Generalized Hebbian Algorithm
The Generalized Hebbian Algorithm (GHA), also known in the literature as Sanger's rule, is a linear feedforward neural network model for unsupervised learning with applications primarily in principal components analysis. First defined in 1989,[1] it is similar to Oja's rule in its formulation and stability, except it can be applied to networks with multiple outputs. The name originates because of the similarity between the algorithm and a hypothesis made by Donald Hebb[2] about the way in which synaptic strengths in the brain are modified in response to experience, i.e., that changes are proportional to the correlation between the firing of pre- and post-synaptic neurons.[3]
Theory
GHA combines Oja's rule with the Gram-Schmidt process to produce a learning rule of the form
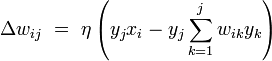 ,
,
where wij defines the synaptic weight or connection strength between the ith input and jth output neurons, x and y are the input and output vectors, respectively, and η is the learning rate parameter.
Derivation
In matrix form, Oja's rule can be written
![\,\frac{d w(t)}{d t} ~ = ~ w(t) Q - \mathrm{diag} [w(t) Q w(t)^{\mathrm{T}}] w(t)](../I/m/795356d5a6ed6c531bce87d6de4386cd.png) ,
,
and the Gram-Schmidt algorithm is
![\,\Delta w(t) ~ = ~ -\mathrm{lower} [w(t) w(t)^{\mathrm{T}}] w(t)](../I/m/2b8e391429f8019ff1b67e325463c2d9.png) ,
,
where w(t) is any matrix, in this case representing synaptic weights, Q = η x xT is the autocorrelation matrix, simply the outer product of inputs, diag is the function that diagonalizes a matrix, and lower is the function that sets all matrix elements on or above the diagonal equal to 0. We can combine these equations to get our original rule in matrix form,
![\,\Delta w(t) ~ = ~ \eta(t) \left(\mathbf{y}(t) \mathbf{x}(t)^{\mathrm{T}} - \mathrm{LT}[\mathbf{y}(t)\mathbf{y}(t)^{\mathrm{T}}] w(t)\right)](../I/m/80cbbb8cca174e580eacd68c8060de52.png) ,
,
where the function LT sets all matrix elements above the diagonal equal to 0, and note that our output y(t) = w(t) x(t) is a linear neuron.[1]
Stability and PCA
Applications
GHA is used in applications where a self-organizing map is necessary, or where a feature or principal components analysis can be used. Examples of such cases include artificial intelligence and speech and image processing.
Its importance comes from the fact that learning is a single-layer process—that is, a synaptic weight changes only depending on the response of the inputs and outputs of that layer, thus avoiding the multi-layer dependence associated with the backpropagation algorithm. It also has a simple and predictable trade-off between learning speed and accuracy of convergence as set by the learning rate parameter η.[4]
See also
- Hebbian learning
- Oja's rule
- Factor analysis
- PCA network
References
- ↑ 1.0 1.1 Sanger, Terence D. (1989). "Optimal unsupervised learning in a single-layer linear feedforward neural network". Neural Networks 2 (6): 459–473. doi:10.1016/0893-6080(89)90044-0. Retrieved 2007-11-24.
- ↑ Hebb, D.O. (1949). "The Organization of Behavior". New York: Wiley & Sons.
- ↑ Hertz; Anders Krough; Richard G. Palmer (1991). "Introduction to the Theory of Neural Computation". Redwood City, CA: Addison-Wesley Publishing Company. ISBN 0201515601.
- ↑ 4.0 4.1 Haykin, Simon (1998). Neural Networks: A Comprehensive Foundation (2 ed.). Prentice Hall. ISBN 0-13-273350-1.
- ↑ Oja, Erkki (November 1982). "Simplified neuron model as a principal component analyzer". Journal of Mathematical Biology 15 (3): 267–273. doi:10.1007/BF00275687. PMID 7153672. BF00275687. Retrieved 2007-11-22.