Naor-Reingold Pseudorandom Function
In 1997, Moni Naor and Omer Reingold described efficient constructions for various cryptographic primitives in private key as well as public-key cryptography. Their result is the construction of an efficient pseudorandom function. Let p and l be prime numbers with l |p-1. Select an element g ∈ 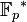 of multiplicative order l. Then for each n-dimensional vector a = (a1, ..., an)∈
of multiplicative order l. Then for each n-dimensional vector a = (a1, ..., an)∈ 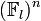 they define the function
they define the function
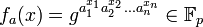
where x = x1 ... xn is the bit representation of integer x, 0 ≤ x ≤ 2n-1, with some extra leading zeros if necessary.[1]
Example
Let p = 7, p – 1 = 6, and l = 3, l |p-1. Select g = 4 ∈ 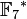 of multiplicative order 3 (since 43 = 64 ≡ 1 mod 7). For n = 3, a = (1, 2, 1) and x = 5 (the bit representation of 5 is 101), we can compute
of multiplicative order 3 (since 43 = 64 ≡ 1 mod 7). For n = 3, a = (1, 2, 1) and x = 5 (the bit representation of 5 is 101), we can compute 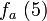 as follows:
as follows:
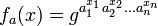
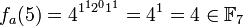
Efficiency
The evaluation of function 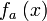 in the Naor-Reingold construction can be done very efficiently. Computing the value of the function at any given point is comparable with one modular exponentiation and n-modular multiplications. This function can be computed in parallel by threshold circuits of bounded depth and polynomial size.
in the Naor-Reingold construction can be done very efficiently. Computing the value of the function at any given point is comparable with one modular exponentiation and n-modular multiplications. This function can be computed in parallel by threshold circuits of bounded depth and polynomial size.
The Naor-Reingold function can be used as the basis of many cryptographic schemes including symmetric encryption, authentication and digital signatures.
Security of the Function
Assume that an attacker sees several outputs of the function, e.g. 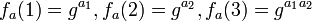 , ...
, ... 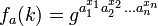 and wants to compute
and wants to compute 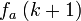 . Assume for simplicity that x1 = 0, then the attacker needs to solve the Computational Diffie-Hellman (CDH) between
. Assume for simplicity that x1 = 0, then the attacker needs to solve the Computational Diffie-Hellman (CDH) between 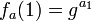 and
and 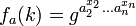 to get
to get 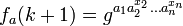 . In general, moving from k to k +1 changes the bit pattern and unless k + 1 is a power of 2 one can split the exponent in so that the computation corresponds to computing the Diffie-Hellman key between two of the earlier results. This attacker wants to predict the next sequence element. Such an attack would be very bad—but it's also possible to fight it off by working in groups with a hard Diffie-Hellman problem (DHP).
. In general, moving from k to k +1 changes the bit pattern and unless k + 1 is a power of 2 one can split the exponent in so that the computation corresponds to computing the Diffie-Hellman key between two of the earlier results. This attacker wants to predict the next sequence element. Such an attack would be very bad—but it's also possible to fight it off by working in groups with a hard Diffie-Hellman problem (DHP).
Example:
An attacker sees several outputs of the function e.g. 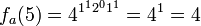 , as in the previous example, and
, as in the previous example, and 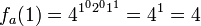 . Then, the attacker wants to predict the next sequence element of this function,
. Then, the attacker wants to predict the next sequence element of this function, 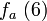 . However, the attacker cannot predict the outcome of from knowing
. However, the attacker cannot predict the outcome of from knowing 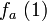 and .
and .
There are other attacks that would be very bad for a Pseudorandom Number Generator: the user expects to get random numbers from the output, so of course the stream should not be predictable, but even more, it should be indistinguishable from a random string. Let 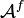 denote the algorithm
denote the algorithm 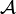 with access to an oracle for evaluating the function . Suppose the Decisional Diffie-Hellman assumption holds for
with access to an oracle for evaluating the function . Suppose the Decisional Diffie-Hellman assumption holds for 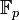 , Naor and Reingold show that for every probabilistic polynomial time algorithm and sufficiently large n
, Naor and Reingold show that for every probabilistic polynomial time algorithm and sufficiently large n
-
![\text{Pr }[\mathcal{A}^{f_{a}(x)}(p,g) \to 1] - \text{Pr }[\mathcal{A}^{R} (p,g)\to 1]](../I/m/b5059fcab366b970390399c9e108a1b8.png) is negligible.
is negligible.
