Inverse-Wishart distribution
| Notation |
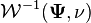 |
|---|---|
| Parameters |
 degrees of freedom (real) degrees of freedom (real) scale matrix (pos. def) scale matrix (pos. def) |
| Support |
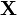 is positive definite is positive definite |
|
| |
| Mean |
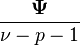 For For 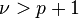 |
| Mode |
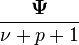 [1]:406 [1]:406 |
| Variance | see below |
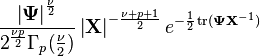
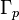 is the
is the 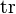 is the
is the In statistics, the inverse Wishart distribution, also called the inverted Wishart distribution, is a probability distribution defined on real-valued positive-definite matrices. In Bayesian statistics it is used as the conjugate prior for the covariance matrix of a multivariate normal distribution.
We say follows an inverse Wishart distribution, denoted as  , if its inverse
, if its inverse  has a Wishart distribution
has a Wishart distribution  . Important identities have been derived for Inverse-Wishart distribution.[2]
. Important identities have been derived for Inverse-Wishart distribution.[2]
Density
The probability density function of the inverse Wishart is:
where and  are
are 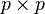 positive definite matrices, and Γp(·) is the multivariate gamma function.
positive definite matrices, and Γp(·) is the multivariate gamma function.
Theorems
Distribution of the inverse of a Wishart-distributed matrix
If 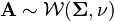 and
and  is of size , then
is of size , then  has an inverse Wishart distribution
has an inverse Wishart distribution 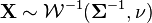 .[3]
.[3]
Marginal and conditional distributions from an inverse Wishart-distributed matrix
Suppose 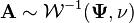 has an inverse Wishart distribution. Partition the matrices
has an inverse Wishart distribution. Partition the matrices 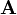 and conformably with each other
and conformably with each other

where 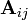 and
and  are
are 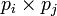 matrices, then we have
matrices, then we have
i) 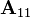 is independent of
is independent of 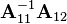 and
and  , where
, where 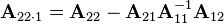 is the Schur complement of in ;
is the Schur complement of in ;
ii) 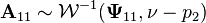 ;
;
iii)  , where
, where 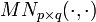 is a matrix normal distribution;
is a matrix normal distribution;
iv) 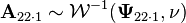 , where
, where 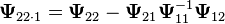 ;
;
Conjugate distribution
Suppose we wish to make inference about a covariance matrix 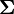 whose prior
whose prior 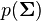 has a distribution. If the observations
has a distribution. If the observations ![\mathbf{X}=[\mathbf{x}_1,\ldots,\mathbf{x}_n]](../I/m/02e048405382559acde28a0bf402c610.png) are independent p-variate Gaussian variables drawn from a
are independent p-variate Gaussian variables drawn from a  distribution, then the conditional distribution
distribution, then the conditional distribution 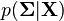 has a
has a  distribution, where
distribution, where  .
.
Because the prior and posterior distributions are the same family, we say the inverse Wishart distribution is conjugate to the multivariate Gaussian.
Due to its conjugacy to the multivariate Gaussian, it is possible to marginalize out (integrate out) the Gaussian's parameter 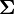 .
.
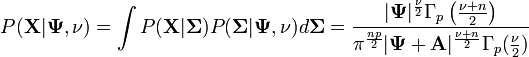
(this is useful because the variance matrix is not known in practice, but because is known a priori, and can be obtained from the data, the right hand side can be evaluated directly). The inverse-Wishart distribution as a prior can be constructed via existing transferred prior knowledge.[4]
Moments
The following is based on Press, S. J. (1982) "Applied Multivariate Analysis", 2nd ed. (Dover Publications, New York), after reparameterizing the degree of freedom to be consistent with the p.d.f. definition above.
The mean:[3]:85
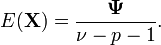
The variance of each element of :

The variance of the diagonal uses the same formula as above with 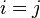 , which simplifies to:
, which simplifies to:
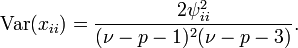
The covariance of elements of are given by:
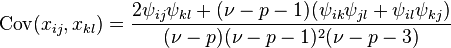
Related distributions
A univariate specialization of the inverse-Wishart distribution is the inverse-gamma distribution. With 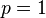 (i.e. univariate) and
(i.e. univariate) and 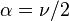 ,
, 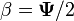 and
and  the probability density function of the inverse-Wishart distribution becomes
the probability density function of the inverse-Wishart distribution becomes
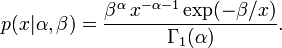
i.e., the inverse-gamma distribution, where 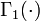 is the ordinary Gamma function.
is the ordinary Gamma function.
A generalization is the inverse multivariate gamma distribution.
Another generalization has been termed the generalized inverse Wishart distribution, 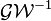 . A positive definite matrix is said to be distributed as
. A positive definite matrix is said to be distributed as 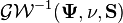 if
if 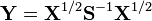 is distributed as
is distributed as  . Here
. Here 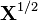 denotes the symmetric matrix square root of , the parameters
denotes the symmetric matrix square root of , the parameters 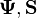 are positive definite matrices, and the parameter
are positive definite matrices, and the parameter 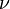 is a positive scalar larger than
is a positive scalar larger than 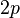 . Note that when
. Note that when 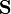 is equal to an identity matrix,
is equal to an identity matrix,  . This generalized inverse Wishart distribution has been applied to estimating the distributions of multivariate autoregressive processes.[5]
. This generalized inverse Wishart distribution has been applied to estimating the distributions of multivariate autoregressive processes.[5]
A different type of generalization is the normal-inverse-Wishart distribution, essentially the product of a multivariate normal distribution with an inverse Wishart distribution.
See also
- Inverse multivariate gamma distribution
- Matrix normal distribution
- Wishart distribution
References
- ↑ A. O'Hagan, and J. J. Forster (2004). Kendall's Advanced Theory of Statistics: Bayesian Inference 2B (2 ed.). Arnold. ISBN 0-340-80752-0.
- ↑ 2.0 2.1 Haff, LR (1979). "An identity for the Wishart distribution with applications". Journal of Multivariate Analysis 9 (4): 531–544.
- ↑ 3.0 3.1 Kanti V. Mardia, J. T. Kent and J. M. Bibby (1979). Multivariate Analysis. Academic Press. ISBN 0-12-471250-9.
- ↑ 4.0 4.1 Shahrokh Esfahani, Mohammad; Dougherty, Edward (2014). "Incorporation of Biological Pathway Knowledge in the Construction of Priors for Optimal Bayesian Classification". IEEE Transactions on Bioinformatics and Computational Biology 11 (1): 202–218.
- ↑ Triantafyllopoulos, K. (2011). "Real-time covariance estimation for the local level model". Journal of Time Series Analysis 32 (2): 93–107. doi:10.1111/j.1467-9892.2010.00686.x.