Multi-task learning
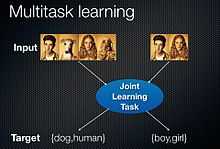
Multi-task learning (MTL) is an approach to machine learning that learns a problem together with other related problems at the same time, using a shared representation. This often leads to a better model for the main task, because it allows the learner to use the commonality among the tasks.[1][2][3] Therefore, multi-task learning is a kind of inductive transfer. This type of machine learning is an approach to inductive transfer that improves generalization by using the domain information contained in the training signals of related tasks as an inductive bias. It does this by learning tasks in parallel while using a shared representation; what is learned for each task can help other tasks be learned better.[4]
The goal of MTL is to improve the performance of learning algorithms by learning classifiers for multiple tasks jointly. This works particularly well if these tasks have some commonality and are generally slightly under sampled. One example is a spam-filter. Everybody has a slightly different distribution over spam or not-spam emails (e.g. all emails in Russian are spam for me—but not so for my Russian colleagues), yet there is definitely a common aspect across users. Multi-task learning works, because encouraging a classifier (or a modification thereof) to also perform well on a slightly different task is a better regularization than uninformed regularizers (e.g. to enforce that all weights are small).[5]
Techniques
Transfer of Knowledge
Until recently, robots have not been capable of understanding and coping with unstructured environments (like the ones humans work in) because their systems have relied on knowing in advance the specifics of every possible situation they might encounter. Each response to a contingency has had to be programmed in advance, and systems have had to rebuild their world model from sensor data each time they had to perform a new task.[6]
This is one of the main reasons why, to date, robots have been mostly relegated to highly controlled and predictable environments like manufacturing plants, but have made few significant inroads into the human sphere. The human world is just too nuanced and too complicated to be summarized within a limited set of specifications. But what if robots could learn from their past experiences? And what if they could share their new-found knowledge instantaneously with their peers? These are not hypothetical questions. Rapid development of sensor and networking technology is now enabling researchers to collect vast amounts of sensor data, and new data-mining tools are being developed to extract meaningful patterns. Researchers are already using networked “feed forward” approaches to make significant advances in machine-based learning systems. Thus far, however, these smart feed forward systems have been operating in isolation from each other. If they are decommissioned, all that learning is lost. Even more disconcerting to researchers is the question: why are thousands of systems solving the same essential problems over and over again anyway?[6]
The aim of project RoboEarth is to use the Internet to create a giant open source network database that can be accessed and continually updated by robots around the world. With knowledge shared via the cloud on such a vast scale, and with businesses and academics contributing independently on a common language platform, RoboEarth has the potential to provide a powerful feed forward to any robot’s 3D sensing, acting and learning capabilities.[6]
Task Grouping and Overlap
In the paradigm of multi-task learning, multiple related prediction tasks are learned jointly, sharing information across the tasks. One can also use a framework for multi-task learning that enables one to selectively share the information across the tasks. Assume that each task parameter vector is a linear combination of a finite number of underlying basis tasks. The coefficients of the linear combination are sparse in nature and the overlap in the sparsity patterns of two tasks controls the amount of sharing across these. This model is based on the assumption that task parameters within a group lie in a low-dimensional subspace but allows the tasks in different groups to overlap with each other in one or more bases.[7]
Exploiting Unrelated Tasks
One can attempt learning a group of principal tasks using a group of auxiliary tasks, unrelated to the principal ones. In many applications, joint learning of unrelated tasks which use the same input data can be beneficial. The reason is that prior knowledge about which tasks are unrelated can lead to sparser and more informative representations for each task, essentially screening out idiosyncrasies of the data distribution. Novel methods which builds on a prior multitask methodology by favouring a shared low-dimensional representation within each group of tasks have been proposed. The programmer can impose a penalty on tasks from different groups which encourages the two representations to be orthogonal. Experiments on synthetic and real data have indicated that incorporating unrelated tasks can improve significantly over standard multi-task learning methods.[8]
Software Package
