Information extraction
Information extraction (IE) is the task of automatically extracting structured information from unstructured and/or semi-structured machine-readable documents. In most of the cases this activity concerns processing human language texts by means of natural language processing (NLP). Recent activities in multimedia document processing like automatic annotation and content extraction out of images/audio/video could be seen as information extraction.
Due to the difficulty of the problem, current approaches to IE focus on narrowly restricted domains. An example is the extraction from news wire reports of corporate mergers, such as denoted by the formal relation:
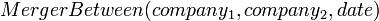 ,
,
from an online news sentence such as:
- "Yesterday, New York based Foo Inc. announced their acquisition of Bar Corp."
A broad goal of IE is to allow computation to be done on the previously unstructured data. A more specific goal is to allow logical reasoning to draw inferences based on the logical content of the input data. Structured data is semantically well-defined data from a chosen target domain, interpreted with respect to category and context.
History
Information extraction dates back to the late 1970s in the early days of NLP.[1] An early commercial system from the mid-1980s was JASPER built for Reuters by the Carnegie Group with the aim of providing real-time financial news to financial traders.[2]
Beginning in 1987, IE was spurred by a series of Message Understanding Conferences. MUC is a competition-based conference that focused on the following domains:
- MUC-1 (1987), MUC-2 (1989): Naval operations messages.
- MUC-3 (1991), MUC-4 (1992): Terrorism in Latin American countries.
- MUC-5 (1993): Joint ventures and microelectronics domain.
- MUC-6 (1995): News articles on management changes.
- MUC-7 (1998): Satellite launch reports.
Considerable support came from the U.S. Defense Advanced Research Projects Agency (DARPA), who wished to automate mundane tasks performed by government analysts, such as scanning newspapers for possible links to terrorism.
Present significance
The present significance of IE pertains to the growing amount of information available in unstructured form. Tim Berners-Lee, inventor of the world wide web, refers to the existing Internet as the web of documents [3] and advocates that more of the content be made available as a web of data.[4] Until this transpires, the web largely consists of unstructured documents lacking semantic metadata. Knowledge contained within these documents can be made more accessible for machine processing by means of transformation into relational form, or by marking-up with XML tags. An intelligent agent monitoring a news data feed requires IE to transform unstructured data into something that can be reasoned with. A typical application of IE is to scan a set of documents written in a natural language and populate a database with the information extracted.[5]
Tasks and subtasks
Applying information extraction on text, is linked to the problem of text simplification in order to create a structured view of the information present in free text. The overall goal being to create a more easily machine-readable text to process the sentences. Typical subtasks of IE include:
- Named entity extraction which could include:
- Named entity recognition: recognition of known entity names (for people and organizations), place names, temporal expressions, and certain types of numerical expressions, employing existing knowledge of the domain or information extracted from other sentences. Typically the recognition task involves assigning a unique identifier to the extracted entity. A simpler task is named entity detection, which aims to detect entities without having any existing knowledge about the entity instances. For example, in processing the sentence "M. Smith likes fishing", named entity detection would denote detecting that the phrase "M. Smith" does refer to a person, but without necessarily having (or using) any knowledge about a certain M. Smith who is (or, "might be") the specific person whom that sentence is talking about.
- Coreference resolution: detection of coreference and anaphoric links between text entities. In IE tasks, this is typically restricted to finding links between previously-extracted named entities. For example, "International Business Machines" and "IBM" refer to the same real-world entity. If we take the two sentences "M. Smith likes fishing. But he doesn't like biking", it would be beneficial to detect that "he" is referring to the previously detected person "M. Smith".
- Relationship extraction: identification of relations between entities, such as:
- PERSON works for ORGANIZATION (extracted from the sentence "Bill works for IBM.")
- PERSON located in LOCATION (extracted from the sentence "Bill is in France.")
- Semi-structured information extraction which may refer to any IE that tries to restore some kind information structure that has been lost through publication such as:
- Table extraction: finding and extracting tables from documents.
- Comments extraction : extracting comments from actual content of article in order to restore the link between author of each sentence
- Language and vocabulary analysis
- Terminology extraction: finding the relevant terms for a given corpus
- Audio extraction
- Template-based music extraction: finding relevant characteristic in an audio signal taken from a given repertoire; for instance [6] time indexes of occurrences of percussive sounds can be extracted in order to represent the essential rhythmic component of a music piece.
Note this list is not exhaustive and that the exact meaning of IE activities is not commonly accepted and that many approaches combine multiple sub-tasks of IE in order to achieve a wider goal. Machine learning, statistical analysis and/or natural language processing are often used in IE.
