Leverage (statistics)
In statistics, leverage is a term used in connection with regression analysis and, in particular, in analyses aimed at identifying those observations that are far away from corresponding average predictor values. Leverage points do not necessarily have a large effect on the outcome of fitting regression models.
Leverage points are those observations, if any, made at extreme or outlying values of the independent variables such that the lack of neighboring observations means that the fitted regression model will pass close to that particular observation.[1]
Modern computer packages for statistical analysis include, as part of their facilities for regression analysis, various quantitative measures for identifying influential observations: among these measures is partial leverage, a measure of how a variable contributes to the leverage of a datum.
Linear regression model
Definition
In linear regression model, the leverage score for the 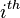 data unit is defined as:
data unit is defined as:
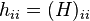
the diagonal of the hat matrix 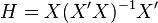 , where the apostrophe denotes the matrix transpose.
, where the apostrophe denotes the matrix transpose.
The leverage score is also known as the observation self-sensitivity or self-influence,[2] as:
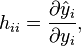
where 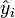 and
and 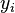 are the fitted and measured observation, respectively.
are the fitted and measured observation, respectively.
Property 1
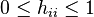
Proof
First, note that 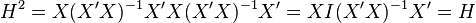 . Also, observe that
. Also, observe that 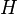 is symmetric.
So we have,
is symmetric.
So we have,
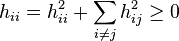
and
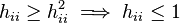
Property 2
If we are in an ordinary least squares setting with fixed X and:
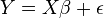
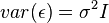
then 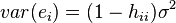 where
where 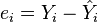 .
.
In other words, if the  are homoscedastic, leverage scores determine the noise level in the model.
are homoscedastic, leverage scores determine the noise level in the model.
Proof
First, note that 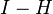 is idempotent and symmetric. This gives,
is idempotent and symmetric. This gives,
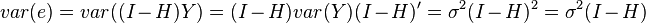 .
.
So that, .
See also
- Hat matrix — whose main diagonal entries are the leverages of the observations
- Mahalanobis distance — a measure of leverage of a datum
- Cook's distance - a measure of changes in regression coefficients when an observation is deleted
- DFFITS
- Outliers — observations with extreme Y values