Meta-analysis
In statistics, meta-analysis comprises statistical methods for contrasting and combining results from different studies in the hope of identifying patterns among study results, sources of disagreement among those results, or other interesting relationships that may come to light in the context of multiple studies.[1] Meta-analysis can be thought of as "conducting research about previous research." In its simplest form, meta-analysis is done by identifying a common statistical measure that is shared among studies, such as an effect size, and calculating a weighted average of that common measure. This weighting is usually related to the sample sizes of the individual studies, although it can also include other factors, such as study quality.
The motivation of a meta-analysis is to aggregate information in order to achieve a higher statistical power for the measure of interest, as opposed to a less precise measure derived from a single study. In performing a meta-analysis, an investigator must make choices many of which can affect its results, including deciding how to search for studies, selecting studies based on a set of objective criteria, dealing with incomplete data, analyzing the data, and accounting for or choosing not to account for publication bias.[2]
Meta-analyses are often, but not always, important components of a systematic review procedure. For instance, a meta-analysis may be conducted on several clinical trials of a medical treatment, in an effort to obtain a better understanding of how well the treatment works. Here it is convenient to follow the terminology used by the Cochrane Collaboration,[3] and use "meta-analysis" to refer to statistical methods of combining evidence, leaving other aspects of 'research synthesis' or 'evidence synthesis', such as combining information from qualitative studies, for the more general context of systematic reviews.
History
The historical roots of meta-analysis can be traced back to 17th century studies of astronomy, while a paper published in 1904 by the statistician Karl Pearson in the British Medical Journal[4] which collated data from several studies of typhoid inoculation is seen as the first time a meta-analytic approach was used to aggregate the outcomes of multiple clinical studies.[5][6] The first meta-analysis of all conceptually identical experiments concerning a particular research issue, and conducted by independent researchers, has been identified as the 1940 book-length publication Extrasensory Perception After Sixty Years, authored by Duke University psychologists J. G. Pratt, J. B. Rhine, and associates.[7] This encompassed a review of 145 reports on ESP experiments published from 1882 to 1939, and included an estimate of the influence of unpublished papers on the overall effect (the file-drawer problem). Although meta-analysis is widely used in epidemiology and evidence-based medicine today, a meta-analysis of a medical treatment was not published until 1955. In the 1970s, more sophisticated analytical techniques were introduced in educational research, starting with the work of Gene V. Glass, Frank L. Schmidt and John E. Hunter.
The term "meta-analysis" was coined by Gene V. Glass,[8] who was the first modern statistician to formalize the use of the term meta-analysis. He states "my major interest currently is in what we have come to call ...the meta-analysis of research. The term is a bit grand, but it is precise and apt ... Meta-analysis refers to the analysis of analyses". Although this led to him being widely recognized as the modern founder of the method, the methodology behind what he termed "meta-analysis" predates his work by several decades.[9][10] The statistical theory surrounding meta-analysis was greatly advanced by the work of Nambury S. Raju, Larry V. Hedges, Harris Cooper, Ingram Olkin, John E. Hunter, Jacob Cohen, Thomas C. Chalmers, Robert Rosenthal and Frank L. Schmidt.
Advantages
Conceptually, a meta-analysis uses a statistical approach to combine the results from multiple studies in an effort to increase power (over individual studies), improve estimates of the size of the effect and/or to resolve uncertainty when reports disagree. Basically, it produces a weighted average of the included study results and this approach has several advantages:
- Results can be generalized to a larger population,
- The precision and accuracy of estimates can be improved as more data is used. This, in turn, may increase the statistical power to detect an effect.
- Inconsistency of results across studies can be quantified and analyzed. For instance, does inconsistency arise from sampling error, or are study results (partially) influenced by between-study heterogeneity.