IE on non-text documents is becoming an increasing topic in research and information extracted from multimedia documents can now be expressed in a high level structure as it is done on text. This naturally lead to the fusion of extracted information from multiple kind of documents and sources.
World Wide Web applications
IE has been the focus of the MUC conferences. The proliferation of the Web, however, intensified the need for developing IE systems that help people to cope with the enormous amount of data that is available online. Systems that perform IE from online text should meet the requirements of low cost, flexibility in development and easy adaptation to new domains. MUC systems fail to meet those criteria. Moreover, linguistic analysis performed for unstructured text does not exploit the HTML/XML tags and layout format that are available in online text. As a result, less linguistically intensive approaches have been developed for IE on the Web using wrappers, which are sets of highly accurate rules that extract a particular page's content. Manually developing wrappers has proved to be a time-consuming task, requiring a high level of expertise. Machine learning techniques, either supervised or unsupervised, have been used to induce such rules automatically.
Wrappers typically handle highly structured collections of web pages, such as product catalogs and telephone directories. They fail, however, when the text type is less structured, which is also common on the Web. Recent effort on adaptive information extraction motivates the development of IE systems that can handle different types of text, from well-structured to almost free text -where common wrappers fail- including mixed types. Such systems can exploit shallow natural language knowledge and thus can be also applied to less structured text.
Approaches
Three standard approaches are now widely accepted
- Hand-written regular expressions (perhaps stacked)
- Using classifiers
- Generative: naïve Bayes classifier
- Discriminative: maximum entropy models
- Sequence models
- Hidden Markov model
- Conditional Markov model (CMM) / Maximum-entropy Markov model (MEMM)
- Conditional random fields (CRF) are commonly used in conjunction with IE for tasks as varied as extracting information from research papers[7] to extracting navigation instructions.[8]
Numerous other approaches exist for IE including hybrid approaches that combine some of the standard approaches previously listed.
Free or open source software and services
- General Architecture for Text Engineering "General Architecture for Text Engineering", which is bundled with a free Information Extraction system
- OpenNLP Apache OpenNLP is a Java machine learning toolkit for natural language processing
- OpenCalais Automated information extraction web service from Thomson Reuters (Free limited version)
- Machine Learning for Language Toolkit (Mallet) is a Java-based package for a variety of natural language processing tasks, including information extraction.
- DBpedia Spotlight is an open source tool in Java/Scala (and free web service) that can be used for named entity recognition and name resolution.
- See also CRF implementations
See also
- AI effect
- Applications of artificial intelligence
- Concept mining
- DARPA TIPSTER Program
- Enterprise search
- Faceted search
- Knowledge extraction
- Named entity recognition
- Nutch
- Semantic translation
- Textmining
- Web scraping
- Lists
References
- ↑ Andersen, Peggy M.; Hayes, Philip J.; Huettner, Alison K.; Schmandt, Linda M.; Nirenburg, Irene B.; Weinstein, Steven P. "Automatic Extraction of Facts from Press Releases to Generate News Stories". CiteSeerX: 10
.1 ..1 .14 .7943 - ↑ Cowie, Jim; Wilks, Yorick. "Information Extraction". CiteSeerX: 10
.1 ..1 .61 .6480 - ↑ "Linked Data - The Story So Far" (PDF).
- ↑ "Tim Berners-Lee on the next Web".
- ↑ R. K. Srihari, W. Li, C. Niu and T. Cornell,"InfoXtract: A Customizable Intermediate Level Information Extraction Engine",Journal of Natural Language Engineering, Cambridge U. Press , 14(1), 2008, pp.33-69.
- ↑ A.Zils, F.Pachet, O.Delerue and F. Gouyon, Automatic Extraction of Drum Tracks from Polyphonic Music Signals, Proceedings of WedelMusic, Darmstadt, Germany, 2002.
- ↑ Peng, F.; McCallum, A. (2006). "Information extraction from research papers using conditional random fields☆". Information Processing & Management 42 (4): 963. doi:10.1016/j.ipm.2005.09.002.
- ↑ Shimizu, Nobuyuki; Hass, Andrew (2006). "Extracting Frame-based Knowledge Representation from Route Instructions" (PDF).
External links
- MUC
- ACE (LDC)
- ACE (NIST)
- Alias-I "competition" page A listing of academic toolkits and industrial toolkits for natural language information extraction.
- Gabor Melli's page on IE Detailed description of the information extraction task.
- CRF++: Yet Another CRF toolkit
- A Survey of Web Information Extraction Systems A comprehensive survey.
Enterprise Search