Git (software)
|
| |
|
Screenshot  A command-line session showing repository creation, addition of a file, and remote synchronization | |
| Original author(s) | Linus Torvalds |
|---|---|
| Developer(s) |
Junio Hamano, Linus Torvalds, and many others |
| Initial release | 7 April 2005 |
| Stable release | 2.4.0 / 1 May 2015 |
| Development status | Active |
| Written in | C, Bourne Shell, Tcl, Perl[1] |
| Operating system | Linux, POSIX, Windows, OS X |
| Type | Version control |
| License | GNU General Public License v2,[2] GNU Lesser General Public License 2.1[3] |
| Website |
git-scm |
Git (/ɡɪt/[4]) is a distributed revision control system with an emphasis on speed,[5] data integrity,[6] and support for distributed, non-linear workflows.[7] Git was initially designed and developed by Linus Torvalds for Linux kernel development in 2005, and has since become the most widely adopted version control system for software development.[8]
As with most other distributed revision control systems, and unlike most client–server systems, every Git working directory is a full-fledged repository with complete history and full version-tracking capabilities, independent of network access or a central server.[9] Like the Linux kernel, Git is free software distributed under the terms of the GNU General Public License version 2.
History
Git development began in April 2005 after many developers of the Linux kernel gave up access to BitKeeper, a proprietary source control management (SCM) system that had previously been used to maintain the project.[10] The copyright holder of BitKeeper, Larry McVoy, had withdrawn gratis use of the product after claiming that Andrew Tridgell had reverse-engineered the BitKeeper protocols.
Torvalds wanted a distributed system that he could use like BitKeeper, but none of the available free systems met his needs, particularly in terms of performance. Torvalds took an example of a source control management system requiring thirty seconds to apply a patch and update all associated metadata, and noted that this would not scale to the needs of Linux kernel development, where syncing with fellow maintainers could require 250 such actions at a time. He wanted patching to take three seconds,[5] and had several other design criteria in mind:
- take Concurrent Versions System (CVS) as an example of what not to do; if in doubt, make the exact opposite decision[7]
- support a distributed, BitKeeper-like workflow[7]
- very strong safeguards against corruption, either accidental or malicious.[6]
These three criteria eliminated every then-existing version control system, except for Monotone. Considering performance excluded this too.[7] So immediately after the 2.6.12-rc2 Linux kernel development release,[7] Torvalds set out to write his own.[7]
Torvalds has quipped about the name git, which is British English slang meaning "unpleasant person". Torvalds said: "I'm an egotistical bastard, and I name all my projects after myself. First 'Linux', now 'git'."[11][12] The man page describes Git as "the stupid content tracker".[13]
The development of Git began on 3 April 2005.[14] The project was announced on 6 April,[15] and became self-hosting as of 7 April.[14] The first merge of multiple branches was done on 18 April.[16] Torvalds achieved his performance goals; on 29 April, the nascent Git was benchmarked recording patches to the Linux kernel tree at the rate of 6.7 per second.[17] On 16 June Git managed the kernel 2.6.12 release.[18] Torvalds turned over maintenance on 26 July 2005 to Junio Hamano, a major contributor to the project.[19] Hamano was responsible for the 1.0 release on 21 December 2005, and remains the project's maintainer.[20]
Design
Git's design was inspired by BitKeeper and Monotone.[21][22] Git was originally designed as a low-level version control system engine on top of which others could write front ends, such as Cogito or StGIT.[22] The core Git project has since become a complete version control system that is usable directly.[23] While strongly influenced by BitKeeper, Torvalds deliberately avoided conventional approaches, leading to a unique design.[24]
Characteristics
Git's design is a synthesis of Torvalds's experience with Linux in maintaining a large distributed development project, along with his intimate knowledge of file system performance gained from the same project and the urgent need to produce a working system in short order. These influences led to the following implementation choices:
- Strong support for non-linear development
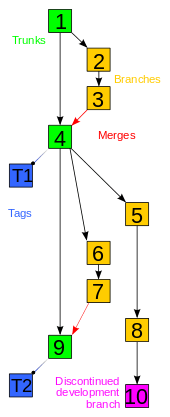
- Git supports rapid branching and merging, and includes specific tools for visualizing and navigating a non-linear development history. A core assumption in Git is that a change will be merged more often than it is written, as it is passed around various reviewers. Branches in Git are very lightweight: A branch in Git is only a reference to a single commit. With its parental commits, the full branch structure can be constructed.
