Multinomial probit
| Regression analysis |
|---|
 |
| Models |
| Estimation |
| Background |
|
In statistics and econometrics, the multinomial probit model is a generalization of the probit model used when there are several possible categories that the dependent variable can fall into. As such, it is an alternative to the multinomial logit model as one method of multiclass classification. It is not to be confused with the multivariate probit model, which is used to model correlated binary outcomes for more than one independent variable.
General specification
It is assumed that we have a series of observations Yi, for i = 1...n, of the outcomes of multi-way choices from a categorical distribution of size m (there are m possible choices). Along with each observation Yi is a set of k observed values x1,i, ..., xk,i of explanatory variables (also known as independent variables, predictor variables, features, etc.). Some examples:
- The observed outcomes might be "has disease A, has disease B, has disease C, has none of the diseases" for a set of rare diseases with similar symptoms, and the explanatory variables might be characteristics of the patients thought to be pertinent (sex, race, age, blood pressure, body-mass index, presence or absence of various symptoms, etc.).
- The observed outcomes are the votes of people for a given party or candidate in a multi-way election, and the explanatory variables are the demographic characteristics of each person (e.g. sex, race, age, income, etc.).
The multinomial probit model is a statistical model that can be used to predict the likely outcome of an unobserved multi-way trial given the associated explanatory variables. In the process, the model attempts to explain the relative effect of differing explanatory variables on the different outcomes.
Formally, the outcomes Yi are described as being categorically-distributed data, where each outcome value h for observation i occurs with an unobserved probability pi,h that is specific to the observation i at hand because it is determined by the values of the explanatory variables associated with that observation. That is:
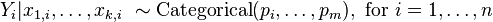
or equivalently
![\Pr[Y_i=h|x_{1,i},\ldots,x_{k,i}] = p_{i,h},\text{ for }i = 1, \dots , n,](../I/m/48c438ed4ebc30b9d66ec9d7e17971af.png)
for each of m possible values of h.
Latent variable model
Multinomial probit is often written in terms of a latent variable model:
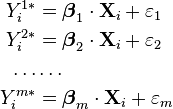
where
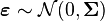
Then
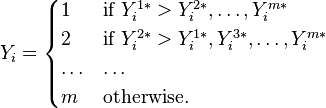
That is,
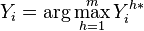
Note that this model allows for arbitrary correlation between the error variables, so that it doesn't necessarily respect independence of irrelevant alternatives.
When 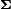 is the identity matrix (such that there is no correlation or heteroscedasticity), the model is called independent probit.
is the identity matrix (such that there is no correlation or heteroscedasticity), the model is called independent probit.