- Hypothesis testing can be applied on summary estimates,
- Moderators can be included to explain variation between studies,
- The presence of publication bias can be investigated
Pitfalls
A meta-analysis of several small studies does not predict the results of a single large study.[11] Some have argued that a weakness of the method is that sources of bias are not controlled by the method: a good meta-analysis of badly designed studies will still result in bad statistics.[12] This would mean that only methodologically sound studies should be included in a meta-analysis, a practice called 'best evidence synthesis'.[12] Other meta-analysts would include weaker studies, and add a study-level predictor variable that reflects the methodological quality of the studies to examine the effect of study quality on the effect size.[13] However, others have argued that a better approach is to preserve information about the variance in the study sample, casting as wide a net as possible, and that methodological selection criteria introduce unwanted subjectivity, defeating the purpose of the approach.[14]
Publication bias: the file drawer problem


Another potential pitfall is the reliance on the available body of published studies, which may create exaggerated outcomes due to publication bias, as studies which show negative results or insignificant results are less likely to be published. For example, one may have overlooked dissertation studies or studies that have never been published. This is not easily solved, as one cannot know how many studies have gone unreported.[15]
This file drawer problem results in the distribution of effect sizes that are biased, skewed or completely cut off, creating a serious base rate fallacy, in which the significance of the published studies is overestimated, as other studies were either not submitted for publication or were rejected. This should be seriously considered when interpreting the outcomes of a meta-analysis.[15][16]
The distribution of effect sizes can be visualized with a funnel plot which is a scatter plot of sample size and effect sizes. In fact, for a certain effect level, the smaller the study, the higher is the probability to find it by chance. At the same time, the higher the effect level, the lower is the probability that a larger study can result in that positive result by chance. If many negative studies were not published, the remained positive studies give rise to a funnel plot in which effect size is inversely proportional to sample size, in other words: the higher the effect size, the smaller the sample size. An important part of the shown effect is then due to chance that is not balanced in the plot because of unpublished negative data absence. In contrast, when most studies were published, the effect shown has no reason to be biased by the study size, so a symmetric funnel plot results. So, if no publication bias is present, one would expect that there is no relation between sample size and effect size.[17] A negative relation between sample size and effect size would imply that studies that found significant effects were more likely to be published and/or to be submitted for publication. There are several procedures available that attempt to correct for the file drawer problem, once identified, such as guessing at the cut off part of the distribution of study effects.
Methods for detecting publication bias have been controversial as they typically have low power for detection of bias, but also may create false positives under some circumstances.[18] For instance small study effects, wherein methodological differences between smaller and larger studies exist, may cause differences in effect sizes between studies that resemble publication bias. However, small study effects may be just as problematic for the interpretation of meta-analyses, and the imperative is on meta-analytic authors to investigate potential sources of bias. A Tandem Method for analyzing publication bias has been suggested for cutting down false positive error problems.[19] This Tandem method consists of three stages. Firstly, one calculates Orwin's fail-safe N, to check how many studies should be added in order to reduce the test statistic to a trivial size. If this number of studies is larger than the number of studies used in the meta-analysis, it is a sign that there is no publication bias, as in that case, one needs a lot of studies to reduce the effect size. Secondly, one can do an Egger's regression test, which tests whether the funnel plot is symmetrical. As mentioned before: a symmetrical funnel plot is a sign that there is no publication bias, as the effect size and sample size are not dependent. Thirdly, one can do the trim-and-fill method, which imputes data if the funnel plot is asymmetrical. Important to note is that these are just a couple of methods that can be used, but several more exist.
Nevertheless, it is suggested that 25% of meta-analyses in the psychological sciences may have publication bias.[19] However, low power problems likely remain at issue, and estimations of publication bias may remain lower than the true amount.
Most discussions of publication bias focus on journal practices favoring publication of statistically significant finds. However, questionable research practices, such as reworking statistical models until significance is achieved, may also favor statistically significant findings in support of researchers' hypotheses[20][21] Questionable researcher practices aren't necessarily sample size dependent, and as such are unlikely to be evident on a funnel plot and may go undetected by most publication bias detection methods currently in use.
Other weaknesses are Simpson's paradox (two smaller studies may point in one direction, and the combination study in the opposite direction) and subjectivity in the coding of an effect or decisions about including or rejecting studies.[22] There are two different ways to measure effect: correlation or standardized mean difference. The interpretation of effect size is arbitrary, and there is no universally agreed upon way to weigh the risk. It has not been determined if the statistically most accurate method for combining results is the fixed, random or quality effect models.
Agenda-driven bias
The most severe fault in meta-analysis[23] often occurs when the person or persons doing the meta-analysis have an economic, social, or political agenda such as the passage or defeat of legislation. People with these types of agendas may be more likely to abuse meta-analysis due to personal bias. For example, researchers favorable to the author's agenda are likely to have their studies cherry-picked while those not favorable will be ignored or labeled as "not credible". In addition, the favored authors may themselves be biased or paid to produce results that support their overall political, social, or economic goals in ways such as selecting small favorable data sets and not incorporating larger unfavorable data sets. The influence of such biases on the results of a meta-analysis is possible because the methodology of meta-analysis is highly malleable.[22]
A 2011 study done to disclose possible conflicts of interests in underlying research studies used for medical meta-analyses reviewed 29 meta-analyses and found that conflicts of interests in the studies underlying the meta-analyses were rarely disclosed. The 29 meta-analyses included 11 from general medicine journals, 15 from specialty medicine journals, and three from the Cochrane Database of Systematic Reviews. The 29 meta-analyses reviewed a total of 509 randomized controlled trials (RCTs). Of these, 318 RCTs reported funding sources, with 219 (69%) receiving funding from industry. Of the 509 RCTs, 132 reported author conflict of interest disclosures, with 91 studies (69%) disclosing one or more authors having financial ties to industry. The information was, however, seldom reflected in the meta-analyses. Only two (7%) reported RCT funding sources and none reported RCT author-industry ties. The authors concluded "without acknowledgment of COI due to industry funding or author industry financial ties from RCTs included in meta-analyses, readers’ understanding and appraisal of the evidence from the meta-analysis may be compromised."[24]
Steps in a meta-analysis
- Formulation of the problem
- Search of literature
- Selection of studies ('incorporation criteria')
- Based on quality criteria, e.g. the requirement of randomization and blinding in a clinical trial
- Selection of specific studies on a well-specified subject, e.g. the treatment of breast cancer.