- Distributed development
- Like Darcs, BitKeeper, Mercurial, SVK, Bazaar and Monotone, Git gives each developer a local copy of the entire development history, and changes are copied from one such repository to another. These changes are imported as additional development branches, and can be merged in the same way as a locally developed branch.
- Compatibility with existing systems/protocols
- Repositories can be published via HTTP, FTP, rsync, or a Git protocol over either a plain socket, or ssh. Git also has a CVS server emulation, which enables the use of existing CVS clients and IDE plugins to access Git repositories. Subversion and svk repositories can be used directly with git-svn.
- Efficient handling of large projects
- Torvalds has described Git as being very fast and scalable,[25] and performance tests done by Mozilla [26] showed it was an order of magnitude faster than some version-control systems, and fetching version history from a locally stored repository can be one hundred times faster than fetching it from the remote server.[27]
- Cryptographic authentication of history
- The Git history is stored in such a way that the ID of a particular version (a commit in Git terms) depends upon the complete development history leading up to that commit. Once it is published, it is not possible to change the old versions without it being noticed. The structure is similar to a Merkle tree, but with additional data at the nodes as well as the leaves.[28] (Mercurial and Monotone also have this property.)
- Toolkit-based design
- Git was designed as a set of programs written in C, and a number of shell scripts that provide wrappers around those programs.[29] Although most of those scripts have since been rewritten in C for speed and portability, the design remains, and it is easy to chain the components together.[30]
- Pluggable merge strategies
- As part of its toolkit design, Git has a well-defined model of an incomplete merge, and it has multiple algorithms for completing it, culminating in telling the user that it is unable to complete the merge automatically and that manual editing is required.
- Garbage accumulates unless collected
- Aborting operations or backing out changes will leave useless dangling objects in the database. These are generally a small fraction of the continuously growing history of wanted objects. Git will automatically perform garbage collection when enough loose objects have been created in the repository. Garbage collection can be called explicitly using
git gc --prune.[31] - Periodic explicit object packing
- Git stores each newly created object as a separate file. Although individually compressed, this takes a great deal of space and is inefficient. This is solved by the use of packs that store a large number of objects in a single file (or network byte stream) called packfile, delta-compressed among themselves. Packs are compressed using the heuristic that files with the same name are probably similar, but do not depend on it for correctness. A corresponding index file is created for each packfile, telling the offset of each object in the packfile. Newly created objects (newly added history) are still stored singly, and periodic repacking is required to maintain space efficiency. The process of packing the repository can be very computationally expensive. By allowing objects to exist in the repository in a loose, but quickly generated format, Git allows the expensive pack operation to be deferred until later when time does not matter (e.g. the end of the work day). Git does periodic repacking automatically but manual repacking is also possible with the git gc command. For data integrity, both packfile and its index have SHA-1 checksum inside, and also the file name of packfile contains a SHA-1 checksum. To check integrity, run the git fsck command.
Another property of Git is that it snapshots directory trees of files. The earliest systems for tracking versions of source code, SCCS and RCS, worked on individual files and emphasized the space savings to be gained from interleaved deltas (SCCS) or delta encoding (RCS) the (mostly similar) versions. Later revision control systems maintained this notion of a file having an identity across multiple revisions of a project. However, Torvalds rejected this concept.[32] Consequently, Git does not explicitly record file revision relationships at any level below the source code tree.
Implicit revision relationships have some significant consequences:
- It is slightly more expensive to examine the change history of a single file than the whole project.[33] To obtain a history of changes affecting a given file, Git must walk the global history and then determine whether each change modified that file. This method of examining history does, however, let Git produce with equal efficiency a single history showing the changes to an arbitrary set of files. For example, a subdirectory of the source tree plus an associated global header file is a very common case.
