Navigation function
Navigation function usually refers to a function of position, velocity, acceleration and time which is used to plan robot trajectories through the environment. Generally, the goal of a navigation function is to create feasible, safe paths that avoid obstacles while allowing a robot to move from its starting configuration to its goal configuration.
Potential functions as navigation functions

Potential functions assume that the environment or work space is known. Obstacles are assigned a high potential value, and the goal position is assigned a low potential. To reach the goal position, a robot only needs to follow the negative gradient of the surface.
We can formalize this concept mathematically as following: Let 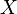 be the state space of all possible configurations of a robot. Let
be the state space of all possible configurations of a robot. Let 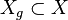 denote the goal region of the state space.
denote the goal region of the state space.
Then a potential function 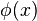 is called a (feasible) navigation function if [1]
is called a (feasible) navigation function if [1]
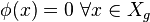
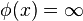 if and only if no point in
if and only if no point in 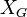 is reachable from
is reachable from 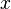 .
. - For every reachable state,
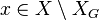 , the local operator produces a state
, the local operator produces a state 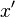 for which
for which 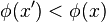 .
.
Navigation Function in Optimal Control
While for certain applications, it suffices to have a feasible navigation function, in many cases it is desirable to have an optimal navigation function with respect to a given cost functional 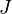 . Formalized as an optimal control problem, we can write
. Formalized as an optimal control problem, we can write
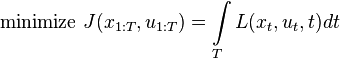
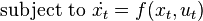
whereby is the state, 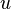 is the control to apply,
is the control to apply, 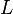 is a cost at a certain state if we apply a control , and
is a cost at a certain state if we apply a control , and 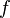 models the transition dynamics of the system.
models the transition dynamics of the system.
Applying Bellman's principle of optimality the optimal cost-to-go function is defined as
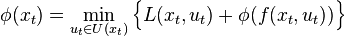
Together with the above defined axioms we can define the optimal navigation function as
-
- if and only if no point in is reachable from .
- For every reachable state, , the local operator produces a state for which .
Stochastic Navigation Function
If we assume the transition dynamics of the system or the cost function as subjected to noise, we obtain a stochastic optimal control problem with a cost 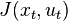 and dynamics . In the field of reinforcement learning the cost is replaced by a reward function
and dynamics . In the field of reinforcement learning the cost is replaced by a reward function 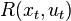 and the dynamics by the transition probabilities
and the dynamics by the transition probabilities 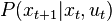 .
.
See also
- Control Theory
- Optimal Control
- Robot Control
- Motion Planning
- Reinforcement Learning
References
- LaValle, Steven M. (2006), Planning Algorithms (First ed.), Cambridge University Press, ISBN 978-0-521-86205-9
- Laumond, Jean-Paul (1998), Robot Motion Planning and Control (First ed.), Springer, ISBN 3-540-76219-1
External links
- NFsim: MATLAB Toolbox for motion planning using Navigation Functions.
References
- ↑ Lavalle, Steven, Planning Algorithms Chapter 8