Kernel methods for vector output
Kernel methods are a well-established tool to analyze the relationship between input data and the corresponding output of a function. Kernels encapsulate the properties of functions in a computationally efficient way and allow algorithms to easily swap functions of varying complexity.
In typical machine learning algorithms, these functions produce a scalar output. Recent development of kernel methods for functions with vector-valued output is due, at least in part, to interest in simultaneously solving related problems. Kernels which capture the relationship between the problems allow them to borrow strength from each other. Algorithms of this type include multi-task learning (also called multi-output learning or vector-valued learning), transfer learning, and co-kriging. Multi-label classification can be interpreted as mapping inputs to (binary) coding vectors with length equal to the number of classes.
In Gaussian processes, kernels are called covariance functions. Multiple-output functions correspond to considering multiple processes. See Bayesian interpretation of regularization for the connection between the two perspectives.
History
The history of learning vector-valued functions is closely linked to transfer learning, a broad term that refers to systems that learn by transferring knowledge between different domains. The fundamental motivation for transfer learning in the field of machine learning was discussed in a NIPS-95 workshop on “Learning to Learn,” which focused on the need for lifelong machine learning methods that retain and reuse previously learned knowledge. Research on transfer learning has attracted much attention since 1995 in different names: learning to learn, lifelong learning, knowledge transfer, inductive transfer, multitask learning, knowledge consolidation, context-sensitive learning, knowledge-based inductive bias, metalearning, and incremental/cumulative learning.[1] Interest in learning vector-valued functions was particularly sparked by multitask learning, a framework which tries to learn multiple, possibly different tasks simultaneously.
Much of the initial research in multitask learning in the machine learning community was algorithmic in nature, and applied to methods such as neural networks, decision trees and k-nearest neighbors in the 1990s.[2] The use of probabilistic models and Gaussian processes was pioneered and largely developed in the context of geostatistics, where prediction over vector-valued output data is known as cokriging.[3][4][5] Geostatistical approaches to multivariate modeling are mostly formulated around the linear model of coregionalization (LMC), a generative approach for developing valid covariance functions that has been used for multivariate regression and in statistics for computer emulation of expensive multivariate computer codes. The regularization and kernel theory literature for vector-valued functions followed in the 2000s.[6][7] While the Bayesian and regularization perspectives were developed independently, they are in fact closely related.[8]
Notation
In this context, the supervised learning problem is to learn the function 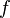 which best predicts vector-valued outputs
which best predicts vector-valued outputs 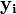 given inputs (data)
given inputs (data) 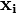 .
.
-
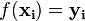 for
for 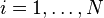
-
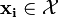 , an input space (e.g.
, an input space (e.g. 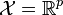 )
)
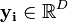
In general, each component of (), could have different input data (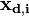 ) with different cardinality (
) with different cardinality (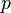 ) and even different input spaces (
) and even different input spaces (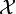 ).[8]
Geostatistics literature calls this case heterotopic, and uses isotopic to indicate that the each component of the output vector has the same set of inputs.[9]
).[8]
Geostatistics literature calls this case heterotopic, and uses isotopic to indicate that the each component of the output vector has the same set of inputs.[9]
Here, for simplicity in the notation, we assume the number and sample space of the data for each output are the same.
Regularization perspective[8][10][11]
From the regularization perspective, the problem is to learn 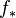 belonging to a reproducing kernel Hilbert space of vector-valued functions (
belonging to a reproducing kernel Hilbert space of vector-valued functions (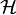 ). This is similar to the scalar case of Tikhonov regularization, with some extra care in the notation.
). This is similar to the scalar case of Tikhonov regularization, with some extra care in the notation.