- Decide whether unpublished studies are included to avoid publication bias (file drawer problem)
- Decide which dependent variables or summary measures are allowed. For instance:
- Differences (discrete data)
- Means (continuous data)
- Hedges' g is a popular summary measure for continuous data that is standardized in order to eliminate scale differences, but it incorporates an index of variation between groups:
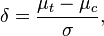 in which
in which 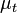 is the treatment mean,
is the treatment mean, 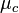 is the control mean,
is the control mean, 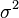 the pooled variance.
the pooled variance.
- Selection of a meta-regression statistical model: e.g. simple regression, fixed-effect meta-regression or random-effect meta-regression. Meta-regression is a tool used in meta-analysis to examine the impact of moderator variables on study effect size using regression-based techniques. Meta-regression is more effective at this task than are standard regression techniques.
For reporting guidelines, see the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) statement.[25]
Methods and assumptions
Approaches
In general, two types of evidence can be distinguished when performing a meta-analysis: Individual Participant Data (IPD) and Aggregate Data (AD). Whereas IPD represents raw data as collected by the study centers, AD is more commonly available (e.g. from the literature) and typically represents summary estimates such as odds ratios or relative risks. This distinction has raised the needs for different meta-analytic methods when evidence synthesis is desired, and has led to the development of one-stage and two-stage methods. In one-stage methods the IPD from all studies are modeled simultaneously whilst accounting for the clustering of participants within studies. Conversely, two-stage methods synthesize the AD from each study and hereto consider study weights. By reducing IPD to AD, two-stage methods can also be applied when IPD is available; this makes them an appealing choice when performing a meta-analysis. Although it is conventionally believed that one-stage and two-stage methods yield similar results, recent studies have shown that they may occasionally lead to different conclusions.[26]
Statistical models
Fixed effects model
The fixed effect model provides a weighted average of a series of study estimates. The inverse of the estimates' variance is commonly used as study weight, such that larger studies tend to contribute more than smaller studies to the weighted average. Consequently, when studies within a meta-analysis are dominated by a very large study, the findings from smaller studies are practically ignored.[27] Most importantly, the fixed effects model assumes that all included studies investigate the same population, use the same variable and outcome definitions, etc. This assumption is typically unrealistic as research is often prone to several sources of heterogeneity; e.g. treatment effects may differ according to locale, dosage levels, study conditions, ...
Random effects model
A common model used to synthesize heterogeneous research is the random effects model of meta-analysis. This is simply the weighted average of the effect sizes of a group of studies. The weight that is applied in this process of weighted averaging with a random effects meta-analysis is achieved in two steps:[28]
- Step 1: Inverse variance weighting
- Step 2: Un-weighting of this inverse variance weighting by applying a random effects variance component (REVC) that is simply derived from the extent of variability of the effect sizes of the underlying studies.
This means that the greater this variability in effect sizes (otherwise known as heterogeneity), the greater the un-weighting and this can reach a point when the random effects meta-analysis result becomes simply the un-weighted average effect size across the studies. At the other extreme, when all effect sizes are similar (or variability does not exceed sampling error), no REVC is applied and the random effects meta-analysis defaults to simply a fixed effect meta-analysis (only inverse variance weighting).
The extent of this reversal is solely dependent on two factors:[29]
- Heterogeneity of precision
- Heterogeneity of effect size
Since neither of these factors automatically indicates a faulty larger study or more reliable smaller studies, the re-distribution of weights under this model will not bear a relationship to what these studies actually might offer. Indeed, it has been demonstrated that redistribution of weights is simply in one direction from larger to smaller studies as heterogeneity increases until eventually all studies have equal weight and no more redistribution is possible.[29] Another issue with the random effects model is that the most commonly used confidence intervals generally do not retain their coverage probability above the specified nominal level and thus substantially underestimate the statistical error and are potentially overconfident in their conclusions.[30][31] Several fixes have been suggested[32][33] but the debate continues on.[31][34] A further concern is that the average treatment effect can sometimes be even less conservative compared to the fixed effect model[35] and therefore misleading in practice. One interpretational fix that has been suggested is to create a prediction interval around the random effects estimate to portray the range of possible effects in practice.[36] However, an assumption behind the calculation of such a prediction interval is that trials are considered more or less homogeneous entities and that included patient populations and comparator treatments should be considered exchangeable[37] and this is usually unattainable in practice.
