Log-linear analysis
Log-linear analysis is a technique used in statistics to examine the relationship between more than two categorical variables. The technique is used for both hypothesis testing and model building. In both these uses, models are tested to find the most parsimonious (i.e., least complex) model that best accounts for the variance in the observed frequencies. (A Pearson's chi-square test could be used instead of log-linear analysis, but that technique only allows for two of the variables to be compared at a time.[1])
Fitting criterion
Log-linear analysis uses a likelihood ratio statistic 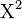 :[2] that has an approximate chi-square distribution when the sample size is large:
:[2] that has an approximate chi-square distribution when the sample size is large:

where
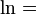 natural logarithm;
natural logarithm;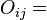 observed frequency in cellij (i = row and j = column);
observed frequency in cellij (i = row and j = column);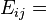 expected frequency in cellij.
expected frequency in cellij.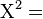 the deviance for the model.[3]
the deviance for the model.[3]
Assumptions
There are two assumptions in log-linear analysis:[2]
1. The observations are independent and random;
2. Observed frequencies are normally distributed about expected frequencies over repeated samples. For this assumption to hold, the expected frequencies need to be greater than or equal to 5 for 80% or more of the categories and all expected frequencies need to be greater than 1. Violations to this assumption result in a large reduction in power. Suggested solutions to this violation are: delete a variable, combine levels of one variable (e.g., put males and females together), or collect more data.
Additionally, data should always be categorical. Although, this is not a requirement, continuous data can be used; but by converting continuous data into categorical data information is lost. With both continuous and categorical data, it would be best to use logistic regression. (Any data that is analysed with log-linear analysis can also be analysed with logistic regression. The technique chosen depends on the research questions.)
Variables
In log-linear analysis there is no clear distinction between what variables are the independent or dependent variables. The variables are treated the same. However, often the theoretical background of the variables will lead the variables to be interpreted as either the independent or dependent variables.[1]
Models
The goal of log-linear analysis is to determine which model components are necessary to retain in order to best account for the data. Model components are the number of main effects and interactions in the model. For example, if examined the relationship between three variables—variable A, variable B, and variable C—there are seven model components in the saturated model. The three main effects (A, B, C), the three two-way interactions (AB, AC, BC), and the one three-way interaction (ABC) gives the seven model components.
The log-linear models can be thought of to be on a continuum with the two extremes being the simplest model and the saturated model. The simplest model is the model where all the expected frequencies are equal. This is true when the variables are not related. The saturated model is the model that includes all the model components. This model will always explain the data the best, but it is the least parsimonious as everything is included. In this model observed frequencies equal expected frequencies, therefore in the likelihood ratio chi-square statistic, the ratio 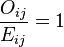 and
and  . This results in the likelihood ratio chi-square statistic being equal to 0, which is the best model fit.[2] Other possible models are the conditional equiprobability model and the mutual dependence model.[1]
. This results in the likelihood ratio chi-square statistic being equal to 0, which is the best model fit.[2] Other possible models are the conditional equiprobability model and the mutual dependence model.[1]
Each log-linear model can be represented as a log-linear equation. For example, with the three variables (A, B, C) the saturated model has the following log-linear equation:[1]
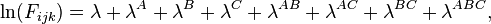
where
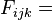 expected frequency in cellijk;
expected frequency in cellijk;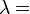 the relative weight of each variable.
the relative weight of each variable.
Hierarchical model
Log-linear analysis models can be hierarchical or nonhierarchical. Hierarchical models are the most common. These models contain all the lower order interactions and main effects of the interaction to be examined.[1]
Graphical model
A log-linear model is graphical if, whenever the model contains all two-factor terms generated by a higher-order interaction, the model also contains the higher-order interaction.[4] As a direct-consequence, graphical models are hierarchical. Moreover, being completely determined by its two-factor terms, a graphical model can be represented by an undirected graph, where the vertices represent the variables and the edges represent the two-factor terms included in the model.
Decomposable model
A log-linear model is decomposable if it is graphical and if the corresponding graph is chordal.
