Inside–outside algorithm
In computer science, the inside–outside algorithm is a way of re-estimating production probabilities in a probabilistic context-free grammar. It was introduced James K. Baker in 1979 as a generalization of the forward–backward algorithm for parameter estimation on hidden Markov models to stochastic context-free grammars. It is used to compute expectations, for example as part of the expectation–maximization algorithm (an unsupervised learning algorithm).
Inside and outside probabilities
The inside probability 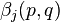 is the total probability of generating words
is the total probability of generating words 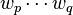 , given the root nonterminal
, given the root nonterminal 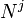 and a grammar
and a grammar 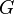 :[1]
:[1]
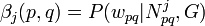
The outside probability 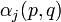 is the total probability of beginning with the start symbol
is the total probability of beginning with the start symbol 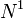 and generating the nonterminal
and generating the nonterminal 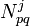 and all the words outside , given a grammar :[1]
and all the words outside , given a grammar :[1]
Computing Inside probabilities
Base Case:
General Case:
Suppose there is a rule  in the grammar, then the probability of generating starting with a subtree rooted at
in the grammar, then the probability of generating starting with a subtree rooted at  is:
is:
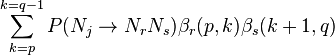
The inside probability is just the sum over all such possible rules:
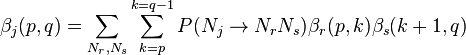
Computing Outside probabilities
Base Case:
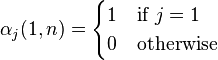
Here the start symbol is 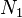 .
.
References
- J. Baker (1979): Trainable grammars for speech recognition. In J. J. Wolf and D. H. Klatt, editors, Speech communication papers presented at the 97th meeting of the Acoustical Society of America, pages 547–550, Cambridge, MA, June 1979. MIT.
- Karim Lari, Steve J. Young (1990): The estimation of stochastic context-free grammars using the inside–outside algorithm. Computer Speech and Language, 4:35–56.
- Karim Lari, Steve J. Young (1991): Applications of stochastic context-free grammars using the Inside–Outside algorithm. Computer Speech and Language, 5:237–257.
- Fernando Pereira, Yves Schabes (1992): Inside–outside reestimation from partially bracketed corpora. Proceedings of the 30th annual meeting on Association for Computational Linguistics, Association for Computational Linguistics, 128–135.