Optimal estimation
In applied statistics, optimal estimation is a regularized matrix inverse method based on Bayes theorem. It is used very commonly in the geosciences, particularly for atmospheric sounding. A matrix inverse problem looks like this:
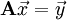
The essential concept is to transform the matrix, A, into a conditional probability and the variables, 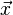 and
and 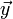 into probability distributions by assuming Gaussian statistics and using empirically-determined covariance matrices.
into probability distributions by assuming Gaussian statistics and using empirically-determined covariance matrices.
Derivation
Typically, one expects the statistics of most measurements to be Gaussian. So for example for 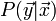 , we can write:
, we can write:
![P(\vec y|\vec x) = \frac {1} {(2 \pi)^{m n/2} | \boldsymbol{S_y}|}
\exp \left [ -\frac{1}{2} (\boldsymbol{A} \vec{x} - \vec{y})^T
\boldsymbol {S_y}^{-1}
(\boldsymbol{A} \vec{x} - \vec{y}) \right ]](../I/m/f848b6ac4b37ba94fef4f9a591165b0c.png)
where m and n are the numbers of elements in and respectively 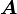 is the matrix to be solved (the linear or linearised forward model) and
is the matrix to be solved (the linear or linearised forward model) and 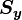 is the covariance matrix of the vector . This can be similarly done for :
is the covariance matrix of the vector . This can be similarly done for :
![P(\vec x) = \frac {1} {(2 \pi)^{m/2} | \boldsymbol {S_{x_a}}|}
\exp \left [-\frac {1}{2} (\vec{x}-\widehat{x_a})^T
\boldsymbol {S_{x_a}}^{-1} (\vec{x}-\widehat{x_a}) \right ]](../I/m/fd7fe830073959a01aa7cb49e1a3c898.png)
Here 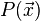 is taken to be the so-called "a-priori" distribution:
is taken to be the so-called "a-priori" distribution: 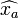 denotes the a-priori values for
denotes the a-priori values for 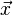 while
while 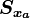 is its covariance matrix.
is its covariance matrix.
The nice thing about the Gaussian distributions is that only two parameters are needed to describe them and so the whole problem can be converted once again to matrices. Assuming that 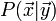 takes the following form:
takes the following form:
![P(\vec x|\vec y) = \frac {1} {(2 \pi)^{m n/2} | \boldsymbol {S_x} |}
\exp \left [ -\frac{1}{2} (\vec{x} - \widehat{x}) ^T
\boldsymbol {S_x}^{-1} (\vec{x} - \widehat{x}) \right ]](../I/m/7cf8567f94a57eb46ffa39c6f6d4cefc.png)
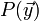 may be neglected since, for a given value of , it is simply a constant scaling term. Now it is possible to solve for both the expectation value of ,
may be neglected since, for a given value of , it is simply a constant scaling term. Now it is possible to solve for both the expectation value of , 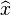 , and for its covariance matrix by equating and
, and for its covariance matrix by equating and 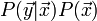 . This produces the following equations:
. This produces the following equations:
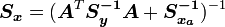
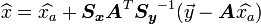
Because we are using Gaussians, the expected value is equivalent to the maximum likely value, and so this is also a form of maximum likelihood estimation.
Typically with optimal estimation, in addition to the vector of retrieved quantities, one extra matrix is returned along with the covariance matrix. This is sometimes called the resolution matrix or the averaging kernel and is calculated as follows:
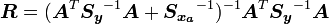
This tells us, for a given element of the retrieved vector, how much of the other elements of the vector are mixed in. In the case of a retrieval of profile information, it typical indicates the altitude resolution for a given altitude. For instance if the resolution vectors for all the altitudes contain non-zero elements (to a numerical tolerance) in their four nearest neighbours, then the altitude resolution is only one fourth that of the actual grid size.
References
- Clive D. Rodgers (1976). "Retrieval of Atmospheric Temperature and Composition From Remote Measurements of Thermal Radiation". Reviews of Geophysics and Space Physics 14 (4). p. 609.
- Clive D. Rodgers (2000). Inverse Methods for Atmospheric Sounding: Theory and Practice. World Scientific.
- Clive D. Rodgers (2002). "Atmospheric Remote Sensing: The Inverse Problem". Proceedings of The Fourth Oxford/RAL Spring School in Quantitative Earth Observation (University of Oxford).