- Renames are handled implicitly rather than explicitly. A common complaint with CVS is that it uses the name of a file to identify its revision history, so moving or renaming a file is not possible without either interrupting its history, or renaming the history and thereby making the history inaccurate. Most post-CVS revision control systems solve this by giving a file a unique long-lived name (a sort of inode number) that survives renaming. Git does not record such an identifier, and this is claimed as an advantage.[34][35] Source code files are sometimes split or merged as well as simply renamed,[36] and recording this as a simple rename would freeze an inaccurate description of what happened in the (immutable) history. Git addresses the issue by detecting renames while browsing the history of snapshots rather than recording it when making the snapshot.[37] (Briefly, given a file in revision N, a file of the same name in revision N−1 is its default ancestor. However, when there is no like-named file in revision N−1, Git searches for a file that existed only in revision N−1 and is very similar to the new file.) However, it does require more CPU-intensive work every time history is reviewed, and a number of options to adjust the heuristics. This mechanism does not always work; sometimes a file that is renamed with changes in the same commit is read as a deletion of the old file and the creation of a new file. Developers can work around this limitation by committing the rename and changes separately.
Git implements several merging strategies; a non-default can be selected at merge time:[38]
- resolve: the traditional three-way merge algorithm.
- recursive: This is the default when pulling or merging one branch, and is a variant of the three-way merge algorithm.
When there are more than one common ancestors that can be used for three-way merge, it creates a merged tree of the common ancestors and uses that as the reference tree for the three-way merge. This has been reported to result in fewer merge conflicts without causing mis-merges by tests done on actual merge commits taken from Linux 2.6 kernel development history. Additionally this can detect and handle merges involving renames.
—Linus Torvalds[39]
- octopus: This is the default when merging more than two heads.
Data structures
Git's primitives are not inherently a source code management (SCM) system. Torvalds explains,[40]
In many ways you can just see git as a filesystem — it is content-addressable, and it has a notion of versioning, but I really really designed it coming at the problem from the viewpoint of a filesystem person (hey, kernels is what I do), and I actually have absolutely zero interest in creating a traditional SCM system.
From this initial design approach, Git has developed the full set of features expected of a traditional SCM,[23] with features mostly being created as needed, then refined and extended over time.

Git has two data structures: a mutable index (also called stage or cache) that caches information about the working directory and the next revision to be committed; and an immutable, append-only object database.
The object database contains four types of objects:
- A blob (binary large object) is the content of a file. Blobs have no file name, time stamps, or other metadata.
- A tree object is the equivalent of a directory. It contains a list of file names, each with some type bits and the name of a blob or tree object that is that file, symbolic link, or directory's contents. This object describes a snapshot of the source tree.
- A commit object links tree objects together into a history. It contains the name of a tree object (of the top-level source directory), a time stamp, a log message, and the names of zero or more parent commit objects.
- A tag object is a container that contains reference to another object and can hold additional meta-data related to another object. Most commonly, it is used to store a digital signature of a commit object corresponding to a particular release of the data being tracked by Git.
The index serves as connection point between the object database and the working tree.
Each object is identified by a SHA-1 hash of its contents. Git computes the hash, and uses this value for the object's name. The object is put into a directory matching the first two characters of its hash. The rest of the hash is used as the file name for that object.
Git stores each revision of a file as a unique blob. The relationships between the blobs can be found through examining the tree and commit objects. Newly added objects are stored in their entirety using zlib compression. This can consume a large amount of disk space quickly, so objects can be combined into packs, which use delta compression to save space, storing blobs as their changes relative to other blobs.
Git servers typically listen on TCP port 9418.[41]
References
Every object in the Git database which is not referred to may be cleaned up by using a garbage collection command, or automatically. An object may be referenced by another object, or an explicit reference. Git knows different types of references. The commands to create, move, and delete references vary. "git show-ref" lists all references. Some types are:
- heads
- refers to an object locally.
- remotes
- refers to an object which exists in a remote repository.
- stash
- refers to an object not yet committed.
- meta
- e.g. a configuration in a bare repository, user rights. The refs/meta/config namespace was introduced resp gets used by Gerrit (software)[42]
- tags
- see above.
Implementations

Git is primarily developed on Linux, although it also supports most major operating systems including BSD, Solaris, OS X, and Microsoft Windows.[43]
The JGit implementation of Git is a pure Java software library, designed to be embedded in any Java application. JGit is used in the Gerrit code review tool and in EGit, a Git client for the Eclipse IDE.[44]
The Dulwich implementation of Git is a pure Python software component for Python 2.[45]
The libgit2 implementation of Git is an ANSI C software library with no other dependencies, which can be built on multiple platforms including Microsoft Windows, Linux, Mac OS X, and BSD.[46] It has bindings for many programming languages, including Ruby, Python and Haskell.[47][48][49]
JS-Git is a JavaScript implementation of a subset of Git.[50]
Git server
As Git is a distributed version control system, it can be used as a server out of the box. Dedicated Git server software helps, amongst other features, to add access control, display the contents of a Git repository via the web, and help managing multiple repositories.
