Gradient descent
Gradient descent is a first-order optimization algorithm. To find a local minimum of a function using gradient descent, one takes steps proportional to the negative of the gradient (or of the approximate gradient) of the function at the current point. If instead one takes steps proportional to the positive of the gradient, one approaches a local maximum of that function; the procedure is then known as gradient ascent.
Gradient descent is also known as steepest descent, or the method of steepest descent. When known as the latter, gradient descent should not be confused with the method of steepest descent for approximating integrals.
Description

Gradient descent is based on the observation that if the multivariable function 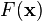 is defined and differentiable in a neighborhood of a point
is defined and differentiable in a neighborhood of a point 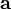 , then decreases fastest if one goes from in the direction of the negative gradient of
, then decreases fastest if one goes from in the direction of the negative gradient of 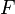 at ,
at , 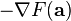 . It follows that, if
. It follows that, if
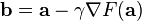
for 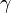 small enough, then
small enough, then 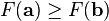 . With this observation in mind, one starts with a guess
. With this observation in mind, one starts with a guess 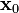 for a local minimum of , and considers the sequence
for a local minimum of , and considers the sequence
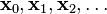 such that
such that
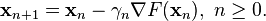
We have

so hopefully the sequence 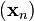 converges to the desired local minimum. Note that the value of the step size is allowed to change at every iteration. With certain assumptions on the function (for example, convex and
converges to the desired local minimum. Note that the value of the step size is allowed to change at every iteration. With certain assumptions on the function (for example, convex and 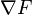 Lipschitz) and particular choices of (e.g., chosen via a line search that satisfies the Wolfe conditions), convergence to a local minimum can be guaranteed. When the function is convex, all local minima are also global minima, so in this case gradient descent can converge to the global solution.
Lipschitz) and particular choices of (e.g., chosen via a line search that satisfies the Wolfe conditions), convergence to a local minimum can be guaranteed. When the function is convex, all local minima are also global minima, so in this case gradient descent can converge to the global solution.
This process is illustrated in the picture to the right. Here is assumed to be defined on the plane, and that its graph has a bowl shape. The blue curves are the contour lines, that is, the regions on which the value of is constant. A red arrow originating at a point shows the direction of the negative gradient at that point. Note that the (negative) gradient at a point is orthogonal to the contour line going through that point. We see that gradient descent leads us to the bottom of the bowl, that is, to the point where the value of the function is minimal.
Examples
Gradient descent has problems with pathological functions such as the Rosenbrock function shown here.
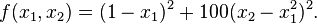
The Rosenbrock function has a narrow curved valley which contains the minimum. The bottom of the valley is very flat. Because of the curved flat valley the optimization is zig-zagging slowly with small stepsizes towards the minimum.

The "Zig-Zagging" nature of the method is also evident below, where the gradient ascent method is applied to 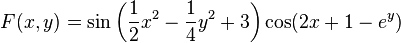 .
.
.png)
.png)
Limitations
For some of the above examples, gradient descent is relatively slow close to the minimum: technically, its asymptotic rate of convergence is inferior to many other methods. For poorly conditioned convex problems, gradient descent increasingly 'zigzags' as the gradients point nearly orthogonally to the shortest direction to a minimum point. For more details, see the comments below.
For non-differentiable functions, gradient methods are ill-defined. For locally Lipschitz problems and especially for convex minimization problems, bundle methods of descent are well-defined. Non-descent methods, like subgradient projection methods, may also be used.[1] These methods are typically slower than gradient descent. Another alternative for non-differentiable functions is to "smooth" the function, or bound the function by a smooth function. In this approach, the smooth problem is solved in the hope that the answer is close to the answer for the non-smooth problem (occasionally, this can be made rigorous).
Solution of a linear system
Gradient descent can be used to solve a system of linear equations, reformulated as a quadratic minimization problem, e.g., using linear least squares. The solution of
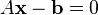
in the sense of linear least squares is defined as minimizing the function
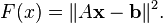
In traditional linear least squares for real 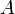 and
and 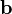 the Euclidean norm is used, in which case
the Euclidean norm is used, in which case
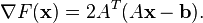
In this case, the line search minimization, finding the locally optimal step size on every iteration, can be performed analytically, and explicit formulas for the locally optimal are known.[2]
For solving linear equations, gradient descent is rarely used, with the conjugate gradient method being one of the most popular alternatives. The speed of convergence of gradient descent depends on the maximal and minimal eigenvalues of , while the speed of convergence of conjugate gradients has a more complex dependence on the eigenvalues, and can benefit from preconditioning. Gradient descent also benefits from preconditioning, but this is not done as commonly.
