Gain (information retrieval)
The gain, also called improvement over random can be specified for a classifier and is an important measure to describe the performance of it.
Definition
In the following a random classifier is defined such that it randomly predicts the same amount of either class.
The gain is defined as described in the following:
Gain in Precision
The random precision of a classifier is defined as
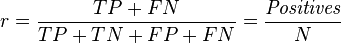
where TP, TN, FP and FN are the numbers of true positives, true negatives, false positives and false negatives respectively, positives is the number of positive instances in the target dataset and N is the size of the dataset.
The random precision defines the lowest baseline of a classifier.
And Gain is defined as
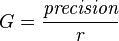
which gives a factor by which a classifier is better when compared to its random counterpart. A Gain of 1 would indicate a classifier that is not better than random. The larger the gain, the better.
Gain in Overall Accuracy
The accuracy of a classifier in general is defined as
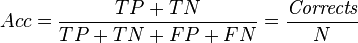
Here, the random accuracy of a classifier can be defined as
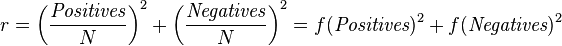
f(Positives) and f(Negatives) is the fraction of positive and negative classes in the dataset.
And again gain is
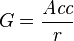
This time the gain is measured not only with respect to the prediction of a so-called positive class, but with respect to the overall classifier ability to distinguish the two equally important classes.
Application
In Bioinformatics as an example, the gain is measured for methods that predict residue contacts in proteins.
See also
- Accuracy and precision
- Binary classification
- Brier score
- Confusion matrix
- Detection theory
- F-score
- Information retrieval
- Matthews correlation coefficient
- Receiver operating characteristic or ROC curve
- Selectivity
- Sensitivity and specificity
- Sensitivity index
- Statistical significance
- Youden's J statistic