Matrix norm
In mathematics, a matrix norm is a natural extension of the notion of a vector norm to matrices.
Definition
In what follows, 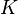 will denote the field of real or complex numbers. Let
will denote the field of real or complex numbers. Let 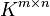 denote the vector space containing all matrices with
denote the vector space containing all matrices with 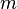 rows and
rows and  columns with entries in . Throughout the article
columns with entries in . Throughout the article 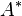 denotes the conjugate transpose of matrix
denotes the conjugate transpose of matrix 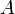 .
.
A matrix norm is a vector norm on . That is, if 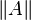 denotes the norm of the matrix , then,
denotes the norm of the matrix , then,

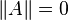 iff
iff 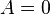
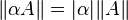 for all
for all 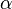 in and all matrices in
in and all matrices in  for all matrices and
for all matrices and 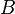 in
in 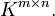
Additionally, in the case of square matrices (thus, m = n), some (but not all) matrix norms satisfy the following condition, which is related to the fact that matrices are more than just vectors:
 for all matrices and in
for all matrices and in 
A matrix norm that satisfies this additional property is called a sub-multiplicative norm (in some books, the terminology matrix norm is used only for those norms which are sub-multiplicative). The set of all n-by-n matrices, together with such a sub-multiplicative norm, is an example of a Banach algebra.
Induced norm
If vector norms on Km and Kn are given (K is field of real or complex numbers), then one defines the corresponding induced norm or operator norm on the space of m-by-n matrices as the following maxima:
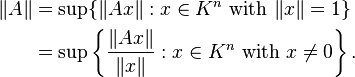
The operator norm corresponding to the p-norm for vectors is:
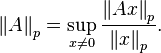
These are different from the entrywise p-norms and the Schatten p-norms for matrices treated below, which are also usually denoted
by 
In the case of 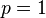 and
and  , the norms can be computed as:
, the norms can be computed as:
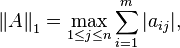 which is simply the maximum absolute column sum of the matrix.
which is simply the maximum absolute column sum of the matrix.
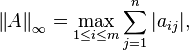 which is simply the maximum absolute row sum of the matrix
which is simply the maximum absolute row sum of the matrix
For example, if the matrix A is defined by
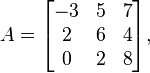
then we have ||A||1 = max(|-3|+2+0, 5+6+2, 7+4+8) = max(5,13,19) = 19. and ||A||∞ = max(|-3|+5+7, 2+6+4,0+2+8) = max(15,12,10) = 15.
In the special case of p = 2 (the Euclidean norm), the induced matrix norm is the spectral norm. The spectral norm of a matrix A is the largest singular value of A i.e. the square root of the largest eigenvalue of the positive-semidefinite matrix A*A:

where A* denotes the conjugate transpose of A.
More generally, one can define the subordinate matrix norm on induced by
 on
on 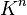 , and
, and 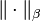 on
on 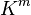 as:
as:

Subordinate norms are consistent with the norms that induce them, giving
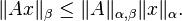
Any induced operator norm is a sub-multiplicative matrix norm since  and
and 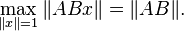 .
.
Any induced norm satisfies the inequality
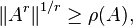
where ρ(A) is the spectral radius of A. For a symmetric or hermitian matrix , we have equality for the 2-norm, since in this case the 2-norm is the spectral radius of . For an arbitrary matrix, we may not have equality for any norm. Take
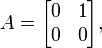
the spectral radius of is 0, but is not the zero matrix, and so none of the induced norms are equal to the spectral radius of .
Furthermore, for square matrices we have the spectral radius formula:
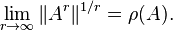
"Entrywise" norms
These vector norms treat an  matrix as a vector of size
matrix as a vector of size  , and
use one of the familiar vector norms.
, and
use one of the familiar vector norms.
For example, using the p-norm for vectors, we get:

This is a different norm from the induced p-norm (see above) and the Schatten p-norm (see below), but the notation is the same.
The special case p = 2 is the Frobenius norm, and p = ∞ yields the maximum norm.
L2,1 norm
Let
 be the columns of matrix
.
The
be the columns of matrix
.
The
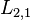 norm [2]
is a sum of Euclidean norm of columns:
norm [2]
is a sum of Euclidean norm of columns:
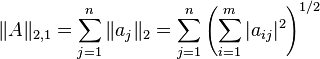
Note here the two indexes 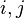 of
of
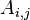 are treated differently; all matrix norms introduced prior to the L2,1 norm treat the two indexes symmetrically.
L2,1 norm is widely used in robust data analysis and sparse coding for feature selection.
are treated differently; all matrix norms introduced prior to the L2,1 norm treat the two indexes symmetrically.
L2,1 norm is widely used in robust data analysis and sparse coding for feature selection.
L2,1 norm is later generalized into 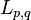 norm
norm
![\Vert A \Vert_{p,q}
= \left[\sum_{j=1}^n \left( \sum_{i=1}^m |a_{ij}|^p \right)^{q/p}\right]^{1/q}](../I/m/696cea3ddaa66676bbd6bb29a05cb208.png)
Frobenius norm
For p = q = 2, this is called the Frobenius norm or the Hilbert–Schmidt norm, though the latter term is often reserved for operators on Hilbert space. This norm can be defined in various ways:
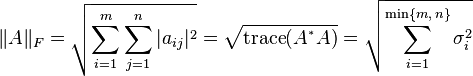
where A* denotes the conjugate transpose of A, σi are the singular values of A, and the trace function is used. The Frobenius norm is similar to the Euclidean norm on Kn and comes from the Frobenius inner product on the space of all matrices.
The Frobenius norm is sub-multiplicative and is very useful for numerical linear algebra. This norm is often easier to compute than induced norms and has the useful property of being invariant under rotations. This property follows easily from the trace definition restricted to real matrices,
 ,
,
where we have used the orthogonal nature of P, 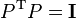 and the cyclic nature of the trace,
and the cyclic nature of the trace,  . More generally the norm is invariant under a unitary transformation for complex matrices.
. More generally the norm is invariant under a unitary transformation for complex matrices.
Max norm
The max norm is the elementwise norm with p = ∞:

