K-SVD
| Machine learning and data mining |
|---|
 |
| Problems |
| Clustering |
|
| Dimensionality reduction |
| Structured prediction |
| Anomaly detection |
|
| Neural nets |
| Theory |
|
|
In applied mathematics, K-SVD is a dictionary learning algorithm for creating a dictionary for sparse representations, via a singular value decomposition approach. K-SVD is a generalization of the k-means clustering method, and it works by iteratively alternating between sparse coding the input data based on the current dictionary, and updating the atoms in the dictionary to better fit the data.[1][2] K-SVD can be found widely in use in applications such as image processing, audio processing, biology, and document analysis.
Problem description
The goal of dictionary learning is to learn an overcomplete dictionary matrix 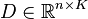 that contains
that contains 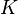 signal-atoms (in this notation, columns of
signal-atoms (in this notation, columns of 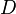 ). A signal vector
). A signal vector 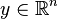 can be represented, sparsely, as a linear combination of these atoms; to represent
can be represented, sparsely, as a linear combination of these atoms; to represent 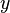 , the representation vector
, the representation vector 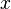 should satisfy the exact condition
should satisfy the exact condition 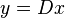 , or the approximate condition
, or the approximate condition 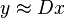 , made precise by requiring that
, made precise by requiring that 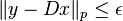 for some small value ε and some Lₚ norm. The vector
for some small value ε and some Lₚ norm. The vector 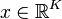 contains the representation coefficients of the signal . Typically, the norm
contains the representation coefficients of the signal . Typically, the norm 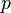 is selected as L1, L2, or L∞.
is selected as L1, L2, or L∞.
If 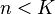 and D is a full-rank matrix, an infinite number of solutions are available for the representation problem, Hence, constraints should be set on the solution. Also, to ensure sparsity, the solution with the fewest number of nonzero coefficients is preferred. Thus, the sparsity representation is the solution of either
and D is a full-rank matrix, an infinite number of solutions are available for the representation problem, Hence, constraints should be set on the solution. Also, to ensure sparsity, the solution with the fewest number of nonzero coefficients is preferred. Thus, the sparsity representation is the solution of either
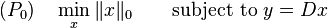
or
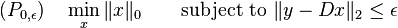
where the 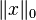 counts the nonzero entries in the vector . (See the zero "norm".)
counts the nonzero entries in the vector . (See the zero "norm".)
K-SVD algorithm
K-SVD is a kind of generalization of K-means, as follows.
The k-means clustering can be also regarded as a method of sparse representation. That is, finding the best possible codebook to represent the data samples 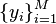 by nearest neighbor, by solving
by nearest neighbor, by solving
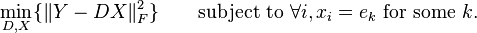
which is quite similar to
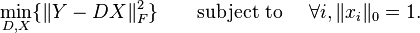
The sparse representation term 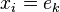 enforces K-means algorithm to use only one atom (column) in dictionary D. To relax this constraint, the target of the K-SVD algorithm is to represent signal as a linear combination of atoms in D.
enforces K-means algorithm to use only one atom (column) in dictionary D. To relax this constraint, the target of the K-SVD algorithm is to represent signal as a linear combination of atoms in D.
The K-SVD algorithm follows the construction flow of K-means algorithm. However, In contrary to K-means, in order to achieve linear combination of atoms in D, sparsity term of the constrain is relaxed so that nonzero entries of each column 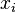 can be more than 1, but less than a number
can be more than 1, but less than a number 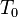 .
.
So, the objective function becomes
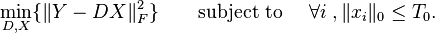
or in another objective form
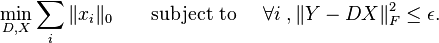
In the K-SVD algorithm, the is first to be fixed and the best coefficient matrix  . As finding the truly optimal is impossible, we use an approximation pursuit method. Any such algorithm as OMP, the orthogonal matching pursuit in can be used for the calculation of the coefficients, as long as it can supply a solution with a fixed and predetermined number of nonzero entries .
. As finding the truly optimal is impossible, we use an approximation pursuit method. Any such algorithm as OMP, the orthogonal matching pursuit in can be used for the calculation of the coefficients, as long as it can supply a solution with a fixed and predetermined number of nonzero entries .
After the sparse coding task, the next is to search for a better dictionary . However, finding the whole dictionary all at a time is impossible, so the process then update only one column of the dictionary each time while fix . The update of  is done by rewriting the penalty term as
is done by rewriting the penalty term as
where  denotes the k-th row of X.
denotes the k-th row of X.
By decomposing the multiplication  into sum of rank 1 matrices, we can assume the other
into sum of rank 1 matrices, we can assume the other 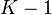 terms are assumed fixed, and the remains unknown. After this step, we can solve the minimization problem by approximate the
terms are assumed fixed, and the remains unknown. After this step, we can solve the minimization problem by approximate the 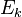 term with a
term with a 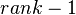 matrix using singular value decomposition, then update
matrix using singular value decomposition, then update 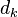 with it. However, the new solution of vector is very likely to be filled, because the sparsity constrain is not enforced.
with it. However, the new solution of vector is very likely to be filled, because the sparsity constrain is not enforced.
To cure this problem, Define 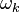 as
as
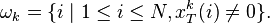
Which points to examples 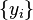 that use atom (also the entries of that is nonzero). Then, define
that use atom (also the entries of that is nonzero). Then, define 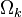 as a matrix of size
as a matrix of size 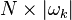 , with ones on the
, with ones on the 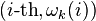 entries and zeros otherwise. When multiplying
entries and zeros otherwise. When multiplying 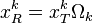 , this shrinks the row vector by discarding the nonzero entries. Similarly, the multiplication
, this shrinks the row vector by discarding the nonzero entries. Similarly, the multiplication 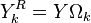 is the subset of the examples that are current using the atom. The same effect can be seen on
is the subset of the examples that are current using the atom. The same effect can be seen on 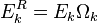 .
.
So the minimization problem as mentioned before becomes
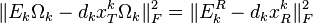
and can be done by directly using SVD. SVD decomposes 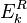 into
into 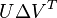 . The solution for is the first column of U, the coefficient vector
. The solution for is the first column of U, the coefficient vector 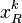 as the first column of
as the first column of 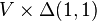 . After updated the whole dictionary, the process then turns to iteratively solve X, then iteratively solve D.
. After updated the whole dictionary, the process then turns to iteratively solve X, then iteratively solve D.
Limitations
Choosing an appropriate "dictionary" for a dataset is a non-convex problem, and K-SVD operates by an iterative update which does not guarantee to find the global optimum.[2] However, this is common to other algorithms for this purpose, and K-SVD works fairly well in practice.[2]
See also
References
- ↑ Michal Aharon, Michael Elad, and Alfred Bruckstein (2006), "K-SVD: An Algorithm for Designing Overcomplete Dictionaries for Sparse Representation", IEEE Transactions on Signal Processing 54 (11): 4311–4322, doi:10.1109/TSP.2006.881199
- ↑ 2.0 2.1 2.2 Rubinstein, R., Bruckstein, A.M., and Elad, M. (2010), "Dictionaries for Sparse Representation Modeling", Proceedings of the IEEE 98 (6): 1045–1057, doi:10.1109/JPROC.2010.2040551