Markov kernel
In probability theory, a Markov kernel (or stochastic kernel) is a map that plays the role, in the general theory of Markov processes, that the transition matrix does in the theory of Markov processes with a finite state space.[1][2]
Formal definition
Let 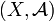 ,
, 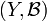 be measurable spaces. A Markov kernel with source and target is a map
be measurable spaces. A Markov kernel with source and target is a map ![\kappa \colon X \times \mathcal B \to [0,1]](../I/m/5a91b8a2a886c3d35a2c8a22946fdf11.png) with the following properties:
with the following properties:
- The map
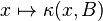 is
is 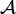 - measureable for every
- measureable for every 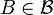 .
. - The map
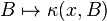 is a probability measure on
is a probability measure on 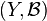 for every
for every 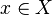 .
.
(i.e. It associates to each point a probability measure 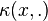 on such that, for every measurable set
on such that, for every measurable set 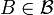 , the map is measurable with respect to the
, the map is measurable with respect to the 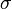 -algebra .)
-algebra .)
Examples
- Simple random walk: Take
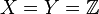 and
and 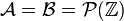 , then the Markov kernel
, then the Markov kernel 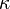 with
with
-
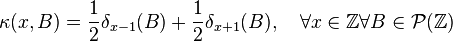 ,
,
describes the transition rule for the random walk on 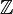 .
.
- Galton-Watson process: Take
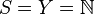 ,
, 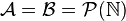 , then
, then
![\kappa(x,B)=\begin{cases}
\delta_0(B) & \quad x=0,\\
P[\xi_1 + \dots + \xi_x \in B] & \quad \text{else,}\\
\end{cases}](../I/m/85139911e2c6f611b4641ea10a56f238.png)
with i.i.d. random variables  .
.
- General Markov processes with finite state space: Take
 ,
, 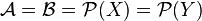 and
and 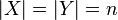 , then the transition rule can be represented as a stochastic matrix
, then the transition rule can be represented as a stochastic matrix 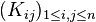 with
with 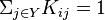 for every
for every 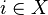 . In the convention of Markov kernels we write
. In the convention of Markov kernels we write
-
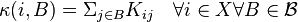 .
.
Properties
Semidirect product
Let 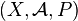 be a probability space and a Markov kernel
from
be a probability space and a Markov kernel
from 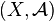 to some . Then there exists a unique
measure
to some . Then there exists a unique
measure 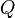 on
on 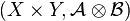 , s.t.
, s.t.
-
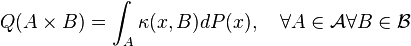 .
.
Regular conditional distribution
Let 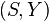 be a Borel space,
be a Borel space, 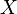 a - valued random variable on the measure space
a - valued random variable on the measure space 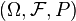 and
and 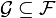 a sub--algebra.
Then there exists a Markov kernel from
a sub--algebra.
Then there exists a Markov kernel from 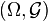 to , s.t.
to , s.t. 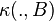 is a version of the conditional expectation
is a version of the conditional expectation ![E[\mathbf 1_{\{X \in B\}}| \mathcal G]](../I/m/ad6b0067e1f6ab4aedcdd0a551563550.png) for every
for every 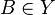 , i.e.
, i.e.
![P[X \in B|\mathcal G]=E[\mathbf 1_{\{X \in B\}}|\mathcal G]=\kappa(\omega,B), \quad P-a.s. \forall B \in \mathcal G](../I/m/f825e79672ef9ea6f84d5f16ff98189e.png) .
.
It is called regular conditional distribution of given 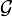 and is not uniquely defined.
and is not uniquely defined.
References
- ↑ Epstein, P.; Howlett, P.; Schulze, M. S. (2003). "Distribution dynamics: Stratification, polarization, and convergence among OECD economies, 1870–1992". Explorations in Economic History 40: 78. doi:10.1016/S0014-4983(02)00023-2.
- ↑ Reiss, R. D. (1993). "A Course on Point Processes". Springer Series in Statistics. doi:10.1007/978-1-4613-9308-5. ISBN 978-1-4613-9310-8.
- Bauer, Heinz (1996), Probability Theory, de Gruyter, ISBN 3-11-013935-9
- §36. Kernels and semigroups of kernels