The first probability is taken over the choice of the seed s = (p, g, a) and the second probability is taken over the random distribution induced on p, g by 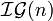 , instance generator, and the random choice of the function
, instance generator, and the random choice of the function 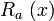 among the set of all
among the set of all 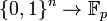 functions.[2]
functions.[2]
Linear Complexity
One natural measure of how useful a sequence may be for cryptographic purposes is the size of its linear complexity. The linear complexity of an n-element sequence W(x), x = 0,1,2,…,n – 1, over a ring 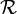 is the length l of the shortest linear recurrence relation W (x + l) = Al-1 W (x +l-1) + … + A0 W(x), x = 0,1,2,…, n – l –1 with A0, …, Al-1 ∈ , which is satisfied by this sequence.
is the length l of the shortest linear recurrence relation W (x + l) = Al-1 W (x +l-1) + … + A0 W(x), x = 0,1,2,…, n – l –1 with A0, …, Al-1 ∈ , which is satisfied by this sequence.
For some 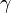 > 0,n ≥ (1+ )
> 0,n ≥ (1+ ) 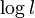 , for any
, for any 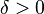 , sufficiently large l, the linear complexity of the sequence ,0 ≤ x ≤ 2n-1, denoted by
, sufficiently large l, the linear complexity of the sequence ,0 ≤ x ≤ 2n-1, denoted by 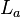 satisfies
satisfies
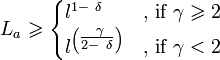
for all except possibly at most 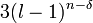 vectors a ∈ .[3] The bound of this work has disadvantages, namely it does not apply to the very interesting case
vectors a ∈ .[3] The bound of this work has disadvantages, namely it does not apply to the very interesting case 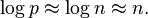
Uniformity of Distribution
The statistical distribution of is exponentially close to uniform distribution for almost all vectors a ∈ .
Let 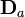 be the discrepancy of the set
be the discrepancy of the set 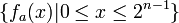 . Thus, if
. Thus, if 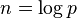 is the bit length of p then for all vectors a ∈ the bound
is the bit length of p then for all vectors a ∈ the bound 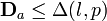 holds, where
holds, where
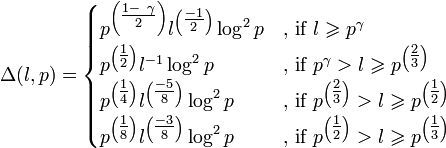
and = 2.5 - 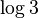 = 0.9150....
= 0.9150....
Although this property does not seem to have any immediate cryptographic implications, the inverse fact, namely non uniform distribution, if true would have disastrous consequences for applications of this function.[4]
Sequences in Elliptic Curve
The elliptic curve version of this function is of interest as well. In particular, it may help to improve the cryptographic security of the corresponding system. Let p > 3 be prime and let E be an elliptic curve over , then each vector a defines a finite sequence in the subgroup 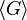 as:
as:
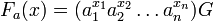
where 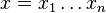 is the bit representation of integer
is the bit representation of integer 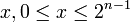 .
The Naor-Reingold elliptic curve sequence is defined as
.
The Naor-Reingold elliptic curve sequence is defined as
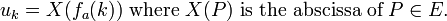
If the Decisional Diffie-Hellman assumption holds, the index k is not enough to compute  in polynomial time, even if an attacker performs polynomially many queries to a random oracle.
in polynomial time, even if an attacker performs polynomially many queries to a random oracle.
See also
- Decisional Diffie-Hellman assumption
- Finite Field
- Inversive congruential generator
- Generalized inversive congruential pseudorandom numbers
Notes
- ↑ Naor, M., Reingold, O. "Number-theoretic constructions of efficient pseudo-random functions," Proc 38th IEEE Symp. on Foundations of Comp. Sci, (1997), 458-467.
- ↑ Boneh, Dan. "The Decision Diffie–Hellman Problem,"ANTS-III: Proceedings of the Third International Symposium on Algorithmic Number Theory,1998,48–63.
- ↑ Shparlinski, Igor E. "Linear Complexity of the Naor-Reingold pseudo-random function," Inform. Process Lett, 76 (2000), 95-99.
- ↑ Shparlinski, Igor E. "On the uniformity of distribution of the Naor-Reingold pseudo-random function," Finite Fields and Their Applications, 7 (2001), 318-326
- ↑ Cruz, M., Gomez, D., Sadornil, D. "On the linear complexity of the Naor-Reingold sequence with elliptic curves," Finite Fields and Their Applications, 16 (2010), 329-333
References
- Shparlinski, Igor (2003), Cryptographic Applications of Analytic Number Theory: Complexity Lower Bounds and Pseudorandomness (first ed.), Birkhäuser Basel, ISBN 978-3-7643-6654-4
- Goldreich, Oded (1998), Modern Cryptography, Probabilistic Proofs and Pseudorandomness (first ed.), Springer, ISBN 978-3-540-64766-9