The most widely used method to estimate between studies variance (REVC) is the DerSimonian-Laird (DL) approach.[38] Several advanced iterative (and computationally expensive) techniques for computing the between studies variance exist (such as maximum likelihood, profile likelihood and restricted maximum likelihood methods) and random effects models using these methods can be run in Stata with the metaan command.[39] The metaan command must be distinguished from the classic metan (single "a") command in Stata that uses the DL estimator. These advanced methods have also been implemented in a free and easy to use Microsoft Excel add-on, MetaEasy.[40][41] However, a comparison between these advanced methods and the DL method of computing the between studies variance demonstrated that there is little to gain and DL is quite adequate in most scenarios.[42][43]
However, most meta-analyses include between 2-4 studies and such a sample is more often than not inadequate to accurately estimate heterogeneity. Thus it appears that in small meta-analyses, an incorrect zero between study variance estimate is obtained, leading to a false homogeneity assumption. Overall, it appears that heterogeneity is being consistently underestimated in meta-analyses and sensitivity analyses in which high heterogeneity levels are assumed could be informative.[44] These random effects models and software packages mentioned above relate to study-aggregate meta-analyses and researchers wishing to conduct individual patient data (IPD) meta-analyses need to consider mixed-effects modelling approaches.[45]
Quality effects model
Doi and Thalib originally introduced the quality effects model.[46] They [47] introduce a new approach to adjustment for inter-study variability by incorporating the contribution of variance due to a relevant component (quality) in addition to the contribution of variance due to random error that is used in any fixed effects meta-analysis model to generate weights for each study. The strength of the quality effects meta-analysis is that it allows available methodological evidence to be used over subjective random effects, and thereby helps to close the damaging gap which has opened up between methodology and statistics in clinical research. To do this a synthetic bias variance is computed based on quality information to adjust inverse variance weights and the quality adjusted weight of the ith study is introduced.[46] These adjusted weights are then used in meta-analysis. In other words, if study i is of good quality and other studies are of poor quality, a proportion of their quality adjusted weights is mathematically redistributed to study i giving it more weight towards the overall effect size. As studies become increasingly similar in terms of quality, re-distribution becomes progressively less and ceases when all studies are of equal quality (in the case of equal quality, the quality effects model defaults to the IVhet model - see next section). A recent evaluation of the quality effects model (with some updates) demonstrates that despite the subjectivity of quality assessment, the performance (MSE and true variance under simulation) is superior to that achievable with the random effects model.[48] This model thus replaces the untenable interpretations that abound in the literature and a software is available to explore this method further.[49]
IVhet model
Doi & Barendregt working in collaboration with Khan, Thalib and Williams (from the University of Queensland, University of Southern Queensland and Kuwait University), have created an inverse variance quasi likelihood based alternative (IVhet) to the random effects (RE) model for which details are available online.[50] This was incorporated into MetaXL version 2.0,[49] a free Microsoft excel add-in for meta-analysis produced by Epigear International Pty Ltd, and made available on 5 April 2014. The authors state that a clear advantage of this model is that it resolves the two main problems of the random effects model. The first advantage of the IVhet model is that coverage remains at the nominal (usually 95%) level for the confidence interval unlike the random effects model which drops in coverage with increasing heterogeneity.[30][31] The second advantage is that the IVhet model maintains the inverse variance weights of individual studies, unlike the RE model which gives small studies more weight (and therefore larger studies less) with increasing heterogeneity. When heterogeneity becomes large, the individual study weights under the RE model become equal and thus the RE model returns an arithmetic mean rather than a weighted average and this seems unjustified. This presumably unintended side-effect of the RE model is avoided by the IVhet model which thus differs from the RE model estimate in two perspectives:[50] Pooled estimates will favor larger trials (as opposed to penalizing larger trials in the RE model) and will have a confidence interval that remains within the nominal coverage under uncertainty (heterogeneity). Doi & Barendregt suggest that while the RE model provides an alternative method of pooling the study data, their simulation results (on the Epigear website[49]) demonstrates that using a more specified probability model with untenable assumptions, as with the RE model, does not necessarily provide better results. Researchers can now access this new IVhet model through MetaXL[49] for further evaluation and comparison with the conventional random effects model.
