Linear separability
In Euclidean geometry linear separability is a geometric property of a pair of sets of points. This is most easily visualized in two dimensions (the Euclidean plane) by thinking of one set of points as being colored blue and the other set of points as being colored red. These two sets are linearly separable if there exists at least one line in the plane with all of the blue points on one side of the line and all the red points on the other side. This idea immediately generalizes to higher-dimensional Euclidean spaces if line is replaced by hyperplane.
The problem of determining if a pair of sets is linearly separable and finding a separating hyperplane if they are arises in several areas. In statistics and machine learning, classifying certain types of data is a problem for which good algorithms exist that are based on this concept.
Mathematical definition
Let 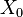 and
and 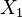 be two sets of points in an n-dimensional Euclidean space. Then and are linearly separable if there exists n + 1 real numbers
be two sets of points in an n-dimensional Euclidean space. Then and are linearly separable if there exists n + 1 real numbers 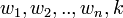 , such that every point
, such that every point 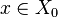 satisfies
satisfies 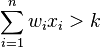 and every point
and every point 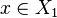 satisfies
satisfies 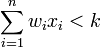 , where
, where 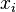 is the
is the 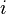 -th component of
-th component of 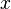 .
.
Equivalently, two sets are linearly separable precisely when their respective convex hulls are disjoint (colloquially, do not overlap).
Examples
Three non-collinear points in two classes ('+' and '-') are always linearly separable in two dimensions. This is illustrated by the three examples in the following figure (the all '+' case is not shown, but is similar to the all '-' case):
 |
 |
 |
However, not all sets of four points, no three collinear, are linearly separable in two dimensions. The following example would need two straight lines and thus is not linearly separable:
 |
Notice that three points which are collinear and of the form "+ ⋅⋅⋅ — ⋅⋅⋅ +" are also not linearly separable.
Linear separability of Boolean functions in n variables
A Boolean function in n variables can be thought of as an assignment of 0 or 1 to each vertex of a Boolean hypercube in n dimensions. This gives a natural division of the vertices into two sets. The Boolean function is said to be linearly separable provided these two sets of points are linearly separable.
| Number of variables | Linearly separable Boolean functions |
|---|---|
| 2 | 14 |
| 3 | 104 |
| 4 | 1882 |
| 5 | 94572 |
| 6 | 15028134 |
| 7 | 8378070864 |
| 8 | 17561539552946 |
| 9 | 144130531453121108 |
Support vector machines
.svg.png)
Classifying data is a common task in machine learning. Suppose some data points, each belonging to one of two sets, are given and we wish to create a model that will decide which set a new data point will be in. In the case of support vector machines, a data point is viewed as a p-dimensional vector (a list of p numbers), and we want to know whether we can separate such points with a (p − 1)-dimensional hyperplane. This is called a linear classifier. There are many hyperplanes that might classify (separate) the data. One reasonable choice as the best hyperplane is the one that represents the largest separation, or margin, between the two sets. So we choose the hyperplane so that the distance from it to the nearest data point on each side is maximized. If such a hyperplane exists, it is known as the maximum-margin hyperplane and the linear classifier it defines is known as a maximum margin classifier.
More formally, given some training data 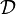 , a set of n points of the form
, a set of n points of the form
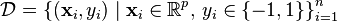
where the yi is either 1 or −1, indicating the set to which the point 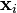 belongs. Each is a p-dimensional real vector. We want to find the maximum-margin hyperplane that divides the points having
belongs. Each is a p-dimensional real vector. We want to find the maximum-margin hyperplane that divides the points having 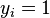 from those having
from those having 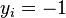 . Any hyperplane can be written as the set of points
. Any hyperplane can be written as the set of points 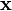 satisfying
satisfying
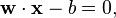
where  denotes the dot product and
denotes the dot product and  the (not necessarily normalized) normal vector to the hyperplane. The parameter
the (not necessarily normalized) normal vector to the hyperplane. The parameter  determines the offset of the hyperplane from the origin along the normal vector .
determines the offset of the hyperplane from the origin along the normal vector .
If the training data are linearly separable, we can select two hyperplanes in such a way that they separate the data and there are no points between them, and then try to maximize their distance.
See also
- Perceptron
- Vapnik–Chervonenkis dimension
References
- ↑ Gruzling, Nicolle (2006). "Linear separability of the vertices of an n-dimensional hypercube. M.Sc Thesis". University of Northern British Columbia.