This norm is not sub-multiplicative.
Schatten norms
The Schatten p-norms arise when applying the p-norm to the vector of singular values of a matrix. If the singular values are denoted by σi, then the Schatten p-norm is defined by
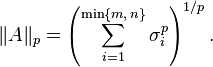
These norms again share the notation with the induced and entrywise p-norms, but they are different.
All Schatten norms are sub-multiplicative. They are also unitarily invariant, which means that ||A|| = ||UAV|| for all matrices A and all unitary matrices U and V.
The most familiar cases are p = 1, 2, ∞. The case p = 2 yields the Frobenius norm, introduced before. The case p = ∞ yields the spectral norm, which is the matrix norm induced by the vector 2-norm (see above). Finally, p = 1 yields the nuclear norm (also known as the trace norm, or the Ky Fan 'n'-norm), defined as

(Here 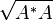 denotes a positive semidefinite matrix such that
denotes a positive semidefinite matrix such that 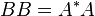 . More precisely, since
. More precisely, since 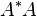 is a positive semidefinite matrix, its square root is well-defined.)
is a positive semidefinite matrix, its square root is well-defined.)
Consistent norms
A matrix norm 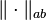 on is called consistent with a vector norm
on is called consistent with a vector norm  on and a vector norm
on and a vector norm  on if:
on if:
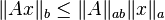
for all  . All induced norms are consistent by definition.
. All induced norms are consistent by definition.
Compatible norms
A matrix norm on 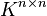 is called compatible with a vector norm on if:
is called compatible with a vector norm on if:
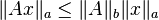
for all 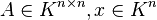 . Induced norms are compatible by definition.
. Induced norms are compatible by definition.
Equivalence of norms
For any two vector norms and , we have
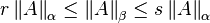
for some positive numbers r and s, for all matrices A in . In other words, all norms on are equivalent; they induce the same topology on . This is true because the vector space has the finite dimension .
Moreover, for every vector norm  on
on 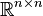 , there exists a unique positive real number
, there exists a unique positive real number 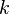 such that
such that 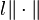 is a sub-multiplicative matrix norm for every
is a sub-multiplicative matrix norm for every 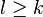 .
.
A sub-multiplicative matrix norm is said to be minimal if there exists no other sub-multiplicative matrix norm satisfying 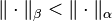 .
.
Examples of norm equivalence
For matrix 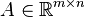 of rank
of rank  , the following inequalities hold:[3][4]
, the following inequalities hold:[3][4]
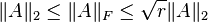
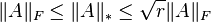

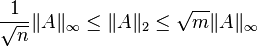

Here,  refers to the matrix norm induced by the vector p-norm.
refers to the matrix norm induced by the vector p-norm.
Another useful inequality between matrix norms is
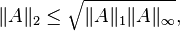
which is a special case of Hölder's inequality.
Notes
- ↑ Carl D. Meyer, Matrix Analysis and Applied Linear Algebra,section 5.2,p281, Society for Industrial & Applied Mathematics,June 2000.
- ↑ C. Ding, D. Zhou, X. He, H. Zha, "R1-PCA: Rotational Invariant L1-norm Principal Component Analysis for Robust Subspace Factorization", Proc. of Int'l Conf. Machine Learning (ICML 2006), June 2006.
- ↑ Golub, Gene; Charles F. Van Loan (1996). Matrix Computations - Third Edition. Baltimore: The Johns Hopkins University Press, 56-57. ISBN 0-8018-5413-X.
- ↑ Roger Horn and Charles Johnson. Matrix Analysis, Chapter 5, Cambridge University Press, 1985. ISBN 0-521-38632-2.
References
- James W. Demmel, Applied Numerical Linear Algebra, section 1.7, published by SIAM, 1997.
- Carl D. Meyer, Matrix Analysis and Applied Linear Algebra, published by SIAM, 2000.
- John Watrous, Theory of Quantum Information, 2.3 Norms of operators, lecture notes, University of Waterloo, 2011.
- Kendall Atkinson, An Introduction to Numerical Analysis, published by John Wiley & Sons, Inc 1989