L-estimator

In statistics, an L-estimator is an estimator which is an L-statistic – a linear combination of order statistics of the measurements. This can be as little as a single point, as in the median (of an odd number of values), or as many as all points, as in the mean.
The main benefits of L-estimators are that they are often extremely simple, and often robust statistics: assuming sorted data, they are very easy to calculate and interpret, and are often resistant to outliers. They thus are useful in robust statistics, as descriptive statistics, in statistics education, and when computation is difficult. However, they are inefficient, and in modern robust statistics M-estimators are preferred, though these are much more difficult computationally. In many circumstances L-estimators are reasonably efficient, and thus adequate for initial estimation.
Examples
A basic example is the median. Given n values 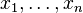 , if
, if 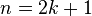 is odd, the median equals
is odd, the median equals 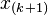 , the
, the 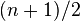 -th order statistic; if
-th order statistic; if 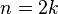 is even, it is the average of two order statistics:
is even, it is the average of two order statistics: 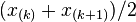 . These are both linear combinations of order statistics, and the median is therefore a simple example of an L-estimator.
. These are both linear combinations of order statistics, and the median is therefore a simple example of an L-estimator.
A more detailed list of examples includes: with a single point, the maximum, the minimum, or any single order statistic or quantile; with one or two points, the median; with two points, the mid-range, the range, the midsummary (trimmed mid-range, including the midhinge), and the trimmed range (including the interquartile range and interdecile range); with three points, the trimean; with a fixed fraction of the points, the trimmed mean (including interquartile mean) and the Winsorized mean; with all points, the mean.
Note that some of these (such as median, or mid-range) are measures of central tendency, and are used as estimators for a location parameter, such as the mean of a normal distribution, while others (such as range or trimmed range) are measures of statistical dispersion, and are used as estimators of a scale parameter, such as the standard deviation of a normal distribution.
L-estimators can also measure the shape of a distribution, beyond location and scale. For example, the midhinge minus the median is a 3-term L-estimator that measures the skewness, and other differences of midsummaries give measures of asymmetry at different points in the tail.[1]
Sample L-moments are L-estimators for the population L-moment, and have rather complex expressions. L-moments are generally treated separately; see that article for details.
Robustness
L-estimators are often statistically resistant, having a high breakdown point. This is defined as the fraction of the measurements which can be arbitrarily changed without causing the resulting estimate to tend to infinity (i.e., to "break down"). The breakdown point of an L-estimator is given by the closest order statistic to the minimum or maximum: for instance, the median has a breakdown point of 50% (the highest possible), and a n% trimmed or Winsorized mean has a breakdown point of n%.
Not all L-estimators are robust; if it includes the minimum or maximum, then it has a breakdown point of 0. These non-robust L-estimators include the minimum, maximum, mean, and mid-range. The trimmed equivalents are robust, however.
Robust L-estimators used to measure dispersion, such as the IQR, provide robust measures of scale.
Applications
In practical use in robust statistics, L-estimators have been replaced by M-estimators, which provide robust statistics that also have high relative efficiency, at the cost of being much more computationally complex and opaque.
However, the simplicity of L-estimators means that they are easily interpreted and visualized, and makes them suited for descriptive statistics and statistics education; many can even be computed mentally from a five-number summary or seven-number summary, or visualized from a box plot. L-estimators play a fundamental role in many approaches to non-parametric statistics.
Though non-parametric, L-estimators are frequently used for parameter estimation, as indicated by the name, though they must often be adjusted to yield an unbiased consistent estimator. The choice of L-estimator and adjustment depend on the distribution whose parameter is being estimated.
For example, when estimating a location parameter, for a symmetric distribution a symmetric L-estimator (such as the median or midhinge) will be unbiased. However, if the distribution has skew, symmetric L-estimators will generally be biased and require adjustment. For example, in a skewed distribution, the nonparametric skew (and Pearson's skewness coefficients) measure the bias of the median as an estimator of the mean.
When estimating a scale parameter, such as when using an L-estimator as a robust measures of scale, such as to estimate the population variance or population standard deviation, one generally must multiply by a scale factor to make it an unbiased consistent estimator; see scale parameter: estimation.
For example, dividing the IQR by 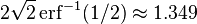 (using the error function) makes it an unbiased, consistent estimator for the population variance if the data follow a normal distribution.
(using the error function) makes it an unbiased, consistent estimator for the population variance if the data follow a normal distribution.
L-estimators can also be used as statistics in their own right – for example, the median is a measure of location, and the IQR is a measure of dispersion. In these cases, the sample statistics can act as estimators of their own expected value; for example, the sample median is an estimator of the population median.
Advantages
Beyond simplicity, L-estimators are also frequently easy to calculate and robust.
