Newman–Keuls method
The Newman–Keuls or Student–Newman–Keuls (SNK) method is a stepwise multiple comparisons procedure used to identify sample means that are significantly different from each other.[1] It was named after Student (1927),[2] D. Newman,[3] and M. Keuls.[4] This procedure is often used as a post-hoc test whenever a significant difference between three or more sample means has been revealed by an analysis of variance (ANOVA).[1] The Newman–Keuls method is similar to Tukey's range test as both procedures use Studentized range statistics.[5][6] Unlike Tukey's range test, the Newman-Keuls method uses different critical values for different pairs of mean comparisons. Thus, the procedure is more likely to reveal significant differences between group means and to commit type I errors by incorrectly rejecting a null hypothesis when it is true. In other words, the Neuman-Keuls procedure is more powerful but less conservative than Tukey's range test.[6][7]
History
The Newman-Keuls method was introduced by Newman in 1939 and developed further by Keuls in 1952. This before Tukey presented the concept of different types of multiple error rates (1952a,[8] 1952b,[9] 1953[10]). The Newman-Keuls method was popular during 1950s and 1960s. But when the control of familywise error rate (FWER) became an accepted criterion in multiple comparison testing, the procedure became less popular as it does not control FWER (except for the special case of exactly three groups[11]). In 1995 Benjamini and Hochberg presented a new, more liberal and more powerful criterion for those types of problems: False discovery rate (FDR) control.[12] In 2006, Shaffer showed (by extensive simulation) that the Newman-Keuls method controls the FDR with some constrains.[13]
Required assumptions
The assumptions of the Newman-Keuls test are essentially the same as for an independent groups t-test: normality, homogeneity of variance, and independent observations. The test is quite robust to violations of normality. Violating homogeneity of variance can be more problematical than in the two-sample case since the MSE is based on data from all groups. The assumption of independence of observations is important and should not be violated.
Procedure
The Newman–Keuls method employs a stepwise approach when comparing sample means.[14] Prior to any mean comparison, all sample means are rank-ordered in ascending or descending order, thereby producing an ordered range (p) of sample means.[1][14] A comparison is then made between the largest and smallest sample means within the largest range.[14] Assuming that the largest range is four means (or p = 4), a significant difference between the largest and smallest means as revealed by the Newman–Keuls method would result in a rejection of the null hypothesis for that specific range of means. The next largest comparison of two sample means would then be made within a smaller range of three means (or p = 3). Unless there is no significant differences between two sample means within any given range, this stepwise comparison of sample means will continue until a final comparison is made with the smallest range of just two means. If there is no significant difference between the two sample means, then all the null hypotheses within that range would be retained and no further comparisons within smaller ranges are necessary.
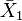 |
 |
 |
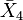 | |
|---|---|---|---|---|
| Mean values | 2 | 4 | 6 | 8 |
| 2 | 2 | 4 | 6 | |
| 4 | 2 | 4 | ||
| 6 | 2 | |||
To determine if there is a significant difference between two means with equal sample sizes, the Newman–Keuls method uses a formula that is identical to the one used in Tukey's range test, which calculates the q value by taking the difference between two sample means and dividing it by the standard error:

where 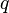 represents the Studentized range value,
represents the Studentized range value, 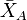 and
and 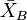 are the largest and smallest sample means within a range,
are the largest and smallest sample means within a range,  is the error variance taken from the ANOVA table, and
is the error variance taken from the ANOVA table, and  is the sample size (number of observations within a sample). If comparisons are made with means of unequal sample sizes (
is the sample size (number of observations within a sample). If comparisons are made with means of unequal sample sizes (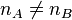 ), then the Newman-Keuls formula would be adjusted as follows:
), then the Newman-Keuls formula would be adjusted as follows:
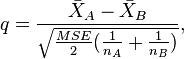
where 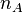 and
and 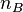 represent the sample sizes of the two sample means. On both cases, MSE (Mean squared error) is taken from the ANOVA conducted in the first stage of the analysis.
represent the sample sizes of the two sample means. On both cases, MSE (Mean squared error) is taken from the ANOVA conducted in the first stage of the analysis.