Applications in modern science
Modern statistical meta-analysis does more than just combine the effect sizes of a set of studies using a weighted average. It can test if the outcomes of studies show more variation than the variation that is expected because of the sampling of different numbers of research participants. Additionally, study characteristics such as measurement instrument used, population sampled, or aspects of the studies' design can be coded and used to reduce variance of the estimator (see statistical models above). Thus some methodological weaknesses in studies can be corrected statistically. Other uses of meta-analytic methods include the development of clinical prediction models, where meta-analysis may be used to combine data from different research centers,[51] or even to aggregate existing prediction models.[52]
Meta-analysis can be done with single-subject design as well as group research designs. This is important because much research has been done with single-subject research designs. Considerable dispute exists for the most appropriate meta-analytic technique for single subject research.[53]
Meta-analysis leads to a shift of emphasis from single studies to multiple studies. It emphasizes the practical importance of the effect size instead of the statistical significance of individual studies. This shift in thinking has been termed "meta-analytic thinking". The results of a meta-analysis are often shown in a forest plot.
Results from studies are combined using different approaches. One approach frequently used in meta-analysis in health care research is termed 'inverse variance method'. The average effect size across all studies is computed as a weighted mean, whereby the weights are equal to the inverse variance of each studies' effect estimator. Larger studies and studies with less random variation are given greater weight than smaller studies. Other common approaches include the Mantel–Haenszel method[54] and the Peto method.
A recent approach to studying the influence that weighting schemes can have on results has been proposed through the construct of gravity, which is a special case of combinatorial meta-analysis.
Signed differential mapping is a statistical technique for meta-analyzing studies on differences in brain activity or structure which used neuroimaging techniques such as fMRI, VBM or PET.
Different high throughput techniques such as microarrays have been used to understand Gene expression. MicroRNA expression profiles have been used to identify differentially expressed microRNAs in particular cell or tissue type or disease conditions or to check the effect of a treatment. A meta-analysis of such expression profiles was performed to derive novel conclusions and to validate the known findings.[55]
See also
- Estimation statistics
- Newcastle–Ottawa scale
- Reporting bias
- Review journal
- Secondary research
- Study heterogeneity
- Systematic review
- Galbraith plot
References
- ↑ Greenland S, O' Rourke K: Meta-Analysis. Page 652 in Modern Epidemiology, 3rd ed. Edited by Rothman KJ, Greenland S, Lash T. Lippincott Williams and Wilkins; 2008.
- ↑ WALKER, E.; HERNANDEZ, A. V.; KATTAN, M. W. (1 June 2008). "Meta-analysis: Its strengths and limitations". Cleveland Clinic Journal of Medicine 75 (6): 431–439. doi:10.3949/ccjm.75.6.431.
- ↑ Glossary at Cochrane Collaboration
- ↑ Pearson K (1904). "Report on certain enteric fever inoculation statistics". BMJ 3 (2288): 1243–1246. PMC 2355479. PMID 20761760.
- ↑ Nordmann AJ, Kasenda B, Briel M (Mar 9, 2012). "Meta-analyses: what they can and cannot do". Swiss medical weekly 142: w13518. doi:10.4414/smw.2012.13518. PMID 22407741.
- ↑ O'Rourke K (2007-12-01). "An historical perspective on meta-analysis: dealing quantitatively with varying study results". J R Soc Med 100 (12): 579–582. doi:10.1258/jrsm.100.12.579. PMC 2121629. PMID 18065712. Retrieved 2009-09-10.
- ↑ Bösch, H. (2004). Reanalyzing a meta-analysis on extra-sensory perception dating from 1940, the first comprehensive meta-analysis in the history of science. In S. Schmidt (Ed.), Proceedings of the 47th Annual Convention of the Parapsychological Association, University of Vienna, (pp. 1–13)
- ↑ Glass G. V (1976). "Primary, secondary, and meta-analysis of research". Educational Researcher 5 (10): 3–8. doi:10.3102/0013189X005010003.
- ↑ Cochran WG (1937). "Problems Arising in the Analysis of a Series of Similar Experiments". Journal of the Royal Statistical Society 4: 102–118. doi:10.2307/2984123.
- ↑ Cochran WG, Carroll SP (1953). "A Sampling Investigation of the Efficiency of Weighting Inversely as the Estimated Variance". Biometrics 9: 447–459. doi:10.2307/3001436.
- ↑ LeLorier J, Grégoire G, Benhaddad A, Lapierre J, Derderian F (1997). "Discrepancies between Meta-Analyses and Subsequent Large Randomized, Controlled Trials". New England Journal of Medicine 337 (8): 536–542. doi:10.1056/NEJM199708213370806. PMID 9262498.
- ↑ 12.0 12.1 Slavin RE (1986). "Best-Evidence Synthesis: An Alternative to Meta-Analytic and Traditional Reviews". Educational Researcher 15 (9): 5–9. doi:10.3102/0013189X015009005.
- ↑ Hunter, Schmidt, & Jackson, John E. (1982). Meta-analysis: Cumulating research findings across studies. Beverly Hills, California: Sage.
- ↑ Glass, McGaw, & Smith (1981). Meta-analysis in social research. Beverly Hills, CA: Sage.