Remote file store and shell access
A Git repository can be cloned to a shared file system, and accessed by other persons. It can also be accessed via remote shell just by having the Git software installed and allowing a user to log in.[51]
Git daemon, instaweb
Git daemon allows users to share their own repository to colleagues quickly. Git instaweb allows users to provide web view to the repository. As of 2014-04 instaweb does not work on Windows. Both can be seen in the line of Mercurial's "hg serve".[52][53]
Gitolite
Gitolite is an access control layer on top of Git, providing fine access control to Git repositories. It relies on other software to remotely view the repositories on the server.[54][55]
Gerrit
Gerrit provides two out of three functionalities: access control, and managing repositories. It uses jGit. To view repositories it is combined e.g. with Gitiles or GitBlit.
Gitblit
Gitblit can provide all three functions, but is in larger installations used as repository browser installed with gerrit for access control and management of repositories.[56][57] Gitblit can also provide the sync option for other repository.
Gitiles
Gitiles is a simple repository browser, usually used together with gerrit.[58][59]
Bonobo Git Server
Bonobo Git Server is a simple Git server for Windows implemented as an ASP.NET gateway.[60] It relies on the authentication mechanisms provided by Windows Internet Information Services, thus it does not support SSH access but can be easily integrated with Active Directory.
Gitorious
Gitorious is the free software behind the Git repository hosting service of the same name. In March 2015 Gitorious was acquired by GitLab.[61]
GitLab
GitLab provides a software repository service. It offers a web interface like GitHub, and is written in Ruby.
Gogs
Gogs is another self-hosted Git service, written in Go. It provides similar features to GitLab as a web interface.
GitHub
GitHub is a web-based Git repository hosting service, which offers all of the distributed revision control and source code management (SCM) functionality of Git as well as adding its own features. Unlike Git, which is strictly a command-line tool, GitHub provides a web-based graphical interface and desktop as well as mobile integration. It also provides access control and several collaboration features such as wikis, task management, and bug tracking and feature requests for every project.
Bitbucket
Bitbucket is a web-based hosting service for projects that use either the Git (since October 2011) or the Mercurial (since launch) revision control systems. Bitbucket offers both commercial plans and free accounts.
Commercial products
Commercial programs are also available to be installed on premises, amongst them GitHub Software (using native Git, available as a vm), Stash (using jGit), Team Foundation Server (using libgit2).[62]
Adoption
The Eclipse Foundation reported in its annual community survey that as of May 2014, Git is now the most widely used source code management tool, with 42.9% of professional software developers reporting that they use Git or GitHub as their primary source control system[8] compared with 36.3% in 2013, 32% in 2012; or for Git responses alone 33.3% in 2014, 30.3% in 2013, 27.6% in 2012 and 12.8% in 2011.[63] Open source directory Black Duck Open Hub reports a similar uptake among open source projects.[64]
The UK IT jobs website itjobswatch.co.uk reports that as of late December 2014, 23.58% of UK permanent software development job openings have cited Git,[65] ahead of 16.34% for Subversion,[66] 11.58% for Microsoft Team Foundation Server,[67] 1.62% for Mercurial,[68] and 1.13% for Visual SourceSafe.[69]
Notable vulnerabilities
CVE-2014-9390
On 17 December 2014, an exploit was found affecting the Windows and Mac versions of the Git client. An attacker could perform arbitrary code execution on a Windows or Mac computer with Git installed by creating a malicious Git tree (directory) named .git (a directory in Git repositories that stores all the data of the repository) in a different case (such as .GIT or .Git, needed because Git doesn't allow the all-lowercase version of .git to be created manually) with malicious files in the .git/hooks subdirectory (a folder with executable files that Git runs) on a repository that the attacker made or on a repository that the attacker can modify. If a Windows or Mac user "pulls" (downloads) a version of the repository with the malicious directory, then switches to that directory, the .git directory will be overwritten (due to the case-insensitive nature of the Windows and Mac filesystems) and the malicious executable files in .git/hooks may be run, which results in the attacker's commands being executed. An attacker could also modify the .git/config subdirectory, which allows the attacker to create malicious Git aliases (aliases for Git commands or external commands) or modify existing aliases to execute malicious commands when run. When the malicious aliases are run, the malicious commands are executed. The vulnerability was patched in version 2.2.1 of Git, released on 17 December 2014, and announced on the next day.[70][71]
See also
- Comparison of revision control software
- Comparison of source code hosting facilities
- List of revision control software
References
- ↑ "git/git.git/tree". git.kernel.org. Retrieved 2009-06-15.