Solution of a non-linear system
Gradient descent can also be used to solve a system of nonlinear equations. Below is an example that shows how to use the gradient descent to solve for three unknown variables, x1, x2, and x3. This example shows one iteration of the gradient descent.
Consider a nonlinear system of equations:
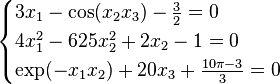
suppose we have the function
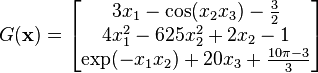
where
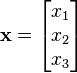
and the objective function
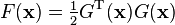
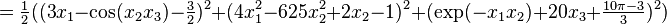
With initial guess
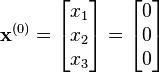
We know that
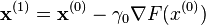
where
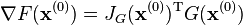
The Jacobian matrix 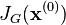
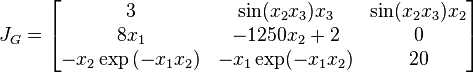
Then evaluating these terms at 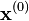
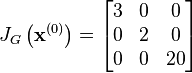
and
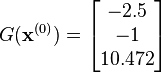
So that
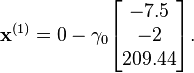
and
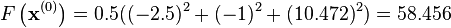

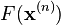 at current guess
at current guess 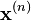 , and arrows show the direction of descent. Due to a small and constant step size, the convergence is slow.
, and arrows show the direction of descent. Due to a small and constant step size, the convergence is slow.Now a suitable 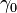 must be found such that
must be found such that 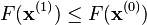 . This can be done with any of a variety of line search algorithms. One might also simply guess
. This can be done with any of a variety of line search algorithms. One might also simply guess 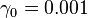 which gives
which gives
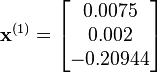
evaluating at this value,
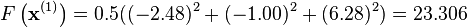
The decrease from 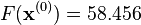 to the next step's value of
to the next step's value of 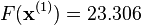 is a sizable decrease in the objective function. Further steps would reduce its value until a solution to the system was found.
is a sizable decrease in the objective function. Further steps would reduce its value until a solution to the system was found.
Comments
Gradient descent works in spaces of any number of dimensions, even in infinite-dimensional ones. In the latter case the search space is typically a function space, and one calculates the Gâteaux derivative of the functional to be minimized to determine the descent direction.[3]
The gradient descent can take many iterations to compute a local minimum with a required accuracy, if the curvature in different directions is very different for the given function. For such functions, preconditioning, which changes the geometry of the space to shape the function level sets like concentric circles, cures the slow convergence. Constructing and applying preconditioning can be computationally expensive, however.
The gradient descent can be combined with a line search, finding the locally optimal step size on every iteration. Performing the line search can be time-consuming. Conversely, using a fixed small can yield poor convergence.
Methods based on Newton's method and inversion of the Hessian using conjugate gradient techniques can be better alternatives.[4][5] Generally, such methods converge in fewer iterations, but the cost of each iteration is higher. An example is the BFGS method which consists in calculating on every step a matrix by which the gradient vector is multiplied to go into a "better" direction, combined with a more sophisticated line search algorithm, to find the "best" value of  For extremely large problems, where the computer memory issues dominate, a limited-memory method such as L-BFGS should be used instead of BFGS or the steepest descent.
For extremely large problems, where the computer memory issues dominate, a limited-memory method such as L-BFGS should be used instead of BFGS or the steepest descent.
Gradient descent can be viewed as Euler's method for solving ordinary differential equations 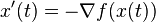 of a gradient flow.
of a gradient flow.
A computational example
The gradient descent algorithm is applied to find a local minimum of the function f(x)=x4−3x3+2, with derivative f'(x)=4x3−9x2. Here is an implementation in the Python programming language.
# From calculation, we expect that the local minimum occurs at x=9/4 x_old = 0 x_new = 6 # The algorithm starts at x=6 gamma = 0.01 # step size precision = 0.00001 def f_derivative(x): return 4 * x**3 - 9 * x**2 while abs(x_new - x_old) > precision: x_old = x_new x_new = x_old - gamma * f_derivative(x_old) print("Local minimum occurs at", x_new)
The above piece of code has to be modified with regard to step size according to the system at hand and convergence can be made faster by using an adaptive step size. In the above case the step size is not adaptive. It stays at 0.01 in all the directions which can sometimes cause the method to fail by diverging from the minimum.