- ↑ 15.0 15.1 Rosenthal R (1979). "The "File Drawer Problem" and the Tolerance for Null Results". Psychological Bulletin 86 (3): 638–641. doi:10.1037/0033-2909.86.3.638.
- ↑ Hunter, John E; Schmidt, Frank L (1990). Methods of Meta-Analysis: Correcting Error and Bias in Research Findings. Newbury Park, California; London; New Delhi: SAGE Publications.
- ↑ Light & Pillemer (1984). Summing up: The science of reviewing research. Cambridge, CA: Harvard University Pree.
- ↑ Ioannidis JP, Trikalinos TA (2007). "The appropriateness of asymmetry tests for publication bias in meta-analyses: a large survey". CMAJ 176 (8): 1091–6. doi:10.1503/cmaj.060410. PMC 1839799. PMID 17420491.
- ↑ 19.0 19.1 Ferguson CJ, Brannick MT (2012). "Publication bias in psychological science: prevalence, methods for identifying and controlling, and implications for the use of meta-analyses". Psychol Methods 17 (1): 120–8. doi:10.1037/a0024445. PMID 21787082.
- ↑ Simmons JP, Nelson LD, Simonsohn U (2011). "False-positive psychology: undisclosed flexibility in data collection and analysis allows presenting anything as significant". Psychol Sci 22 (11): 1359–66. doi:10.1177/0956797611417632. PMID 22006061.
- ↑ LeBel, E. & Peters, K. (2011). "Fearing the future of empirical psychology: Bem's (2011) evidence of psi as a case study of deficiencies in modal research practice" (PDF). Review of General Psychology 15 (4): 371–379. doi:10.1037/a0025172.
- ↑ 22.0 22.1 Stegenga J (2011). "Is meta-analysis the platinum standard of evidence?". Stud Hist Philos Biol Biomed Sci 42 (4): 497–507. doi:10.1016/j.shpsc.2011.07.003. PMID 22035723.
- ↑ H. Sabhan
- ↑ "How Well Do Meta-Analyses Disclose Conflicts of Interests in Underlying Research Studies | The Cochrane Collaboration". Cochrane.org. Retrieved 2012-01-13.
- ↑ "The PRISMA statement". Prisma-statement.org. 2012-02-02. Retrieved 2012-02-02.
- ↑ Debray TP, Moons KG, Abo-Zaid GM, Koffijberg H, Riley RD (2013). "Individual participant data meta-analysis for a binary outcome: one-stage or two-stage?". PLoS ONE 8 (4): e60650. doi:10.1371/journal.pone.0060650. PMC 3621872. PMID 23585842.
- ↑ Helfenstein U (2002). "Data and models determine treatment proposals--an illustration from meta-analysis". Postgrad Med J 78 (917): 131–4. doi:10.1136/pmj.78.917.131. PMC 1742301. PMID 11884693.
- ↑ Senn S (2007). "Trying to be precise about vagueness". Stat Med 26: 1417–30. doi:10.1002/sim.2639.
- ↑ 29.0 29.1 Al Khalaf MM, Thalib L, Doi SA (2011). "Combining heterogenous studies using the random-effects model is a mistake and leads to inconclusive meta-analyses" (PDF). Journal of Clinical Epidemiology 64: 119–23. doi:10.1016/j.jclinepi.2010.01.009.
- ↑ 30.0 30.1 Brockwell S.E., Gordon I.R. (2001). "A comparison of statistical methods for meta-analysis". Statistics in Medicine 20: 825–840. doi:10.1002/sim.650.
- ↑ 31.0 31.1 31.2 Noma H (Dec 2011). "Confidence intervals for a random-effects meta-analysis based on Bartlett-type corrections". Stat Med. 30 (28): 3304–12. doi:10.1002/sim.4350.
- ↑ Brockwell SE, Gordon IR (2007). "A simple method for inference on an overall effect in meta-analysis". Statistics in Medicine 26: 4531–4543. doi:10.1002/sim.2883.
- ↑ Sidik K, Jonkman JN (2002). "A simple confidence interval for meta-analysis". Statistics in Medicine 21: 3153–3159. doi:10.1002/sim.1262.
- ↑ Jackson D, Bowden J (2009). "A re-evaluation of the 'quantile approximation method' for random effects meta-analysis". Stat Med 28 (2): 338–48. doi:10.1002/sim.3487. PMC 2991773. PMID 19016302.
- ↑ Poole C, Greenland S (Sep 1999). "Random-effects meta-analyses are not always conservative". Am J Epidemiol 150 (5): 469–75. doi:10.1093/oxfordjournals.aje.a010035.
- ↑ Riley RD, Higgins JP, Deeks JJ. (2011) "Interpretation of random effects meta-analyses". British Medical Journal 342:d549. doi:10.1136/bmj.d549
- ↑ Kriston L (2013). "Dealing with clinical heterogeneity in meta-analysis. Assumptions, methods, interpretation". Int J Methods Psychiatr Res 22 (1): 1–15. doi:10.1002/mpr.1377. PMID 23494781.