| Vector-valued case | Scalar case | |
|---|---|---|
| Reproducing kernel | 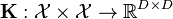 | 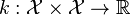 |
| Learning problem | 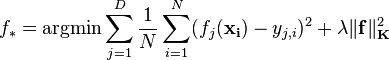 | 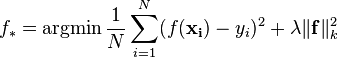 |
| Solution (derived via the representer theorem 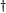 ) ) | 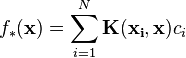 with |
Solve for where |
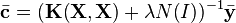 ,
,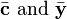 are the coefficients and output vectors concatenated to form
are the coefficients and output vectors concatenated to form 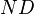 vectors and
vectors and 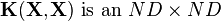 matrix of
matrix of 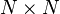 blocks:
blocks: 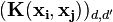
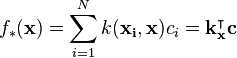
 by taking the derivative of the learning problem, setting it equal to zero, and substituting in the above expression for
by taking the derivative of the learning problem, setting it equal to zero, and substituting in the above expression for 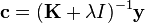
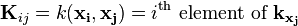
It is possible, though non-trivial, to show that a representer theorem also holds for Tikhonov regularization in the vector-valued setting.[8]
Note, the matrix-valued kernel 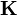 can also be defined by a scalar kernel
can also be defined by a scalar kernel 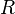 on the space
on the space 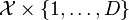 . An isometry exists between the Hilbert spaces associated with these two kernels:
. An isometry exists between the Hilbert spaces associated with these two kernels:
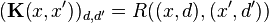
Gaussian process perspective
The estimator of the vector-valued regularization framework can also be derived from a Bayesian viewpoint using Gaussian process methods in the case of a finite dimensional Reproducing kernel Hilbert space. The derivation is similar to the scalar-valued case Bayesian interpretation of regularization. The vector-valued function 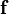 , consisting of
, consisting of 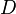 outputs
outputs 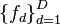 , is assumed to follow a Gaussian process:
, is assumed to follow a Gaussian process:
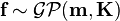
where 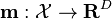 is now a vector of the mean functions
is now a vector of the mean functions 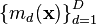 for the outputs and
for the outputs and 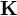 is a positive definite matrix-valued function with entry
is a positive definite matrix-valued function with entry 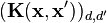 corresponding to the covariance between the outputs
corresponding to the covariance between the outputs 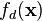 and
and 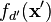 .
.
For a set of inputs 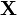 , the prior distribution over the vector
, the prior distribution over the vector 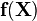 is given by
is given by 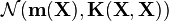 , where
, where 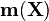 is a vector that concatenates the mean vectors associated to the outputs and
is a vector that concatenates the mean vectors associated to the outputs and 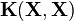 is a block-partitioned matrix. The distribution of the outputs is taken to be Gaussian:
is a block-partitioned matrix. The distribution of the outputs is taken to be Gaussian:
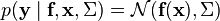
where 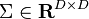 is a diagonal matrix with elements
is a diagonal matrix with elements 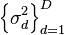 specifying the noise for each output. Using this form for the likelihood, the predictive distribution for a new vector
specifying the noise for each output. Using this form for the likelihood, the predictive distribution for a new vector 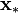 is:
is:
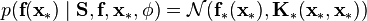
where 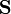 is the training data, and
is the training data, and 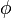 is a set of hyperparameters for
is a set of hyperparameters for 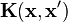 and
and 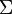 .
.
Equations for 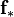 and
and 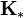 can then be obtained:
can then be obtained:
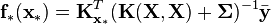
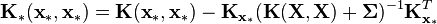
where 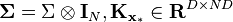 has entries
has entries 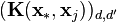 for
for 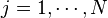 and
and 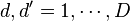 . Note that the predictor
. Note that the predictor 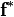 is identical to the predictor derived in the regularization framework. For non-Gaussian likelihoods different methods such as Laplace approximation and variational methods are needed to approximate the estimators.
is identical to the predictor derived in the regularization framework. For non-Gaussian likelihoods different methods such as Laplace approximation and variational methods are needed to approximate the estimators.
Example kernels
Separable
A simple, but broadly applicable, class of multi-output kernels can be separated into the product of a kernel on the input-space and a kernel representing the correlations among the outputs:[8]
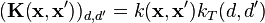
-
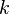 : scalar kernel on
: scalar kernel on 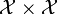
-
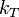 : scalar kernel on
: scalar kernel on 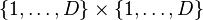
In matrix form: 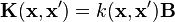 where
where 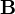 is a
is a 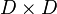 symmetric and positive semi-definite matrix. Note, setting to the identity matrix treats the outputs as unrelated and is equivalent to solving the scalar-output problems separately.
symmetric and positive semi-definite matrix. Note, setting to the identity matrix treats the outputs as unrelated and is equivalent to solving the scalar-output problems separately.
For a slightly more general form, adding several of these kernels yields sum of separable kernels (SoS kernels).
From regularization literature[8][10][12][13][14]
Derived from regularizer
One way of obtaining is to specify a regularizer which limits the complexity of in a desirable way, and then derive the corresponding kernel. For certain regularizers, this kernel will turn out to be separable.
Mixed-effect regularizer
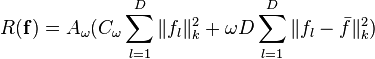
where:
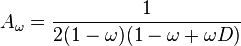
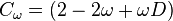
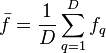
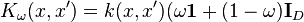
where 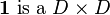 matrix with all entries equal to 1.
matrix with all entries equal to 1.
