Feature selection
| Machine learning and data mining |
|---|
 |
| Problems |
| Clustering |
|
| Dimensionality reduction |
| Structured prediction |
| Anomaly detection |
|
| Neural nets |
| Theory |
|
|
In machine learning and statistics, feature selection, also known as variable selection, attribute selection or variable subset selection, is the process of selecting a subset of relevant features for use in model construction. The central assumption when using a feature selection technique is that the data contains many redundant or irrelevant features. Redundant features are those which provide no more information than the currently selected features, and irrelevant features provide no useful information in any context.
Feature selection techniques is to be distinguished from feature extraction. Feature extraction creates new features from functions of the original features, whereas feature selection returns a subset of the features. Feature selection techniques are often used in domains where there are many features and comparatively few samples (or data points). The archetypal case is the use of feature selection in analysing DNA microarrays, where there are many thousands of features, and a few tens to hundreds of samples. Feature selection techniques provide three main benefits when constructing predictive models:
- improved model interpretability,
- shorter training times,
- enhanced generalisation by reducing overfitting.
Feature selection is also useful as part of the data analysis process, as it shows which features are important for prediction, and how these features are related.
Introduction
A feature selection algorithm can be seen as the combination of a search technique for proposing new feature subsets, along with an evaluation measure which scores the different feature subsets. The simplest algorithm is to test each possible subset of features finding the one which minimises the error rate. This is an exhaustive search of the space, and is computationally intractable for all but the smallest of feature sets. The choice of evaluation metric heavily influences the algorithm, and it is these evaluation metrics which distinguish between the three main categories of feature selection algorithms: wrappers, filters and embedded methods.[1]
Wrapper methods use a predictive model to score feature subsets. Each new subset is used to train a model, which is tested on a hold-out set. Counting the number of mistakes made on that hold-out set (the error rate of the model) gives the score for that subset. As wrapper methods train a new model for each subset, they are very computationally intensive, but usually provide the best performing feature set for that particular type of model.
Filter methods use a proxy measure instead of the error rate to score a feature subset. This measure is chosen to be fast to compute, whilst still capturing the usefulness of the feature set. Common measures include the mutual information,[1] the pointwise mutual information,[2] Pearson product-moment correlation coefficient, inter/intra class distance or the scores of significance tests for each class/feature combinations.[2][3] Filters are usually less computationally intensive than wrappers, but they produce a feature set which is not tuned to a specific type of predictive model. This lack of tuning means a feature set from a filter is more general than the set from a wrapper, usually giving lower prediction performance than a wrapper. However the feature set doesn't contain the assumptions of a prediction model, and so is more useful for exposing the relationships between the features. Many filters provide a feature ranking rather than an explicit best feature subset, and the cut off point in the ranking is chosen via cross-validation. Filter methods have also been used as a preprocessing step for wrapper methods, allowing a wrapper to be used on larger problems.
Embedded methods are a catch-all group of techniques which perform feature selection as part of the model construction process. The exemplar of this approach is the LASSO method for constructing a linear model, which penalises the regression coefficients, shrinking many of them to zero. Any features which have non-zero regression coefficients are 'selected' by the LASSO algorithm. Improvements to the LASSO include Bolasso which bootstraps samples,[4] and FeaLect which scores all the features based on combinatorial analysis of regression coefficients.[5] One other popular approach is the Recursive Feature Elimination algorithm, commonly used with Support Vector Machines to repeatedly construct a model and remove features with low weights. These approaches tend to be between filters and wrappers in terms of computational complexity.
In statistics, the most popular form of feature selection is stepwise regression, which is a wrapper technique. It is a greedy algorithm that adds the best feature (or deletes the worst feature) at each round. The main control issue is deciding when to stop the algorithm. In machine learning, this is typically done by cross-validation. In statistics, some criteria are optimized. This leads to the inherent problem of nesting. More robust methods have been explored, such as branch and bound and piecewise linear network.
Subset selection
Subset selection evaluates a subset of features as a group for suitability. Subset selection algorithms can be broken up into Wrappers, Filters and Embedded. Wrappers use a search algorithm to search through the space of possible features and evaluate each subset by running a model on the subset. Wrappers can be computationally expensive and have a risk of over fitting to the model. Filters are similar to Wrappers in the search approach, but instead of evaluating against a model, a simpler filter is evaluated. Embedded techniques are embedded in and specific to a model.
Many popular search approaches use greedy hill climbing, which iteratively evaluates a candidate subset of features, then modifies the subset and evaluates if the new subset is an improvement over the old. Evaluation of the subsets requires a scoring metric that grades a subset of features. Exhaustive search is generally impractical, so at some implementor (or operator) defined stopping point, the subset of features with the highest score discovered up to that point is selected as the satisfactory feature subset. The stopping criterion varies by algorithm; possible criteria include: a subset score exceeds a threshold, a program's maximum allowed run time has been surpassed, etc.
Alternative search-based techniques are based on targeted projection pursuit which finds low-dimensional projections of the data that score highly: the features that have the largest projections in the lower-dimensional space are then selected.