The Multi-Task Learning via StructurAl Regularization (MALSAR) package [9] implements the following multi-task learning algorithms:
- Mean-Regularized Multi-Task Learning[10][11]
- Multi-Task Learning with Joint Feature Selection[12]
- Robust Multi-Task Feature Learning[13]
- Trace-Norm Regularized Multi-Task Learning[14]
- Alternating Structural Optimization[15][16]
- Incoherent Low-Rank and Sparse Learning[17]
- Robust Low-Rank Multi-Task Learning
- Clustered Multi-Task Learning[18][19]
- Multi-Task Learning with Graph Structures
Applications
Spam Filtering
Using the principles of MTL, techniques for collaborative spam filtering that facilitates personalization have been proposed. In large scale open membership email systems, most users do not label enough messages for an individual local classifier to be effective, while the data is too noisy to be used for a global filter across all users. A hybrid global/individual classifier can be effective at absorbing the influence of users who label emails very diligently from the general public. This can be accomplished while still providing sufficient quality to users with few labeled instances.[20]
Web Search
Using boosted decision trees, one can enable implicit data sharing and regularization. This learning method can be used on web-search ranking data sets. One example is to use ranking data sets from several countries. Here, multitask learning is particularly helpful as data sets from different countries vary largely in size because of the cost of editorial judgments. It has been demonstrated that learning various tasks jointly can lead to significant improvements in performance with surprising reliability.[21]
See also
- Artificial Intelligence
- Artificial neural network
- Evolutionary computation
- Human-based genetic algorithm
- Kernel methods for vector output
- Machine Learning
- Robotics
References
- ↑ Baxter, J. (2000). A model of inductive bias learning. Journal of Artificial Intelligence Research, 12:149--198, On-line paper
- ↑ Caruana, R. (1997). Multitask learning: A knowledge-based source of inductive bias. Machine Learning, 28:41--75. Paper at Citeseer
- ↑ Thrun, S. (1996). Is learning the n-th thing any easier than learning the first?. In Advances in Neural Information Processing Systems 8, pp. 640--646. MIT Press. Paper at Citeseer
- ↑ http://www.cs.cornell.edu/~caruana/mlj97.pdf
- ↑ http://www.cse.wustl.edu/~kilian/research/multitasklearning/multitasklearning.html
- ↑ 6.0 6.1 6.2 Description of RoboEarth Project
- ↑ Kumar, A., & Daume III, H., (2012) Learning Task Grouping and Overlap in Multi-Task Learning. http://icml.cc/2012/papers/690.pdf
- ↑ Romera-Paredes, B., Argyriou, A., Bianchi-Berthouze, N., & Pontil, M., (2012) Exploiting Unrelated Tasks in Multi-Task Learning. http://jmlr.csail.mit.edu/proceedings/papers/v22/romera12/romera12.pdf
- ↑ Zhou, J., Chen, J. and Ye, J. MALSAR: Multi-tAsk Learning via StructurAl Regularization. Arizona State University, 2012. http://www.public.asu.edu/~jye02/Software/MALSAR. On-line manual
- ↑ Evgeniou, T., & Pontil, M. (2004). Regularized multi–task learning. Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 109–117).
- ↑ Evgeniou, T., Micchelli, C., & Pontil, M. (2005). Learning multiple tasks with kernel methods. Journal of Machine Learning Research, 6, 615.
- ↑ Argyriou, A., Evgeniou, T., & Pontil, M. (2008a). Convex multi-task feature learning. Machine Learning, 73, 243–272.
- ↑ Chen, J., Zhou, J., & Ye, J. (2011). Integrating low-rank and group-sparse structures for robust multi-task learning. Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining.
- ↑ Ji, S., & Ye, J. (2009). An accelerated gradient method for trace norm minimization. Proceedings of the 26th Annual International Conference on Machine Learning (pp. 457–464).
- ↑ Ando, R., & Zhang, T. (2005). A framework for learning predictive structures from multiple tasks and unlabeled data. The Journal of Machine Learning Research, 6, 1817–1853.
- ↑ Chen, J., Tang, L., Liu, J., & Ye, J. (2009). A convex formulation for learning shared structures from multiple tasks. Proceedings of the 26th Annual International Conference on Machine Learning (pp. 137–144).
- ↑ Chen, J., Liu, J., & Ye, J. (2010). Learning incoherent sparse and low-rank patterns from multiple tasks. Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 1179–1188).
- ↑ Jacob, L., Bach, F., & Vert, J. (2008). Clustered multi-task learning: A convex formulation. Advances in Neural Information Processing Systems, 2008
- ↑ Zhou, J., Chen, J., & Ye, J. (2011). Clustered multi-task learning via alternating structure optimization. Advances in Neural Information Processing Systems.
- ↑ Attenberg, J., Weinberger, K., & Dasgupta, A. Collaborative Email-Spam Filtering with the Hashing-Trick. http://www.cse.wustl.edu/~kilian/papers/ceas2009-paper-11.pdf
- ↑ Chappelle, O., Shivaswamy, P., & Vadrevu, S. Multi-Task Learning for Boosting with Application to Web Search Ranking. http://www.cse.wustl.edu/~kilian/papers/multiboost2010.pdf
Software
- The Multi-Task Learning via Structural Regularization Package
- Online Multi-Task Learning Toolkit (OMT) A general-purpose online multi-task learning toolkit based on conditional random field models and stochastic gradient descent training (C#, .NET)