M-tree
M-trees are tree data structures that are similar to R-trees and B-trees. It is constructed using a metric and relies on the triangle inequality for efficient range and k-NN queries. While M-trees can perform well in many conditions, the tree can also have large overlap and there is no clear strategy on how to best avoid overlap. In addition, it can only be used for distance functions that satisfy the triangle inequality, while many advanced dissimilarity functions used in information retrieval do not satisfy this.[1]
Overview
As in any Tree-based data structure, the M-Tree is composed of Nodes and Leaves. In each node there is a data object that identifies it uniquely and a pointer to a sub-tree where its children reside. Every leaf has several data objects. For each node there is a radius  that defines a Ball in the desired metric space. Thus, every node
that defines a Ball in the desired metric space. Thus, every node  and leaf
and leaf 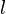 residing in a particular node
residing in a particular node 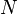 is at most distance from , and every node and leaf with node parent keep the distance from it.
is at most distance from , and every node and leaf with node parent keep the distance from it.
M-Tree construction
Components
An M-Tree has these components and sub-components:
- Non-leaf nodes
- A set of routing objects NRO.
- Pointer to Node's parent object Op.
- Leaf nodes
- A set of objects NO.
- Pointer to Node's parent object Op.
- Routing Object
- (Feature value of) routing object Or.
- Covering radius r(Or).
- Pointer to covering tree T(Or).
- Distance of Or from its parent object d(Or,P(Or))
- Object
- (Feature value of the) object Oj.
- Object identifier oid(Oj).
- Distance of Oj from its parent object d(Oj,P(Oj))
Insert
The main idea is first to find a leaf node where the new object 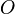 belongs. If is not full then just attach it to . If is full then invoke a method to split . The algorithm is as follows:
belongs. If is not full then just attach it to . If is full then invoke a method to split . The algorithm is as follows:
Algorithm Insert Input: Node, Entry
Output: A new instance of
←
be routing objects from
such that
if
} else { /*If there are no such entry, then look for an object with minimal distance from */ /*its covering radius's edge to the new object*/
/*Upgrade the new radii of the entry*/
=
} /*Continue inserting in the next level*/ return insert(
,
- "←" is a shorthand for "changes to". For instance, "largest ← item" means that the value of largest changes to the value of item.
- "return" terminates the algorithm and outputs the value that follows.
Split
If the split method arrives to the root of the tree, then it choose two routing objects from , and creates two new nodes containing all the objects in original , and store them into the new root. If split methods arrives to a node that is not the root of the tree, the method choose two new routing objects from , re-arrange every routing object in in two new nodes 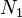 and
and 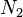 , and store this new nodes in the parent node
, and store this new nodes in the parent node 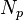 of original . The split must be repeated if has not enough capacity to store . The algorithm is as follow:
of original . The split must be repeated if has not enough capacity to store . The algorithm is as follow:
Algorithm Split Input: Node
/*The new routing objects are now all those in the node plus the new routing object*/ let beentries of
if
be the parent routing object of
/*Promote two routing objects from the node to be split, to be new routing objects*/ Create new objects
and
. Promote(
- "←" is a shorthand for "changes to". For instance, "largest ← item" means that the value of largest changes to the value of item.
- "return" terminates the algorithm and outputs the value that follows.
M-Tree Queries
Range Query
A range query is where a minimum similarity/maximum distance value is specified. For a given query object Q ∈ D and a maximum search distance r(Q), the range query range(Q, r(Q)) selects all the indexed objects Oj such that d(Oj, Q) ≤ r(Q).[2]
Algorithm RangeSearch starts from the root node and recursively traverses all the paths which cannot be excluded from leading to qualifying objects.
Algorithm Insert
Input: Node of M-Tree MT, 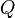 : query object,
: query object, 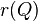 : search radius
: search radius
Output: all the DB objects such that 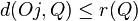
{
let be the parent object of node ;
if is not a leaf then {
for each entry(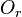 ) in N do {
if
) in N do {
if 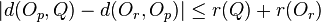 then {
Compute
then {
Compute 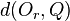 ;
if
;
if 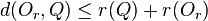 then
RangeSearch(*ptr(
then
RangeSearch(*ptr( )),Q,);
}
}
}
else {
for each entry(
)),Q,);
}
}
}
else {
for each entry( ) in do {
if
) in do {
if 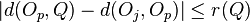 then {
Compute
then {
Compute 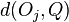 ;
if ≤ then
add
;
if ≤ then
add 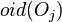 to the result;
}
}
}
}
to the result;
}
}
}
}
- "←" is a shorthand for "changes to". For instance, "largest ← item" means that the value of largest changes to the value of item.
- "return" terminates the algorithm and outputs the value that follows.
is the identifier of the object which resides on a separate data file.
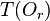 is a sub-tree – the covering tree of
is a sub-tree – the covering tree of
k-NN queries
K Nearest Neighbor (k-NN) query takes the cardinality of the input set as an input parameter. For a given query object Q ∈ D and an integer k ≥ 1, the k-NN query NN(Q, k) selects the k indexed objects which have the shortest distance from Q, according to the distance function d. [2]
See also
- Segment tree
- Interval tree - A degenerate R-Tree for 1 dimension (usually time).
- Bounding volume hierarchy
- Spatial index
- GiST
References
- ↑ Ciaccia, Paolo; Patella, Marco; Zezula, Pavel (1997). "M-tree An Efficient Access Method for Similarity Search in Metric Spaces" (PDF). Proceedings of the 23rd VLDB Conference Athens, Greece, 1997. IBM Almaden Research Center: Very Large Databases Endowment Inc. pp. 426–435. p426. Retrieved 2010-09-07.
- ↑ 2.0 2.1 P. Ciaccia, M. Patella, F. Rabitti, P. Zezula. "Indexing Metric Spaces with M-tree" (PDF). Department of Computer Science and Engineering. University of Bologna. p. 3. Retrieved 19 November 2013.
| ||||||||||||||||||||||