This regularizer is a combination of limiting the complexity of each component of the estimator ( ) and forcing each component of the estimator to be close to the mean of all the components. Setting
) and forcing each component of the estimator to be close to the mean of all the components. Setting 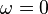 treats all the components as independent and is the same as solving the scalar problems separately. Setting
treats all the components as independent and is the same as solving the scalar problems separately. Setting 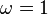 assumes all the components are explained by the same function.
assumes all the components are explained by the same function.
Cluster-based regularizer
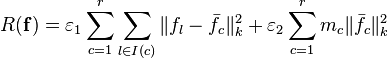
where:
-
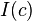 is the index set of components that belong to cluster
is the index set of components that belong to cluster 
-
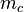 is the cardinality of cluster
is the cardinality of cluster -
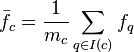
-
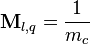 if
if 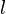 and
and 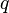 both belong to cluster (
both belong to cluster (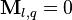 otherwise
otherwise -
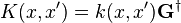
where 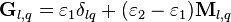
This regularizer divides the components into  clusters and forces the components in each cluster to be similar.
clusters and forces the components in each cluster to be similar.
Graph regularizer
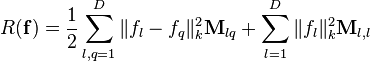
where 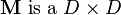 matrix of weights encoding the similarities between the components
matrix of weights encoding the similarities between the components
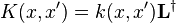
where 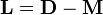 ,
, 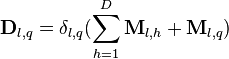
Note,  is the graph laplacian. See also: graph kernel.
is the graph laplacian. See also: graph kernel.
Learned from data
Several approaches to learning from data have been proposed.[8] These include: performing a preliminary inference step to estimate from the training data,[9] a proposal to learn and  together based on the cluster regularizer,[15] and sparsity-based approaches which assume only a few of the features are needed.[16]
[17]
together based on the cluster regularizer,[15] and sparsity-based approaches which assume only a few of the features are needed.[16]
[17]
From Bayesian literature
Linear model of coregionalization (LMC)
In LMC, outputs are expressed as linear combinations of independent random functions such that the resulting covariance function (over all inputs and outputs) is a valid positive semidefinite function. Assuming outputs 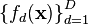 with
with 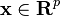 , each
, each  is expressed as:
is expressed as:
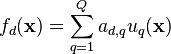
where 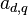 are scalar coefficients and the independent functions
are scalar coefficients and the independent functions 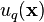 have zero mean and covariance cov
have zero mean and covariance cov![[u_q(\textbf{x}),u_{q'}(\textbf{x}')] = k_q(\textbf{x},\textbf{x}')](../I/m/bc145182e155ee283195b6d303621dd9.png) if
if 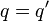 and 0 otherwise. The cross covariance between any two functions and
and 0 otherwise. The cross covariance between any two functions and 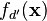 can then be written as:
can then be written as:
![\operatorname{cov}[f_d(\textbf{x}),f_{d'}(\textbf{x}')] = \sum_{q=1}^Q{\sum_{i=1}^{R_q}{a_{d,q}^ia_{d',q}^{i}k_q(\textbf{x},\textbf{x}')}} = \sum_{q=1}^Q{b_{d,d'}^qk_q(\textbf{x},\textbf{x}')}](../I/m/93cd739a51737ac68c48973b5a894e25.png)
where the functions 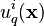 , with
, with 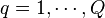 and
and 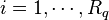 have zero mean and covariance cov
have zero mean and covariance cov![[u_q^i(\textbf{x}),u_{q'}^{i'}(\textbf{x})'] = k_q(\textbf{x},\textbf{x}')](../I/m/9cf1f56675ebb4e03d3ee9cecc2f25dd.png) if
if 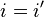 and . But
and . But ![\operatorname{cov}[f_d(\textbf{x}),f_{d'}(\textbf{x}')]](../I/m/1224d6eb6e6072ed531b5696a9049675.png) is given by . Thus the kernel can now be expressed as
is given by . Thus the kernel can now be expressed as
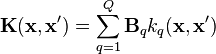
where each 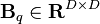 is known as a coregionalization matrix. Therefore, the kernel derived from LMC is a sum of the products of two covariance functions, one that models the dependence between the outputs, independently of the input vector
is known as a coregionalization matrix. Therefore, the kernel derived from LMC is a sum of the products of two covariance functions, one that models the dependence between the outputs, independently of the input vector 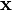 (the coregionalization matrix
(the coregionalization matrix 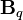 ), and one that models the input dependence, independently of (the covariance function
), and one that models the input dependence, independently of (the covariance function 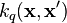 ).
