Hierarchical Dirichlet process
In statistics and machine learning, the hierarchical Dirichlet process (HDP) is a nonparametric Bayesian approach to clustering grouped data.[1][2] It uses a Dirichlet process for each group of data, with the Dirichlet processes for all groups sharing a base distribution which is itself drawn from a Dirichlet process. This method allows groups to share statistical strength via sharing of clusters across groups. The base distribution being drawn from a Dirichlet process is important, because draws from a Dirichlet process are atomic probability measures, and the atoms will appear in all group-level Dirichlet processes. Since each atom corresponds to a cluster, clusters are shared across all groups. It was developed by Yee Whye Teh, Michael I. Jordan, Matthew J. Beal and David Blei and published in the Journal of the American Statistical Association in 2006.[1]
Model
This model description is sourced from.[1] The HDP is a model for grouped data. What this means is that the data items come in multiple distinct groups. For example, in a topic model words are organized into documents, with each document formed by a bag (group) of words (data items). Indexing groups by 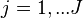 , suppose each group consist of data items
, suppose each group consist of data items 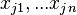 .
.
The HDP is parameterized by a base distribution 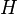 which governs the a priori distribution over data items, and a number of concentration parameters which govern the a priori number of clusters and amount of sharing across groups. The
which governs the a priori distribution over data items, and a number of concentration parameters which govern the a priori number of clusters and amount of sharing across groups. The 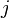 th group is associated with a random probability measure
th group is associated with a random probability measure 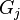 which has distribution given by a Dirichlet process:
which has distribution given by a Dirichlet process:
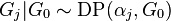
where 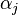 is the concentration parameter associated with the group, and
is the concentration parameter associated with the group, and 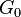 is the base distribution shared across all groups. In turn, the common base distribution is Dirichlet process distributed:
is the base distribution shared across all groups. In turn, the common base distribution is Dirichlet process distributed:
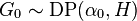
with concentration parameter 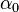 and base distribution . Finally, to relate the Dirichlet processes back with the observed data, each data item
and base distribution . Finally, to relate the Dirichlet processes back with the observed data, each data item 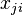 is associated with a latent parameter
is associated with a latent parameter 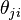 :
:
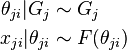
The first line states that each parameter has a prior distribution given by , while the second line states that each data item has a distribution 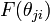 parameterized by its associated parameter. The resulting model above is called a HDP mixture model, with the HDP referring to the hierarchically linked set of Dirichlet processes, and the mixture model referring to the way the Dirichlet processes are related to the data items.
parameterized by its associated parameter. The resulting model above is called a HDP mixture model, with the HDP referring to the hierarchically linked set of Dirichlet processes, and the mixture model referring to the way the Dirichlet processes are related to the data items.
To understand how the HDP implements a clustering model, and how clusters become shared across groups, recall that draws from a Dirichlet process are atomic probability measures with probability one. This means that the common base distribution has a form which can be written as:
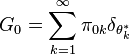
where there are an infinite number of atoms, 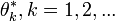 , assuming that the overall base distribution has infinite support. Each atom is associated with a mass
, assuming that the overall base distribution has infinite support. Each atom is associated with a mass 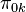 . The masses have to sum to one since is a probability measure. Since is itself the base distribution for the group specific Dirichlet processes, each will have atoms given by the atoms of , and can itself be written in the form:
. The masses have to sum to one since is a probability measure. Since is itself the base distribution for the group specific Dirichlet processes, each will have atoms given by the atoms of , and can itself be written in the form:
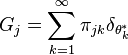
Thus the set of atoms is shared across all groups, with each group having its own group-specific atom masses. Relating this representation back to the observed data, we see that each data item is described by a mixture model:
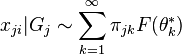
where the atoms 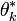 play the role of the mixture component parameters, while the masses
play the role of the mixture component parameters, while the masses 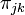 play the role of the mixing proportions. In conclusion, each group of data is modeled using a mixture model, with mixture components shared across all groups but mixing proportions being group-specific. In clustering terms, we can interpret each mixture component as modeling a cluster of data items, with clusters shared across all groups, and each group, having its own mixing proportions, composed of different combinations of clusters.
play the role of the mixing proportions. In conclusion, each group of data is modeled using a mixture model, with mixture components shared across all groups but mixing proportions being group-specific. In clustering terms, we can interpret each mixture component as modeling a cluster of data items, with clusters shared across all groups, and each group, having its own mixing proportions, composed of different combinations of clusters.
Applications
The HDP mixture model is a natural nonparametric generalization of Latent Dirichlet allocation, where the number of topics can be unbounded and learnt from data.[1] Here each group is a document consisting of a bag of words, each cluster is a topic, and each document is a mixture of topics. The HDP is also a core component of the infinite hidden Markov model,[1] which is a nonparametric generalization of the hidden Markov model allowing the number of states to be unbounded and learnt from data.
Generalizations
The HDP can be generalized in a number of directions. The Dirichlet processes can be replaced by Pitman-Yor processes, resulting in the Hierarchical Pitman-Yor process. The hierarchy can be deeper, with multiple levels of groups arranged in a hierarchy. Such an arrangement has been exploited in the sequence memoizer, a Bayesian nonparametric model for sequences which has a multi-level hierarchy of Pitman-Yor processes.
References
- ↑ 1.0 1.1 1.2 1.3 1.4 Teh, Y. W.; Jordan, M. I.; Beal, M. J.; Blei, D. M. (2006). "Hierarchical Dirichlet Processes". Journal of the American Statistical Association 101: pp. 1566–1581. doi:10.1198/016214506000000302.
- ↑ Teh, Y. W.; Jordan, M. I. (2010). "Hierarchical Bayesian Nonparametric Models with Applications". Bayesian Nonparametrics (Cambridge University Press).