Linear prediction
Linear prediction is a mathematical operation where future values of a discrete-time signal are estimated as a linear function of previous samples.
In digital signal processing, linear prediction is often called linear predictive coding (LPC) and can thus be viewed as a subset of filter theory. In system analysis (a subfield of mathematics), linear prediction can be viewed as a part of mathematical modelling or optimization.
The prediction model
The most common representation is
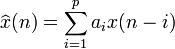
where 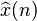 is the predicted signal value,
is the predicted signal value, 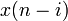 the previous observed values, and
the previous observed values, and 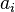 the predictor coefficients. The error generated by this estimate is
the predictor coefficients. The error generated by this estimate is
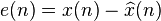
where  is the true signal value.
is the true signal value.
These equations are valid for all types of (one-dimensional) linear prediction. The differences are found in the way the parameters are chosen.
For multi-dimensional signals the error metric is often defined as
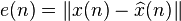
where  is a suitable chosen vector norm. Predictions such as are routinely used within Kalman filters and smoothers [1] to estimate current and past signal values, respectively.
is a suitable chosen vector norm. Predictions such as are routinely used within Kalman filters and smoothers [1] to estimate current and past signal values, respectively.
Estimating the parameters
The most common choice in optimization of parameters is the root mean square criterion which is also called the autocorrelation criterion. In this method we minimize the expected value of the squared error E[e2(n)], which yields the equation
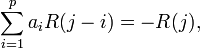
for 1 ≤ j ≤ p, where R is the autocorrelation of signal xn, defined as
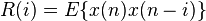 ,
,
and E is the expected value. In the multi-dimensional case this corresponds to minimizing the L2 norm.
The above equations are called the normal equations or Yule-Walker equations. In matrix form the equations can be equivalently written as
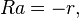
where the autocorrelation matrix R is a symmetric, p×p Toeplitz matrix with elements ri,j = R(i − j), 0≤i,j<p, the vector r is the autocorrelation vector rj = R(j), 0<j≤p, and the vector a is the parameter vector.
Another, more general, approach is to minimize the sum of squares of the errors defined in the form
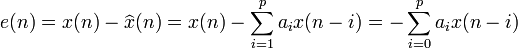
where the optimisation problem searching over all must now be constrained with 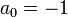 .
.
On the other hand, if the mean square prediction error is constrained to be unity and the prediction error equation is included on top of the normal equations, the augmented set of equations is obtained as
![\ Ra = [1, 0, ... , 0]^{\mathrm{T}}](../I/m/8cc8ebbe7eee188032176043a514b23c.png)
where the index i ranges from 0 to p, and R is a (p + 1) × (p + 1) matrix.
Specification of the parameters of the linear predictor is a wide topic and a large number of other approaches have been proposed. In fact, the autocorrelation method is the most common and it is used, for example, for speech coding in the GSM standard.
Solution of the matrix equation Ra = r is computationally a relatively expensive process. The Gauss algorithm for matrix inversion is probably the oldest solution but this approach does not efficiently use the symmetry of R and r. A faster algorithm is the Levinson recursion proposed by Norman Levinson in 1947, which recursively calculates the solution. In particular, the autocorrelation equations above may be more efficiently solved by the Durbin algorithm.[2]
Later, Delsarte et al. proposed an improvement to this algorithm called the split Levinson recursion which requires about half the number of multiplications and divisions. It uses a special symmetrical property of parameter vectors on subsequent recursion levels. That is, calculations for the optimal predictor containing p terms make use of similar calculations for the optimal predictor containing p − 1 terms.
Another way of identifying model parameters is to iteratively calculate state estimates using Kalman filters and obtaining maximum likelihood estimates within Expectation–maximization algorithms.
See also
References
- ↑ Einicke, G.A. (2012). Smoothing, Filtering and Prediction: Estimating the Past, Present and Future. Rijeka, Croatia: Intech. ISBN 978-953-307-752-9.
- ↑ M. A. Ramirez (2008) "A Levinson Algorithm Based on an Isometric Transformation of Durbin's," IEEE Signal Processing Lett., vol. 15, pp. 99-102.
Further reading
- Hayes, M. H. (1996). Statistical Digital Signal Processing and Modeling. New York: J. Wiley & Sons.
- Levinson, N. (1947). "The Wiener RMS (root mean square) error criterion in filter design and prediction". Journal of Mathematics and Physics 25 (4): 261–278.
- Makhoul, J. (1975). "Linear prediction: A tutorial review". Proceedings of the IEEE 63 (5): 561–580. doi:10.1109/PROC.1975.9792.
- Yule, G. U. (1927). "On a Method of Investigating Periodicities in Disturbed Series, with Special Reference to Wolfer's Sunspot Numbers". Phil. Trans. Roy. Soc. A 226: 267–298. JSTOR 91170.