Extensions
Gradient descent can be extended to handle constraints by including a projection onto the set of constraints. This method is only feasible when the projection is efficiently computable on a computer. Under suitable assumptions, this method converges. This method is a specific case of the forward-backward algorithm for monotone inclusions (which includes convex programming and variational inequalities).[6]
Fast proximal gradient method
Another extension of gradient descent is due to Yurii Nesterov from 1983,[7] and has been subsequently generalized. He provides a simple modification of the algorithm that enables faster convergence for convex problems. Specifically, if the function is convex and is Lipschitz, and it is not assumed that is strongly convex, then the error in the objective value generated at each step 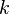 by the gradient descent method will be bounded by
by the gradient descent method will be bounded by 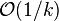 . Using the Nesterov acceleration technique, the error decreases at
. Using the Nesterov acceleration technique, the error decreases at 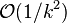 .[8]
.[8]
The momentum method
Yet another extension, that reduces the risk of getting stuck in a local minimum, as well as speeds up the convergence considerably in cases where the process would otherwise zig-zag heavily, is the momentum method, which uses a momentum term in analogy to "the mass of Newtonian particles that move through a viscous medium in a conservative force field".[9] This method is often used as an extension to the backpropagation algorithms used to train artificial neural networks.[10][11]
See also
- Conjugate gradient method
- Stochastic gradient descent
- Rprop
- Delta rule
- Wolfe conditions
- Preconditioning
- BFGS method
- Nelder–Mead method
- Extreme Learning Machines
References
- Mordecai Avriel (2003). Nonlinear Programming: Analysis and Methods. Dover Publishing. ISBN 0-486-43227-0.
- Jan A. Snyman (2005). Practical Mathematical Optimization: An Introduction to Basic Optimization Theory and Classical and New Gradient-Based Algorithms. Springer Publishing. ISBN 0-387-24348-8
- Cauchy, Augustin (1847). Méthode générale pour la résolution des systèmes d'équations simultanées. pp. 536–538.
- ↑ Kiwiel, Krzysztof C. (2001). "Convergence and efficiency of subgradient methods for quasiconvex minimization". Mathematical Programming (Series A) 90 (1) (Berlin, Heidelberg: Springer). pp. 1–25. doi:10.1007/PL00011414. ISSN 0025-5610. MR 1819784.
- ↑ Yuan, Ya-xiang (1999). "Step-sizes for the gradient method" (PDF). AMS/IP Studies in Advanced Mathematics (Providence, RI: American Mathematical Society) 42 (2): 785.
- ↑ G. P. Akilov, L. V. Kantorovich, Functional Analysis, Pergamon Pr; 2 Sub edition,ISBN 0-08-023036-9, 1982
- ↑ W. H. Press, S. A. Teukolsky, W. T. Vetterling, B. P. Flannery, Numerical Recipes in C: The Art of Scientific Computing, 2nd Ed., Cambridge University Press, New York, 1992
- ↑ T. Strutz: Data Fitting and Uncertainty (A practical introduction to weighted least squares and beyond). Vieweg+Teubner, Wiesbaden 2011, ISBN 978-3-8348-1022-9.
- ↑ P. L. Combettes and J.-C. Pesquet, "Proximal splitting methods in signal processing", in: Fixed-Point Algorithms for Inverse Problems in Science and Engineering, (H. H. Bauschke, R. S. Burachik, P. L. Combettes, V. Elser, D. R. Luke, and H. Wolkowicz, Editors), pp. 185-212. Springer, New York, 2011.
- ↑ Yu. Nesterov, "Introductory Lectures on Convex Optimization. A Basic Course" (Springer, 2004, ISBN 1-4020-7553-7)
- ↑ Fast Gradient Methods, lecture notes by Prof. Lieven Vandenberghe for EE236C at UCLA
- ↑ Qian, Ning (January 1999). "On the momentum term in gradient descent learning algorithms" (PDF). Neural Networks 12 (1): 145–151. Retrieved 17 October 2014.
- ↑ "Momentum and Learning Rate Adaptation". Willamette University. Retrieved 17 October 2014.
- ↑ Geoffrey Hinton; Nitish Srivastava; Kevin Swersky. "6 - 3 - The momentum method". YouTube. Retrieved 18 October 2014. Part of a lecture series for the Coursera online course Neural Networks for Machine Learning.