Justesen code
| Binary Justesen Codes | |
|---|---|
| Named after | Jørn Justesen |
| Classification | |
| Type | Linear block code |
| Parameters | |
| Block length |
 |
| Message length |
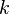 |
| Rate |
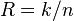 |
| Distance |
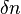 where where 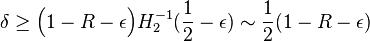 for small for small 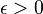 . . |
| Alphabet size | 2 |
| Notation |
![\left[ n, k, \delta n \right]_2](../I/m/e2dde02b7ebd6c013930ee7e19a6f169.png) -code -code |
| Properties | |
| constant rate, constant relative distance, constant alphabet size | |
In coding theory, Justesen codes form a class of error-correcting codes that have a constant rate, constant relative distance, and a constant alphabet size. Before the Justesen code was discovered, no code was known that had all of these three parameters as a constant. Subsequently, other codes with this property have been discovered, for example expander codes. These codes have important applications in computer science such as in the construction of small-bias sample spaces.
Justesen codes are derived as the code concatenation of a Reed–Solomon code and the Wozencraft ensemble. The Reed–Solomon codes used achieve constant rate and constant relative distance at the expense of an alphabet size that is linear in the message length. The Wozencraft ensemble is a family of codes that achieve constant rate and constant alphabet size, but the relative distance is only constant for most of the codes in the family. The concatenation of the two codes first encodes the message using the Reed–Solomon code, and then encodes each symbol of the codeword further using a code from the Wozencraft ensemble – using a different code of the ensemble at each position of the codeword. This is different from usual code concatenation where the inner codes are the same for each position. The Justesen code can be can constructed very efficiently using only logarithmic space.
Definition
Justesen code is concatenation code with different linear inner codes, which is composed of an 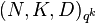 outer code
outer code  and different
and different 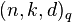 inner codes
inner codes 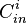 ,
, 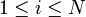 . More precisely, the concatenation of these codes, denoted by
. More precisely, the concatenation of these codes, denoted by 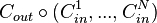 , is defined as follows. Given a message
, is defined as follows. Given a message ![m \in [q^k]^K](../I/m/e5bb4a18b0ea1b52a848f8176c26f8e7.png) , we compute the codeword produced by an outer code :
, we compute the codeword produced by an outer code : 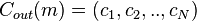 . Then we apply each code of N linear inner codes to each coordinate of that codeword to produce the final codeword; that is,
. Then we apply each code of N linear inner codes to each coordinate of that codeword to produce the final codeword; that is, 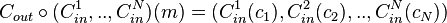 . Look back to the definition of the outer code and linear inner codes, this definition of the Justesen code makes sense because the codeword of the outer code is a vector with
. Look back to the definition of the outer code and linear inner codes, this definition of the Justesen code makes sense because the codeword of the outer code is a vector with 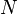 elements, and we have linear inner codes to apply for those elements.
elements, and we have linear inner codes to apply for those elements.
Here for the Justesen code, the outer code is chosen to be Reed Solomon code over a field 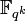 evaluated over
evaluated over 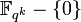 of rate
of rate 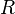 ,
, 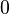 < <
< < 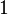 . The outer code have the relative distance
. The outer code have the relative distance 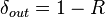 and block length of
and block length of 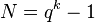 . The set of inner codes is the Wozencraft ensemble
. The set of inner codes is the Wozencraft ensemble 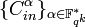 .
.
Property of Justesen code
As the linear codes in the Wonzencraft ensemble have the rate  , Justesen code is the concatenated code
, Justesen code is the concatenated code 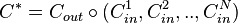 with the rate
with the rate 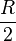 . We have the following theorem that estimates the distance of the concatenated code
. We have the following theorem that estimates the distance of the concatenated code 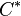 .
.
Theorem
Let  > 0. has relative distance at least
> 0. has relative distance at least 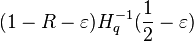 .
.
Proof:
The idea of proving that the code has the distance at least 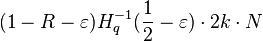 is to prove that the Hamming distance of two different codewords is at least .
is to prove that the Hamming distance of two different codewords is at least .
Denote 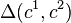 be the Hamming distance of two codewords
be the Hamming distance of two codewords 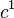 and
and 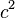 .