- ↑ "Git's GPL license at github.com". github.com. 18 January 2010. Retrieved 12 October 2014.
- ↑ "Git's LGPL license at github.com". github.com. 20 May 2011. Retrieved 12 October 2014.
- ↑ "Tech Talk: Linus Torvalds on git (at 00:01:30)". YouTube. Retrieved 2014-07-20.
- ↑ 5.0 5.1 Torvalds, Linus (2005-04-07). "Re: Kernel SCM saga..". linux-kernel (Mailing list). "So I'm writing some scripts to try to track things a whole lot faster."
- ↑ 6.0 6.1 Torvalds, Linus (2007-06-10). "Re: fatal: serious inflate inconsistency". git (Mailing list). A brief description of Git's data integrity design goals.
- ↑ 7.0 7.1 7.2 7.3 7.4 7.5 Linus Torvalds (2007-05-03). Google tech talk: Linus Torvalds on git. Event occurs at 02:30. Retrieved 2007-05-16.
- ↑ 8.0 8.1 "Eclipse Community Survey 2014 results | Ian Skerrett". Ianskerrett.wordpress.com. 2014-06-23. Retrieved 2014-06-23.
- ↑ Chacon, Scott (24 December 2014). Pro Git (2nd ed.). New York, NY: Apress. pp. 29–30. ISBN 978-1484200773.
- ↑ BitKeeper and Linux: The end of the road? | linux.com
- ↑ "GitFaq: Why the 'git' name?". Git.or.cz. Retrieved 2012-07-14.
- ↑ "After controversy, Torvalds begins work on 'git'". PC World. 2012-07-14.
Torvalds seemed aware that his decision to drop BitKeeper would also be controversial. When asked why he called the new software, "git", British slang meaning "a rotten person", he said. "I'm an egotistical bastard, so I name all my projects after myself. First Linux, now git"
- ↑ "git(1) Manual Page". Retrieved 2012-07-21.
- ↑ 14.0 14.1 Torvalds, Linus (2007-02-27). "Re: Trivia: When did git self-host?". git (Mailing list).
- ↑ Torvalds, Linus (2005-04-06). "Kernel SCM saga..". linux-kernel (Mailing list).
- ↑ Torvalds, Linus (2005-04-17). "First ever real kernel git merge!". git (Mailing list).
- ↑ Mackall, Matt (2005-04-29). "Mercurial 0.4b vs git patchbomb benchmark". git (Mailing list).
- ↑ Torvalds, Linus (2005-06-17). "Linux 2.6.12". git-commits-head (Mailing list).
- ↑ Torvalds, Linus (2005-07-27). "Meet the new maintainer...". git (Mailing list).
- ↑ Hamano, Junio C. (2005-12-21). "Announce: Git 1.0.0". git (Mailing list).
- ↑ Torvalds, Linus (2006-05-05). "Re: [ANNOUNCE] Git wiki". linux-kernel (Mailing list). "Some historical background" on Git's predecessors
- ↑ 22.0 22.1 Torvalds, Linus (2005-04-08). "Re: Kernel SCM saga". linux-kernel (Mailing list). Retrieved 2008-02-20.
- ↑ 23.0 23.1 Torvalds, Linus (2006-03-23). "Re: Errors GITtifying GCC and Binutils". git (Mailing list).
- ↑ Torvalds, Linus (2006-10-20). "Re: VCS comparison table". git (Mailing list). A discussion of Git vs. BitKeeper
- ↑ Torvalds, Linus (2006-10-19). "Re: VCS comparison table". git (Mailing list).
- ↑ Jst's Blog on Mozillazine "bzr/hg/git performance". Retrieved 12 February 2015.
- ↑ Dreier, Roland (2006-11-13). "Oh what a relief it is"., observing that "git log" is 100x faster than "svn log" because the latter has to contact a remote server.
- ↑ "Trust". Git Concepts. Git User's Manual. 2006-10-18.
