function is symmetric if insertion and deletion costs are equal 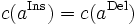 ; the term indel cost usually refers to the common cost of insertion and deletion.
; the term indel cost usually refers to the common cost of insertion and deletion.
Considering a set composed of only the three basic operations described above, this proximity measure satisfies the triangular inequality. Transitivity however, depends on the definition of the set of elementary operations.
Criticism
Although optimal matching techniques are widely used in sociology and demography, such techniques also have their flaws. As was pointed out by several authors (for example L. L. Wu[2]), the main problem in the application of optimal matching is to appropriately define the costs 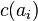 .
.
Optimal matching in causal modelling
Optimal matching is also a term used in statistical modelling of causal effects. In this context it refers to matching "cases" with "controls", and is completely separate from the sequence-analytic sense.
Software
- TDA is a powerful program, offering access to some of the latest developments in transition data analysis.
- STATA has implemented a package to run optimal matching analysis.
- TraMineR is an open source R-package for analysing and visualizing states and events sequences, including optimal matching analysis.
References and notes
- ↑ A. Abbott and A. Tsay, (2000) Sequence Analysis and Optimal Matching Methods in Sociology: Review and Prospect Sociological Methods & Research], Vol. 29, 3-33. doi:10.1177/0049124100029001001
- ↑ L. L. Wu. (2000) Some Comments on "Sequence Analysis and Optimal Matching Methods in Sociology: Review and Prospect" Sociological Methods & Research, 29 41-64. doi:10.1177/0049124100029001003