Model fit
The model fits well when the residuals (i.e., observed-expected) are close to 0, that is the closer the observed frequencies are to the expected frequencies the better the model fit. If the likelihood ratio chi-square statistic is non-significant, then the model fits well (i.e., calculated expected frequencies are close to observed frequencies). If the likelihood ratio chi-square statistic is significant, then the model does not fit well (i.e., calculated expected frequencies are not close to observed frequencies).
Backward elimination is used to determine which of the model components are necessary to retain in order to best account for the data. Log-linear analysis starts with the saturated model and the highest order interactions are removed until the model no longer accurately fits the data. Specifically, at each stage, after the removal of the highest ordered interaction, the likelihood ratio chi-square statistic is computed to measure how well the model is fitting the data. The highest ordered interactions are no longer removed when the likelihood ratio chi-square statistic becomes significant.[2]
Comparing models
When two models are nested, models can also be compared using a chi-square difference test. The chi-square difference test is computed by subtracting the likelihood ratio chi-square statistics for the two models being compared. This value is then compared to the chi-square critical value at their difference in degrees of freedom. If the chi-square difference is smaller than the chi-square critical value, the new model fits the data significantly better and is the preferred model. Else, if the chi-square difference is larger than the critical value, the less parsimonious model is preferred.[1]
Follow-up tests
Once the model of best fit is determined, the highest-order interaction is examined by conducting chi-square analyses at different levels of one of the variables. To conduct chi-square analyses, one needs to break the model down into a 2 × 2 or 2 × 1 contingency table.[2]
For example, if one is examining the relationship among four variables, and the model of best fit contained one of the three-way interactions, one would examine its simple two-way interactions at different levels of the third variable.
Effect sizes
To compare effect sizes of the interactions between the variables, odds ratios are used. Odds ratios are preferred over chi-square statistics for two main reasons:[1]
1. Odds ratios are independent of the sample size;
2. Odds ratios are not affected by unequal marginal distributions.
Software
For datasets with a few variables – general log-linear models
- R with the loglm function of the MASS package (see tutorial)
- IBM SPSS Statistics with the GENLOG procedure (usage)
For datasets with hundreds of variables – decomposable models
See also
References
- ↑ 1.0 1.1 1.2 1.3 1.4 1.5 1.6 Howell, D. C. (2009). Statistical methods for psychology (7th ed.). Belmot, CA: Cengage Learning. pp. 630–655.
- ↑ 2.0 2.1 2.2 2.3 2.4 Field, A. (2005). Discovering statistics using SPSS (2nd ed.). Thousand Oaks, CA: Sage Publications. pp. 695–718.
- ↑ Agresti, Alan (2007). An Introduction to Categorical Data Analysis (2nd ed.). Hoboken, NJ: Wiley Inter-Science. p. 212. ISBN 978-0-471-22618-5.
- ↑ Christensen, R. (1997). Log-Linear Models and Logistic Regression (2nd ed.). Springer.
- ↑ Petitjean, F.; Webb, G.I.; Nicholson, A.E. (2013). Scaling log-linear analysis to high-dimensional data. International Conference on Data Mining. Dallas, TX, USA: IEEE. pp. 597–606.
Further reading
- Log-linear Models
- Simkiss, D.; Ebrahim, G. J.; Waterston, A. J. R. (Eds.) "Chapter 14: Analysing categorical data: Log-linear analysis". Journal of Tropical Pediatrics, online only area, “Research methods II: Multivariate analysis” (pp. 144–153). Retrieved May 2012 from http://www.oxfordjournals.org/tropej/online/ma_chap14.pdf
- Pugh, M. D. (1983). "Contributory fault and rape convictions: Log-linear models for blaming the victim". Social Psychology Quarterly, 46, 233–242. JSTOR 3033794
- Tabachnick, B. G., & Fidell, L. S. (2007). Using Multivariate Statistics (5th ed.). New York, NY: Allyn and Bacon.