Assuming sorted data, L-estimators involving only a few points can be calculated with far fewer mathematical operations than efficient estimates.[2][3] Before the advent of electronic calculators and computers, these provided a useful way to extract much of the information from a sample with minimal labour. These remained in practical use through the early and mid 20th century, when automated sorting of punch card data was possible, but computation remained difficult,[2] and is still of use today, for estimates given a list of numerical values in non-machine-readable form, where data input is more costly than manual sorting. They also allow rapid estimation.
L-estimators are often much more robust than maximally efficient conventional methods – the median is maximally statistically resistant, having a 50% breakdown point, and the X% trimmed mid-range has an X% breakdown point, while the sample mean (which is maximally efficient) is minimally robust, breaking down for a single outlier.
Efficiency
While L-estimators are not as efficient as other statistics, they often have reasonably high relative efficiency, and show that a large fraction of the information used in estimation can be obtained using only a few points – as few as one, two, or three. Alternatively, they show that order statistics contain a significant amount of information.
For example, in terms of efficiency, given a sample of a normally-distributed numerical parameter, the arithmetic mean (average) for the population can be estimated with maximum efficiency by computing the sample mean – adding all the members of the sample and dividing by the number of members.
However, for a large data set (over 100 points) from a symmetric population, the mean can be estimated reasonably efficiently relative to the best estimate by L-estimators. Using a single point, this is done by taking the median of the sample, with no calculations required (other than sorting); this yields an efficiency of 64% or better (for all n). Using two points, a simple estimate is the midhinge (the 25% trimmed mid-range), but a more efficient estimate is the 29% trimmed mid-range, that is, averaging the two values 29% of the way in from the smallest and the largest values: the 29th and 71st percentiles; this has an efficiency of about 81%.[3] For three points, the trimean (average of median and midhinge) can be used, though the average of the 20th, 50th, and 80th percentile yields 88% efficiency. Using further points yield higher efficiency, though it is notable that only 3 points are needed for very high efficiency.
For estimating the standard deviation of a normal distribution, the scaled interdecile range gives a reasonably efficient estimator, though instead taking the 7% trimmed range (the difference between the 7th and 93rd percentiles) and dividing by 3 (corresponding to 86% of the data of a normal distribution falling within 1.5 standard deviations of the mean) yields an estimate of about 65% efficiency.[3]
For small samples, L-estimators are also relatively efficient: the midsummary of the 3rd point from each end has an efficiency around 84% for samples of size about 10, and the range divided by 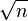 has reasonably good efficiency for sizes up to 20, though this drops with increasing n and the scale factor can be improved (efficiency 85% for 10 points). Other heuristic estimators for small samples include the range over n (for standard error), and the range squared over the median (for the chi-squared of a Poisson distribution).[3]
has reasonably good efficiency for sizes up to 20, though this drops with increasing n and the scale factor can be improved (efficiency 85% for 10 points). Other heuristic estimators for small samples include the range over n (for standard error), and the range squared over the median (for the chi-squared of a Poisson distribution).[3]
See also
References
- ↑ Velleman & Hoaglin 1981.
- ↑ 2.0 2.1 Mosteller 2006.
- ↑ 3.0 3.1 3.2 3.3 Evans 1955, Appendix G: Inefficient statistics, pp. 902–904.
- Evans, Robley Dunglison (1955). The Atomic Nucleus. International series in pure and applied physics. McGraw-Hill. p. 972. ISBN 0-89874414-8.
- Fraiman, R.; Meloche, J.; García-Escudero, L. A.; Gordaliza, A.; He, X.; Maronna, R.; Yohai, V. C. J.; Sheather, S. J.; McKean, J. W.; Small, C. G.; Wood, A.; Fraiman, R.; Meloche, J. (1999). "Multivariate L-estimation". Test 8 (2): 255–317. doi:10.1007/BF02595872.
- Huber, Peter J. (2004). Robust statistics. New York: Wiley-Interscience. ISBN 0-471-65072-2.
- Mosteller, Frederick (2006) [1946]. "On Some Useful "Inefficient" Statistics". In Fienberg, Stephen; Hoaglin, David. Selected Papers of Frederick Mosteller. Springer Series in Statistics. New York: Springer. pp. 69–100. doi:10.1007/978-0-387-44956-2_4. ISBN 978-0-387-20271-6.
- Shao, Jun (2003). Mathematical statistics. Berlin: Springer-Verlag. ISBN 0-387-95382-5. – sec. 5.2.2
- Velleman, P. F.; Hoaglin, D. C. (1981). Applications, Basics and Computing of Exploratory Data Analysis. ISBN 0-87150-409-X.