- ↑ DerSimonian R, Laird N (1986). "Meta-analysis in clinical trials". Control Clin Trials 7 (3): 177–88. doi:10.1016/0197-2456(86)90046-2. PMID 3802833.
- ↑ metaan:Random-effects meta-analysis, Stata Journal 2010
- ↑ MetaEasy:A Meta-Analysis Add-In for Microsoft Excel, Journal of Statistical Software 2009
- ↑ Developer's website
- ↑ Kontopantelis E, Reeves D (2012). "Performance of statistical methods for meta-analysis when true study effects are non-normally distributed: A simulation study.". Statistical Methods in Medical Research 21 (4): 409–26. doi:10.1177/0962280210392008. PMID 21148194.
- ↑ Kontopantelis E, Reeves D (2012). "Performance of statistical methods for meta-analysis when true study effects are non-normally distributed: a comparison between DerSimonian-Laird and restricted maximum likelihood". SMMR 21 (6): 657–9. doi:10.1177/0962280211413451. PMID 23171971.
- ↑ Kontopantelis E, Springate DA, Reeves D (2013). Friede, Tim, ed. "A Re-Analysis of the Cochrane Library Data: The Dangers of Unobserved Heterogeneity in Meta-Analyses". PLoS ONE 8 (7): e69930. doi:10.1371/journal.pone.0069930. PMC 3724681. PMID 23922860.
- ↑ A short guide and a forest plot command (ipdforest) for one-stage meta-analysis, Stata Journal 2012
- ↑ 46.0 46.1 Doi SA, Thalib L (2008). "A quality-effects model for meta-analysis". Epidemiology 19 (1): 94–100. doi:10.1097/EDE.0b013e31815c24e7. PMID 18090860.
- ↑ Doi SA, Barendregt JJ, Mozurkewich EL (2011). "Meta-analysis of heterogeneous clinical trials: an empirical example". Contemp Clin Trials 32 (2): 288–98.
- ↑ Doi SA, Barendregt JJ, Williams GM, Khan S, Thalib L. Simulation Comparison of the Quality Effects and Random Effects Methods of Meta-analysis. Epidemiology. 2015 Apr 11. [Epub ahead of print] PubMed PMID 25872162
- ↑ 49.0 49.1 49.2 49.3 MetaXL software page
- ↑ 50.0 50.1 MetaXL User Guide
- ↑ Debray TP, Moons KG, Ahmed I, Koffijberg H, Riley RD (2013). "A framework for developing, implementing, and evaluating clinical prediction models in an individual participant data meta-analysis". Statistics in Medicine 32 (18): 3158–80. doi:10.1002/sim.5732. PMID 23307585.
- ↑ Debray TP, Koffijberg H, Vergouwe Y, Moons KG, Steyerberg EW (2012). "Aggregating published prediction models with individual participant data: a comparison of different approaches". Statistics in Medicine 31 (23): 2697–2712. doi:10.1002/sim.5412. PMID 22733546.
- ↑ Van den Noortgate W, Onghena P (2007). "Aggregating Single-Case Results". The Behavior Analyst Today 8 (2): 196–209. doi:10.1037/h0100613.
- ↑ Mantel N, Haenszel W (1959). "Statistical aspects of the analysis of data from the retrospective analysis of disease". Journal of the National Cancer Institute 22 (4): 719–748. doi:10.1093/jnci/22.4.719. PMID 13655060.
- ↑ Bargaje R, Hariharan M, Scaria V, Pillai B (2010). "Consensus miRNA expression profiles derived from interplatform normalization of microarray data". RNA 16 (1): 16–25. doi:10.1261/rna.1688110. PMC 2802026. PMID 19948767.
Further reading
- Cooper, H. & Hedges, L.V. (1994). The Handbook of Research Synthesis. New York: Russell Sage.
- Cornell, J. E. & Mulrow, C. D. (1999). Meta-analysis. In: H. J. Adèr & G. J. Mellenbergh (Eds). Research Methodology in the social, behavioral and life sciences (pp. 285–323). London: Sage.
- Normand SL (1999). "Tutorial in Biostatistics. Meta-Analysis: Formulating, Evaluating, Combining, and Reporting". Statistics in Medicine 18 (3): 321–359. doi:10.1002/(SICI)1097-0258(19990215)18:3<321::AID-SIM28>3.0.CO;2-P. PMID 10070677.