- ↑ Torvalds, Linus. "Re: VCS comparison table". git (Mailing list). Retrieved 2009-04-10., describing Git's script-oriented design
- ↑ iabervon (2005-12-22). "Git rocks!"., praising Git's scriptability
- ↑ "Git User's Manual". 2007-08-05.
- ↑ Torvalds, Linus (2005-04-10). "Re: more git updates..". linux-kernel (Mailing list).
- ↑ Haible, Bruno (2007-02-11). "how to speed up "git log"?". git (Mailing list).
- ↑ Torvalds, Linus (2006-03-01). "Re: impure renames / history tracking". git (Mailing list).
- ↑ Hamano, Junio C. (2006-03-24). "Re: Errors GITtifying GCC and Binutils". git (Mailing list).
- ↑ Hamano, Junio C. (2006-03-23). "Re: Errors GITtifying GCC and Binutils". git (Mailing list).
- ↑ Torvalds, Linus (2006-11-28). "Re: git and bzr". git (Mailing list)., on using
git-blameto show code moved between source files - ↑ Torvalds, Linus (2007-07-18). "git-merge(1)".
- ↑ Torvalds, Linus (2007-07-18). "CrissCrossMerge".
- ↑ Torvalds, Linus (2005-04-10). "Re: more git updates...". linux-kernel (Mailing list).
- ↑ "1.4 Getting Started - Installing Git". http://git-scm.com. Retrieved 2013-11-01.
- ↑ Gerrit Code Review - Project Configuration File Format
- ↑ "downloads". Retrieved 14 May 2012.
- ↑ "JGit". Retrieved 24 Aug 2012.
- ↑ "Dulwich". Retrieved 27 Aug 2012.
- ↑ "libgit2". Retrieved 24 Aug 2012.
- ↑ "rugged". Retrieved 24 Aug 2012.
- ↑ "pygit2". Retrieved 24 Aug 2012.
- ↑ "hlibgit2". Retrieved 30 Apr 2013.
- ↑ https://github.com/creationix/js-git "js-git: a JavaScript implementation of Git." Retrieved 13 August 2013.
- ↑ 4.4 Git on the Server - Setting Up the Server, Pro Git.
- ↑ hosting a Git repository on windows
- ↑ git-instaweb manual page
- ↑ Hosting git repositories
- ↑ gitolite source code and description
- ↑ Gitblit Homepage
- ↑ Wikimedia Gitblit installation
- ↑ Gitiles Homepage
- ↑ Android source code repositories
- ↑
- ↑ "GitLab acquires Gitorious to bolster its on premises code collaboration platform". GitLab. 3 March 2015. Retrieved 13 March 2015.
- ↑ "Microsoft embraces git with new TFS support, Visual Studio integration". Retrieved 1 Feb 2013.
- ↑ "Results of Eclipse Community Survey 2012".
- ↑ "Compare Repositories - Open Hub".
- ↑ "Git (software) Jobs, Average Salary for Git Distributed Version Control System Skills". Itjobswatch.co.uk. Retrieved 2014-12-31.
- ↑ "Subversion Jobs, Average Salary for Apache Subversion (SVN) Skills". Itjobswatch.co.uk. Retrieved 2014-12-31.
- ↑ "Team Foundation Server Jobs, Average Salary for Microsoft Team Foundation Server (TFS) Skills". Itjobswatch.co.uk. Retrieved 2014-12-31.
- ↑ "Mercurial Jobs, Average Salary for Mercurial Skills". Itjobswatch.co.uk. Retrieved 2014-12-31.
- ↑ "VSS/SourceSafe Jobs, Average Salary for Microsoft Visual SourceSafe (VSS) Skills". Itjobswatch.co.uk. Retrieved 2014-12-31.
- ↑ Pettersen, Tim (20 December 2014). "Securing your Git server against CVE-2014-9390". Retrieved 22 December 2014.
- ↑ Hamano, J, C. (18 December 2014). "[ANNOUNCE] Git v2.2.1 (and updates to older maintenance tracks)". Newsgroup: gmane.comp.version-control.git gmane.linux.kernel, gmane.comp.version-control.git. Retrieved 22 December 2014.
External links
| Wikimedia Commons has media related to Git. |
| Wikibooks has a book on the topic of: Git |
| ||||||||||||||||||||||||||||||||||||||||||||||||