.
So for any given 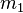 and
and 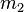 in
in 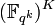 (
(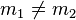 ), we want to lower bound
), we want to lower bound 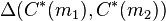 .
.
Notice that if , then 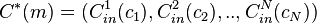 . So to the lower bound , we need to take into account the distance of for i = 1,2,…,N.
. So to the lower bound , we need to take into account the distance of for i = 1,2,…,N.
Suppose 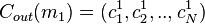 and
and 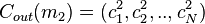 .
.
Recall that 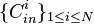 is a Wozencraft ensemble. Due to "Wonzencraft ensemble theorem", there are at least
is a Wozencraft ensemble. Due to "Wonzencraft ensemble theorem", there are at least 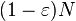 linear codes that have distance
linear codes that have distance 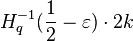 .
.
So if for some , 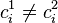 and code has distance
and code has distance 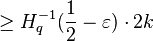 , then
, then 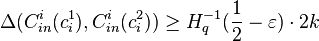 .
.
Further, if we have 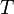 numbers such that and code has distance , then
numbers such that and code has distance , then 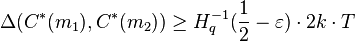 .
.
So now the final task is to lower bound .
Denote S be the set of all 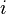 () such that . Then is the number of linear codes (
() such that . Then is the number of linear codes (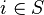 ) having the distance .
) having the distance .
Now we want to estimate 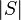 . Obviously
. Obviously 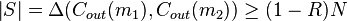 .
.
Due to the Wozencraft Ensemble Theorem, there are at most 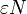 linear codes having distance less than , so
linear codes having distance less than , so 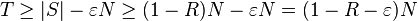 .
.
Finally,we have
.
This is true for any arbitrary . So has the relative distance at least , which completes the proof.
Comments
We want to consider the "strongly explicit code". So the question is what the "strongly explicit code" is. Loosely speaking, for linear code, the "explicit" property is related to the complexity of constructing its generator matrix G. That means, we can compute the matrix in logarithmic space without using the brute force algorithm to verify that a code has a given satisfied distance.
For the other codes that are not linear, we can consider the complexity of the encoding algorithm.
So by far, we can see that the Wonzencraft ensemble and Reed-Solomon codes are strongly explicit. Therefore we have the following result:
Corollary: The concatenated code is an asymptotically good code(that is, rate > 0 and relative distance 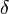 > 0 for small q) and has a strongly explicit construction.
> 0 for small q) and has a strongly explicit construction.
An example of a Justesen code
The following slightly different code is referred to as the Justesen code in MacWilliams/MacWilliams. It is the particular case of the above-considered Justesen code for a very particular Wonzencraft ensemble:
Let R be a Reed-Solomon code of length N = 2m − 1, rank K and minimum weight N − K + 1. The symbols of R are elements of F = GF(2m) and the codewords are obtained by taking every polynomial ƒ over F of degree less than K and listing the values of ƒ on the non-zero elements of F in some predetermined order. Let α be a primitive element of F. For a codeword a = (a1, ..., aN) from R, let b be the vector of length 2N over F given by
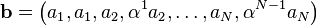
and let c be the vector of length 2N m obtained from b by expressing each element of F as a binary vector of length m. The Justesen code is the linear code containing all such c.
The parameters of this code are length 2m N, dimension m K and minimum distance at least

where 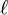 is the greatest integer satisfying
is the greatest integer satisfying 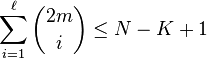 . (See MacWilliams/MacWilliams for a proof.)
. (See MacWilliams/MacWilliams for a proof.)
See also
References
- Lecture 28: Justesen Code. Coding theory's course. Prof. Atri Rudra.
- Lecture 6: Concatenated codes. Forney codes. Justesen codes. Essential Coding Theory.
- J. Justesen (1972). "A class of constructive asymptotically good algebraic codes". IEEE Trans. Info. Theory 18 (5): 652–656. doi:10.1109/TIT.1972.1054893.
- F.J. MacWilliams; N.J.A. Sloane (1977). The Theory of Error-Correcting Codes. North-Holland. pp. 306–316. ISBN 0-444-85193-3.