).
Intrinsic coregionalization model (ICM)
The ICM is a simplified version of the LMC, with 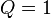 . ICM assumes that the elements
. ICM assumes that the elements 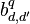 of the coregionalization matrix can be written as
of the coregionalization matrix can be written as 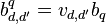 , for some suitable coefficients
, for some suitable coefficients 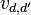 . With this form for :
. With this form for :
![\operatorname{cov}[f_d(\textbf{x}),f_{d'}(\textbf{x}')] = \sum_{q=1}^Q{v_{d,d'}b_qk_q(\textbf{x},\textbf{x}')} = v_{d,d'}\sum_{q=1}^Q{b_qk_q(\textbf{x},\textbf{x}')} = v_{d,d'}k(\textbf{x},\textbf{x}')](../I/m/224d64eb248f22550e71549bd7c220d5.png)
where 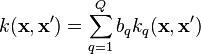 . In this case, the coefficients
. In this case, the coefficients 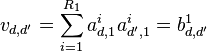 and the kernel matrix for multiple outputs becomes
and the kernel matrix for multiple outputs becomes 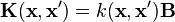 . ICM is much more restrictive than the LMC since it assumes that each basic covariance contributes equally to the construction of the autocovariances and cross covariances for the outputs. However, the computations required for the inference are greatly simplified.
. ICM is much more restrictive than the LMC since it assumes that each basic covariance contributes equally to the construction of the autocovariances and cross covariances for the outputs. However, the computations required for the inference are greatly simplified.
Semiparametric latent factor model (SLFM)
Another simplified version of the LMC is the semiparametric latent factor model (SLFM), which corresponds to setting 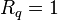 (instead of as in ICM). Thus each latent function
(instead of as in ICM). Thus each latent function 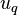 has its own covariance.
has its own covariance.
Non-separable
While simple, the structure of separable kernels can be too limiting for some problems.
Notable examples of non-separable kernels in the regularization literature include:
- Matrix-valued exponentiated quadratic (EQ) kernels designed to estimate divergence-free or curl-free vector fields (or a convex combination of the two)[8][18]
- Kernels defined by transformations[8][19]
In the Bayesian perspective, LMC produces a separable kernel because the output functions evaluated at a point only depend on the values of the latent functions at . A non-trivial way to mix the latent functions is by convolving a base process with a smoothing kernel. If the base process is a Gaussian process, the convolved process is Gaussian as well. We can therefore exploit convolutions to construct covariance functions.[20] This method of producing non-separable kernels is known as process convolution. Process convolutions were introduced for multiple outputs in the machine learning community as "dependent Gaussian processes".[21]
Implementation
When implementing an algorithm using any of the kernels above, practical considerations of tuning the parameters and ensuring reasonable computation time must be considered.
Regularization perspective
Approached from the regularization perspective, parameter tuning is similar to the scalar-valued case and can generally be accomplished with cross validation. Solving the required linear system is typically expensive in memory and time. If the kernel is separable, a coordinate transform can convert 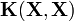 to a block-diagonal matrix, greatly reducing the computational burden by solving D independent subproblems (plus the eigendecomposition of ). In particular, for a least squares loss function (Tikhonov regularization), there exists a closed form solution for
to a block-diagonal matrix, greatly reducing the computational burden by solving D independent subproblems (plus the eigendecomposition of ). In particular, for a least squares loss function (Tikhonov regularization), there exists a closed form solution for 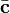 :[8][14]
:[8][14]
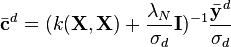
Bayesian perspective
There are many works related to parameter estimation for Gaussian processes. Some methods such as maximization of the marginal likelihood (also known as evidence approximation, type II maximum likelihood, empirical Bayes), and least squares give point estimates of the parameter vector . There are also works employing a full Bayesian inference by assigning priors to and computing the posterior distribution through a sampling procedure. For non-Gaussian likelihoods, there is no closed form solution for the posterior distribution or for the marginal likelihood. However, the marginal likelihood can be approximated under a Laplace, variational Bayes or expectation propagation (EP) approximation frameworks for multiple output classification and used to find estimates for the hyperparameters.
