NIP (model theory)
In model theory, a branch of mathematical logic, a complete theory T is said to satisfy NIP (or "not the independence property") if none of its formulae satisfy the independence property, that is if none of its formulae can pick out any given subset of an arbitrarily large finite set.
Definition
Let T be a complete L-theory. An L-formula φ(x,y) is said to have the independence property (with respect to x, y) if in every model M of T there is, for each n = {0,1,…n − 1} < ω, a family of tuples b0,…,bn−1 such that for each of the 2n subsets X of n there is a tuple a in M for which
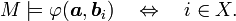
The theory T is said to have the independence property if some formula has the independence property. If no L-formula has the independence property then T is called dependent, or said to satisfy NIP. An L-structure is said to have the independence property (respectively, NIP) if its theory has the independence theory (respectively, NIP). The terminology comes from the notion of independence in the sense of boolean algebras.
In the nomenclature of Vapnik–Chervonenkis theory, we may say that a collection S of subsets of X shatters a set B ⊆ X if every subset of B is of the form B ∩ S for some S ∈ S. Then T has the independence property if in some model M of T there is a definable family (Sa | a∈Mn) ⊆ Mk that shatters arbitrarily large finite subsets of Mk. In other words, (Sa | a∈Mn) has infinite Vapnik–Chervonenkis dimension.
Examples
Any complete theory T that has the independence property is unstable.[1]
In arithmetic, i.e. the structure (N,+,·), the formula "y divides x" has the independence property.[2] This formula is just
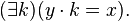
So, for any finite n we take the n 1-tuples bi to be the first n prime numbers, and then for any subset X of {0,1,…n − 1} we let a be the product of those bi such that i is in X. Then bi divides a if and only if i ∈ X.
Every o-minimal theory satisfies NIP.[3] This fact has had unexpected applications to neural network learning.[4]
Notes
References
- Anthony, Martin; Bartlett, Peter L. (1999). Neural network learning: theoretical foundations. Cambridge University Press. ISBN 0-521-57353-X.
- Hodges, Wilfrid (1993). Model theory. Cambridge University Press. ISBN 0-521-30442-3.
- Knight, Julia; Pillay, Anand; Steinhorn, Charles (1986). "Definable sets in ordered structures II". Transactions of the American Mathematical Society 295 (2): 593–605. doi:10.2307/2000053.
- Pillay, Anand; Steinhorn, Charles (1986). "Definable sets in ordered structures I". Transactions of the American Mathematical Society 295 (2): 565–592. doi:10.2307/2000052.
- Poizat, Bruno (2000). A Course in Model Theory. Springer. ISBN 0-387-98655-3.