- Sutton, A.J., Jones, D.R., Abrams, K.R., Sheldon, T.A., & Song, F. (2000). Methods for Meta-analysis in Medical Research. London: John Wiley. ISBN 0-471-49066-0
- Higgins JPT, Green S (editors). Cochrane Handbook for Systematic Reviews of Interventions Version 5.0.1 [updated September 2008]. The Cochrane Collaboration, 2008. Available from www.cochrane-handbook.org
- Thompson SG, Pocock SJ; Pocock, Stuart J (2 November 1991). "Can meta-analysis be trusted?" (PDF). The Lancet 338 (8775): 1127–1130. doi:10.1016/0140-6736(91)91975-Z. PMID 1682553. Retrieved 17 June 2011.. Explores two contrasting views: does meta-analysis provide "objective, quantitative methods for combining evidence from separate but similar studies" or merely "statistical tricks which make unjustified assumptions in producing oversimplified generalisations out of a complex of disparate studies"?
- Wilson, D. B., & Lipsey, M. W. (2001). Practical meta-analysis. Thousand Oaks: Sage publications. ISBN 0-7619-2168-0
- O'Rourke, K. (2007) Just the history from the combining of information: investigating and synthesizing what is possibly common in clinical observations or studies via likelihood. Oxford: University of Oxford, Department of Statistics. Gives technical background material and details on the "An historical perspective on meta-analysis" paper cited in the references.
- Owen, A. B. (2009). "Karl Pearson's meta-analysis revisited". Annals of Statistics, 37 (6B), 3867–3892. Supplementary report.
- Ellis, Paul D. (2010). The Essential Guide to Effect Sizes: An Introduction to Statistical Power, Meta-Analysis and the Interpretation of Research Results. United Kingdom: Cambridge University Press. ISBN 0-521-14246-6
- Bonett DG, Price RM (2014). "Meta-analysis methods for risk differences". Br J Math Stat Psychol 67 (3): 371–87. doi:10.1111/bmsp.12024. PMID 23962020.
- Bonett DG (2010). "Varying coefficient meta-analytic methods for alpha reliability". Psychol Methods 15 (4): 368–85. doi:10.1037/a0020142. PMID 20853952.
- Bonett DG (2009). "Meta-analytic interval estimation for standardized and unstandardized mean differences". Psychol Methods 14 (3): 225–38. doi:10.1037/a0016619. PMID 19719359.
- Bonett DG (2008). "Meta-analytic interval estimation for bivariate correlations". Psychol Methods 13 (3): 173–81. doi:10.1037/a0012868. PMID 18778150.
- Maniadis, Z et al. (2014). "One Swallow Doesn’t Make a Summer: Reply to Kataria". Econ Journal Watch 11 (1): 11–16.
External links
| Wikiversity has learning materials about Meta-analysis |
- Cochrane Handbook for Systematic Reviews of Interventions
- Effect Size and Meta-Analysis (ERIC Digest)
- Meta-Analysis at 25 (Gene V Glass)
- Meta-Analysis in Educational Research (ERIC Digest)
- Meta-Analysis: Methods of Accumulating Results Across Research Domains (article by Larry Lyons)
- Meta-analysis (Psychwiki.com article)
- EffectSizeFAQ.com
- Meta-Analysis in Economics (Reading list)
- Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) Statement, "an evidence-based minimum set of items for reporting in systematic reviews and meta-analyses."
- Meta-analysis glossary
Software
- MetaXL software page
- Effect Size Calculators Calculate d and r from a variety of statistics.
- ClinTools (commercial)
- Comprehensive Meta-Analysis (commercial)
- MIX 2.0 Professional Excel addin with Ribbon interface for meta-analysis and effect size conversions in Excel (free and commercial versions).
- NCSS (commercial)
- MetaEasy, Journal of Statistical software 2009 Microsoft Excel add-in for data collection and advanced random-effects models (free).
- What meta-analysis features are available in Stata? (free add-ons to commercial package)
- metaan package, Stata Journal 2010 Advanced random-effects modelling in Stata (free add-on to commercial package).
- metaeff package Effect size calculator in Stata (free add-on to commercial package).
- ipdforest package, Stata Journal 2012 Individual patient data meta-analysis models (free add-on to commercial package)
- The Meta-Analysis Calculator free on-line tool for conducting a meta-analysis
- Metastat (Free)
- METAINTER meta-analysis for multiple regression models in genome-wide association studies
- OpenMetaAnalyst Free, open source, cross-platform (Mac and Windows) software for meta-analysis.
- ProMeta Professional software for meta-analysis developed in Java (commercial)
- Revman A free software for meta-analysis and preparation of cochrane protocols and review available from the Cochrane Collaboration
- Metafor-project A free software package to conduct meta-analyses in R.
- Calculation of fixed and random effects in R source code for performing univariate and multivariate meta-analyses in R, and for calculating several statistics of heterogeneity.
- Macros in SPSS Free Macros to conduct meta-analyses in SPSS.
- compute.es: Compute Effect Sizes (R package).
- Graphical User Interface for Conducting Meta-Analyses in R User friendly graphical user interface package to conduct meta-analysis in R (Free).
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||