Federated search
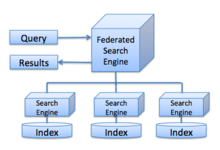
Federated search is an information retrieval technology that allows the simultaneous search of multiple searchable resources. A user makes a single query request which is distributed to the search engines participating in the federation. The federated search then aggregates the results that are received from the search engines for presentation to the user.
Purpose
Federated search came about to meet the need of searching multiple disparate content sources with one query. This allows a user to search multiple databases at once in real time, arrange the results from the various databases into a useful form and then present the results to the user.
Process
As described by Peter Jacso (2004[1]), federated searching consists of (1) transforming a query and broadcasting it to a group of disparate databases or other web resources, with the appropriate syntax, (2) merging the results collected from the databases, (3) presenting them in a succinct and unified format with minimal duplication, and (4) providing a means, performed either automatically or by the portal user, to sort the merged result set.
Federated search portals, either commercial or open access, generally search public access bibliographic databases, public access Web-based library catalogues (OPACs), Web-based search engines like Google and/or open-access, government-operated or corporate data collections. These individual information sources send back to the portal's interface a list of results from the search query. The user can review this hit list. Some portals will merely screen scrape the actual database results and not directly allow a user to enter the information source's application. More sophisticated ones will de-dupe the results list by merging and removing duplicates. There are additional features available in many portals, but the basic idea is the same: to improve the accuracy and relevance of individual searches as well as reduce the amount of time required to search for resources.
This process allows federated search some key advantages when compared with existing crawler-based search engines. Federated search need not place any requirements or burdens on owners of the individual information sources, other than handling increased traffic. Federated searches are inherently as current as the individual information sources, as they are searched in real time.
Implementation
One application of federated searching is the metasearch engine; however, this is not a complete solution as many documents are not currently indexed. These documents are on what is known as the deep Web, or invisible Web. Many more information sources are not yet stored in electronic form. Google Scholar is one example of many projects trying to address this.
When the search vocabulary or data model of the search system is different from the data model of one or more of the foreign target systems the query must be translated into each of the foreign target systems. This can be done using simple data-element translation or may require semantic translation.
A challenge faced in the implementation of federated search engines is scalability, in other words, the performance of the site as the number of information sources comprising the federated search engine increase. One federated search engine that has begun to address this issue is WorldWideScience, hosted by the U.S. Department of Energy's Office of Scientific and Technical Information. WorldWideScience [2] is composed of more than 40 information sources, several of which are federated search portals themselves. One such portal is Science.gov [3] which itself federates more than 30 information sources representing most of the R&D output of the U.S. Federal government. Science.gov returns its highest ranked results to WorldWideScience, which then merges and ranks these results with the search returned by the other information sources that comprise WorldWideScience.[3] This approach of cascaded federated search enables large number of information sources to be searched via a single query.
Another application Sesam running in both Norway and Sweden has been built on top of an open sourced platform specialised for federated search solutions. Sesat,[4] an acronym for Sesam Search Application Toolkit, is a platform that provides much of the framework and functionality required for handling parallel and pipelined searches and displaying them elegantly in a user interface, allowing engineers to focus on the index/database configuration tuning.
Challenges
When federated search is performed against secure data sources, the users' credentials must be passed on to each underlying search engine, so that appropriate security is maintained. If the user has different login credentials for different systems, there must be a means to map their login ID to each search engine's security domain.[5]
Another challenge is mapping results list navigators into a common form. Suppose 3 real-estate sites are searched, each provides a list of hyperlinked city names to click on, to see matches only in each city. Ideally these facets would be combined into one set, but that presents additional technical challenges.[6] The system also needs to understand "next page" links if it's going to allow the user to page through the combined results.
Further reading
- Federated Search 101. Linoski, Alexis, Walczyk, Tine, Library Journal, Summer 2008 Net Connect, Vol. 133 Note: this content has been moved here, but you will need a remote access account through your local library to get the whole article.
- Cox, Christopher N. Federated Search: Solution or Setback for Online Library Services. Binghamton, NY: Haworth Information Press, 2007.Table of Contents
- Federated Search Primer. Lederman, S., AltSearchEngines, January 2009 Note: This material has been reposted here, on the blog of a commercial search engine company.
- Milad Shokouhi and Luo Si, Federated Search, Foundations and Trends® in Information Retrieval: Vol. 5: No 1, pp 1-102., http://dx.doi.org/10.1561/1500000010
See also
References
- ↑ Thoughts About Federated Searching. Jacsó, Péter, Information Today, Oct 2004, Vol. 21, Issue 9
- ↑ WorldWideScience
- ↑ 3.0 3.1 Science.gov
- ↑ Sesat
- ↑ Mapping Security Requirements to Enterprise Search
- ↑ 20+ Differences Between Internet vs. Enterprise Search - part 1
| ||||||||||||||||||||||