Lift (data mining)
In data mining and association rule learning, lift is a measure of the performance of a targeting model (association rule) at predicting or classifying cases as having an enhanced response (with respect to the population as a whole), measured against a random choice targeting model. A targeting model is doing a good job if the response within the target is much better than the average for the population as a whole. Lift is simply the ratio of these values: target response divided by average response.
For example, suppose a population has an average response rate of 5%, but a certain model (or rule) has identified a segment with a response rate of 20%. Then that segment would have a lift of 4.0 (20%/5%).
Typically, the modeller seeks to divide the population into quantiles, and rank the quantiles by lift. Organizations can then consider each quantile, and by weighing the predicted response rate (and associated financial benefit) against the cost, they can decide whether to market to that quantile or not.
Lift is analogous to information retrieval's average precision metric, if one treats the precision (fraction of the positives that are true positives) as the target response probability.
The lift curve can also be considered a variation on the receiver operating characteristic (ROC) curve, and is also known in econometrics as the Lorenz or power curve.[1]
The difference between the lifts observed on two different subgroups is called the uplift. The subtraction of two lift curves forms the uplift curve, which is a metric used in uplift modelling.[2] [3]
It is important to note that in general marketing practice the term Lift is also defined as the difference in response rate between the treatment and control groups, indicating the causal impact of a marketing program (versus not having it as in the control group). As a result, "no lift" often means there is no statistically significant effect of the program. On top of this, uplift modelling is a predictive modeling technique to improve (up) lift over control.
Example
Assume the data set being mined is:
| Antecedent | Consequent |
|---|---|
| A | 0 |
| A | 0 |
| A | 1 |
| A | 0 |
| B | 1 |
| B | 0 |
| B | 1 |
where the antecedent is the input variable that we can control, and the consequent is the variable we are trying to predict. Real mining problems would typically have more complex antecedents, but usually focus on single-value consequents.
Most mining algorithms would determine the following rules (targeting models):
- Rule 1: A implies 0
- Rule 2: B implies 1
because these are simply the most common patterns found in the data. A simple review of the above table should make these rules obvious.
The support for Rule 1 is 3/7 because that is the number of items in the dataset in which the antecedent is A and the consequent 0. The support for Rule 2 is 2/7 because two of the seven records meet the antecedent of B and the consequent of 1. The supports can be written as:
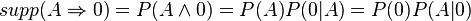
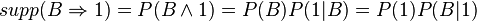
The confidence for Rule 1 is 3/4 because three of the four records that meet the antecedent of A meet the consequent of 0. The confidence for Rule 2 is 2/3 because two of the three records that meet the antecedent of B meet the consequent of 1. The confidences can be written as:
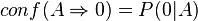
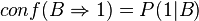
Lift can be found by dividing the confidence by the unconditional probability of the consequent, or by dividing the support by the probability of the antecedent times the probability of the consequent, so:
- The lift for Rule 1 is (3/4)/(4/7) ≈ 1.31
- The lift for Rule 2 is (2/3)/(3/7) = 2/3 * 7/3 = 14/9 ≈ 1.56
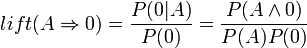
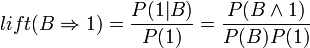
If some rule had a lift of 1, it would imply that the probability of occurrence of the antecedent and that of the consequent are independent of each other. When two events are independent of each other, no rule can be drawn involving those two events.
If the lift is > 1, like it is here for Rules 1 and 2, that lets us know the degree to which those two occurrences are dependent on one another, and makes those rules potentially useful for predicting the consequent in future data sets.
Observe that even though Rule 1 has higher confidence, it has lower lift. Intuitively, it would seem that Rule 1 is more valuable because of its higher confidence—it seems more accurate (better supported). But accuracy of the rule independent of the data set can be misleading. The value of lift is that it considers both the confidence of the rule and the overall data set.
References
- ↑ Tufféry, Stéphane (2011); Data Mining and Statistics for Decision Making, Chichester, GB: John Wiley & Sons, translated from the French Data Mining et statistique décisionnelle (Éditions Technip, 2008)
- ↑ Kuusisto, Finn; Santos Costa, Vitor; Nassif, Houssam; Burnside, Elizabeth; Page, David; Shavlik, Jude (2014). "Support Vector Machines for Differential Prediction". European Conference on Machine Learning (ECML'14) (Nancy, France).
- ↑ Nassif, Houssam; Kuusisto, Finn; Burnside, Elizabeth; Shavlik, Jude (2013). "Uplift Modeling with ROC: An SRL Case Study". International Conference on Inductive Logic Programming (Rio de Janeiro, Brazil).
- Coppock, David S. (2002-06-21). "Data Modeling and Management: Why Lift?". Retrieved 2007-02-19.