Once calculated, the computed q value can be compared to a q critical value (or  ), which can be found in a q distribution table based on the significance level (
), which can be found in a q distribution table based on the significance level (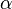 ), the error degrees of freedom (
), the error degrees of freedom (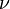 ) from the ANOVA table, and the range (
) from the ANOVA table, and the range (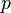 ) of sample means to be tested.[15] If the computed q value is equal to or greater than the q critical value, then the null hypothesis (H0: μA = μB) for that specific range of means can be rejected.[15] Because the number of means within a range changes with each successive pairwise comparison, the critical value of the q statistic also changes with each comparison, which makes the Neuman-Keuls method more lenient and hence more powerful than Tukey's range test. Thus, if a pairwise comparison was found to be significantly different using the Newman–Keuls method, it may not necessarily be significantly different when analyzed with Tukey's range test.[7][15] Conversely, if the pairwise comparison was found not to be significantly different using the Newman–Keuls method, it cannot in any way be significantly different when tested with Tukey's range test.[7]
) of sample means to be tested.[15] If the computed q value is equal to or greater than the q critical value, then the null hypothesis (H0: μA = μB) for that specific range of means can be rejected.[15] Because the number of means within a range changes with each successive pairwise comparison, the critical value of the q statistic also changes with each comparison, which makes the Neuman-Keuls method more lenient and hence more powerful than Tukey's range test. Thus, if a pairwise comparison was found to be significantly different using the Newman–Keuls method, it may not necessarily be significantly different when analyzed with Tukey's range test.[7][15] Conversely, if the pairwise comparison was found not to be significantly different using the Newman–Keuls method, it cannot in any way be significantly different when tested with Tukey's range test.[7]
Limitations
The Newman-Keuls procedure cannot produce an α% confidence interval for each mean difference, or for multiplicity adjusted exact p-values due to its sequential nature. Results are somewhat difficult to interpret since it is difficult to articulate what are the null hypothesis that were tested.
See also
- Multiple comparisons
- Post-hoc analysis
- Tukey's range test
References
- ↑ 1.0 1.1 1.2 Muth, James E. De (2006). Basic Statistics and Pharmaceutical Statistical Applications (2nd ed.). Boca Raton, FL: Chapman and Hall/CRC. pp. 229–259. ISBN 0-849-33799-2.
- ↑ Student (1927). "Errors of routine analysis". Biometrika 19 (1/2): 151–164. doi:10.2307/2332181.
- ↑ Newman D (1939). "The distribution of range in samples from a normal population, expressed in terms of an independent estimate of standard deviation". Biometrika 31 (1): 20–30. doi:10.1093/biomet/31.1-2.20.
- ↑ Keuls M (1952). "The use of the "studentized range" in connection with an analysis of variance". Euphytica 1: 112–122. doi:10.1007/bf01908269.
- ↑ Broota, K.D. (1989). Experimental Design in Behavioural Research (1st ed.). New Delhi, India: New Age International (P) Ltd. pp. 81–96. ISBN 8-122-40215-1.
- ↑ 6.0 6.1 Sheskin, David J. (1989). Handbook of Parametric and Nonparametric Statistical Procedures (3rd ed.). Boca Raton, FL: CRC Press. pp. 665–756. ISBN 1-584-88440-1.
- ↑ 7.0 7.1 7.2 Roberts, Maxwell; Russo, Riccardo (1999). "Following up a one-factor between-subjects ANOVA". A Student's Guide to Analysis of Variance. Filey, United Kindgom: J&L Composition Ltd. pp. 82–109. ISBN 0-415-16564-4.
- ↑ Tukey, J.W (1952a). "Reminder sheets for Allowances for various types of error rates. Unpublished manuscript". Brown, 1984.
- ↑ Tukey, J.W (1952b). "Reminder sheets for Multiple comparisons. Unpublished manuscript". Brown, 1984.
- ↑ Tukey, J.W (1953). "The problem of multiple comparisons. Unpublished manuscript". Brown, 1984.
- ↑ MA Seaman, JR Levin and RC Serlin M (1991). "New Developments in pairwise multiple comparisons: Some powerful and practicable procedures". Psychological Bulletin: 577–586.
- ↑ Benjamini, Y., Hochberg, Y (1995). "Controlling the false discovery rate: a new and powerful approach to multiple testing". JRSS, series B,methodological 57: 289–300.
- ↑ Shaffer, Juliet P (2007). "Controlling the false discovery rate with constraints: The Newman-Keuls test revisited". Biometrical Journal 47: 136–143. PMID 17342955.
- ↑ 14.0 14.1 14.2 Toothaker, Larry E. (1993). Multiple Comparison Procedures (Quantitative Applications in the Social Sciences) (2nd ed.). Newburry Park, CA: Chapman and Hall/CRC. pp. 27–45. ISBN 0-803-94177-3.
- ↑ 15.0 15.1 15.2 Zar, Jerrold H. (1999). Biostatistical Analysis (4th ed.). Newburry Park, CA: Prentice Hall. pp. 208–230. ISBN 0-130-81542-X.