The main computational problem in the Bayesian viewpoint is the same as the one appearing in regularization theory of inverting the matrix 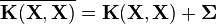 . This step is necessary for computing the marginal likelihood and the predictive distribution. For most proposed approximation methods to reduce computation, the computational efficiency gained is independent of the particular method employed (e.g. LMC, process convolution) used to compute the multi-output covariance matrix. A summary of different methods for reducing computational complexity in multi-output Gaussian processes is presented in.[8]
. This step is necessary for computing the marginal likelihood and the predictive distribution. For most proposed approximation methods to reduce computation, the computational efficiency gained is independent of the particular method employed (e.g. LMC, process convolution) used to compute the multi-output covariance matrix. A summary of different methods for reducing computational complexity in multi-output Gaussian processes is presented in.[8]
References
- ↑ S.J. Pan and Q. Yang, "A survey on transfer learning," IEEE Transactions on Knowledge and Data Engineering, 22, 2010
- ↑ Rich Caruana, "Multitask Learning," Machine Learning, 41–76, 1997
- ↑ J. Ver Hoef and R. Barry, "Constructing and fitting models for cokriging and multivariable spatial prediction," Journal of Statistical Planning and Inference, 69:275–294, 1998
- ↑ P. Goovaerts, "Geostatistics for Natural Resources Evaluation," Oxford University Press, USA, 1997
- ↑ N. Cressie "Statistics for Spatial Data," John Wiley & Sons Inc. (Revised Edition), USA, 1993
- ↑ C.A. Micchelli and M. Pontil, "On learning vector-valued functions," Neural Computation, 17:177–204, 2005
- ↑ C. Carmeli et al., "Vector valued reproducing kernel hilbert spaces of integrable functions and mercer theorem," Anal. Appl. (Singap.), 4
- ↑ 8.0 8.1 8.2 8.3 8.4 8.5 8.6 8.7 8.8 8.9 8.10 Mauricio A. Álvarez, Lorenzo Rosasco, and Neil D. Lawrence, "Kernels for Vector-Valued Functions: A Review," Foundations and Trends® in Machine Learning 4, no. 3 (2012): 195–266. doi: 10.1561/2200000036 arXiv:1106.6251
- ↑ 9.0 9.1 Hans Wackernagel. Multivariate Geostatistics. Springer-Verlag Heidelberg New york, 2003.
- ↑ 10.0 10.1 C.A. Micchelli and M. Pontil. On learning vector–valued functions. Neural Computation, 17:177–204, 2005.
- ↑ C.Carmeli, E.DeVito, and A.Toigo. Vector valued reproducing kernel Hilbert spaces of integrable functions and Mercer theorem. Anal. Appl. (Singap.), 4(4):377–408, 2006.
- ↑ C. A. Micchelli and M. Pontil. Kernels for multi-task learning. In Advances in Neural Information Processing Systems (NIPS). MIT Press, 2004.
- ↑ T.Evgeniou, C.A.Micchelli, and M.Pontil. Learning multiple tasks with kernel methods. Journal of Machine Learning Research, 6:615–637, 2005.
- ↑ 14.0 14.1 L. Baldassarre, L. Rosasco, A. Barla, and A. Verri. Multi-output learning via spectral filtering. Technical report, Massachusetts Institute of Technology, 2011. MIT-CSAIL-TR-2011-004, CBCL-296.
- ↑ Laurent Jacob, Francis Bach, and Jean-Philippe Vert. Clustered multi-task learning: A convex formulation. In NIPS 21, pages 745–752, 2008.
- ↑ Andreas Argyriou, Theodoros Evgeniou, and Massimiliano Pontil. Convex multi-task feature learning. Machine Learning, 73(3):243–272, 2008.
- ↑ Andreas Argyriou, Andreas Maurer, and Massimiliano Pontil. An algorithm for transfer learning in a heterogeneous environment. In ECML/PKDD (1), pages 71–85, 2008.
- ↑ I. Maceˆdo and R. Castro. Learning divergence-free and curl-free vector fields with matrix-valued kernels. Technical report, Instituto Nacional de Matematica Pura e Aplicada, 2008.
- ↑ A. Caponnetto, C.A. Micchelli, M. Pontil, and Y. Ying. Universal kernels for multi-task learning. Journal of Machine Learning Research, 9:1615–1646, 2008.
- ↑ D. Higdon, "Space and space-time modeling using process convolutions, Quantitative methods for current environmental issues, 37–56, 2002
- ↑ P. Boyle and M. Frean, "Dependent gaussian processes, Advances in Neural Information Processing Systems, 17:217–224, MIT Press, 2005