Search approaches include:
- Exhaustive
- Best first
- Simulated annealing
- Genetic algorithm
- Greedy forward selection
- Greedy backward elimination
- Targeted projection pursuit
- Scatter Search[6]
- Variable Neighborhood Search[7]
Two popular filter metrics for classification problems are correlation and mutual information, although neither are true metrics or 'distance measures' in the mathematical sense, since they fail to obey the triangle inequality and thus do not compute any actual 'distance' – they should rather be regarded as 'scores'. These scores are computed between a candidate feature (or set of features) and the desired output category. There are, however, true metrics that are a simple function of the mutual information;[8] see here.
Other available filter metrics include:
- Class separability
- Error probability
- Inter-class distance
- Probabilistic distance
- Entropy
- Consistency-based feature selection
- Correlation-based feature selection
Optimality criteria
The choice of optimality criteria is difficult as there are multiple objectives in a feature selection task. Many common ones incorporate a measure of accuracy, penalised by the number of features selected (e.g. the Bayesian information criterion). The oldest are Mallows's Cp statistic and Akaike information criterion (AIC). These add variables if the t-statistic is bigger than 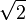 .
.
Other criteria are Bayesian information criterion (BIC) which uses 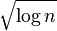 , minimum description length (MDL) which asymptotically uses , Bonnferroni / RIC which use
, minimum description length (MDL) which asymptotically uses , Bonnferroni / RIC which use  , maximum dependency feature selection, and a variety of new criteria that are motivated by false discovery rate (FDR) which use something close to
, maximum dependency feature selection, and a variety of new criteria that are motivated by false discovery rate (FDR) which use something close to  .
.
Structure Learning
Filter feature selection is a specific case of a more general paradigm called Structure Learning. Feature selection finds the relevant feature set for a specific target variable whereas structure learning finds the relationships between all the variables, usually by expressing these relationships as a graph. The most common structure learning algorithms assume the data is generated by a Bayesian Network, and so the structure is a directed graphical model. The optimal solution to the filter feature selection problem is the Markov blanket of the target node, and in a Bayesian Network, there is a unique Markov Blanket for each node.[9]
Minimum-redundancy-maximum-relevance (mRMR) feature selection
Peng et al.[10] proposed a feature selection method that can use either mutual information, correlation, or distance/similarity scores to select features. The aim is to penalise a feature's relevancy by its redundancy in the presence of the other selected features. The relevance of a feature set S for the class c is defined by the average value of all mutual information values between the individual feature fi and the class c as follows:
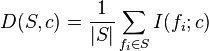 .
.
The redundancy of all features in the set S is the average value of all mutual information values between the feature fi and the feature fj:

The mRMR criterion is a combination of two measures given above and is defined as follows:
![\mathrm{mRMR}= \max_{S}
\left[\frac{1}{|S|}\sum_{f_{i}\in S}I(f_{i};c) -
\frac{1}{|S|^{2}}\sum_{f_{i},f_{j}\in S}I(f_{i};f_{j})\right].](../I/m/40afec7e6c1e3406187b4585fa0381ae.png)
Suppose that there are n full-set features. Let xi be the set membership indicator function for feature fi, so that xi=1 indicates presence and xi=0 indicates absence of the feature fi in the globally optimal feature set. Let ci=I(fi;c) and aij=I(fi;fj). The above may then be written as an optimization problem:
![\mathrm{mRMR}= \max_{x\in \{0,1\}^{n}}
\left[\frac{\sum^{n}_{i=1}c_{i}x_{i}}{\sum^{n}_{i=1}x_{i}} -
\frac{\sum^{n}_{i,j=1}a_{ij}x_{i}x_{j}}
{(\sum^{n}_{i=1}x_{i})^{2}}\right].](../I/m/fbef87779d6c6fdf9da9e223eb181419.png)
The mRMR algorithm is an approximation of the theoretically optimal maximum-dependency feature selection algorithm that maximizes the mutual information between the joint distribution of the selected features and the classification variable. As mRMR approximates the combinatorial estimation problem with a series of much smaller problems, each of which only involves two variables, it thus uses pairwise joint probabilities which are more robust. In certain situations the algorithm may underestimate the usefulness of features as it has no way to measure interactions between features which can increase relevancy. This can lead to poor performance[11] when the features are individually useless, but are useful when combined (a pathological case is found when the class is a parity function of the features). Overall the algorithm is more efficient (in terms of the amount of data required) than the theoretically optimal max-dependency selection, yet produces a feature set with little pairwise redundancy.
mRMR is an instance of a large class of filter methods which trade off between relevancy and redundancy in different ways.[11][12]
Global optimization formulations
mRMR is a typical example of an incremental greedy strategy for feature selection: once a feature has been selected, it cannot be deselected at a later stage. While mRMR could be optimized using floating search to reduce some features, it might also be reformulated as a global quadratic programing optimization problem as follows:[13]
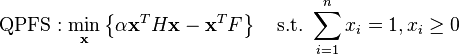
where ![F_{n\times1}=[I(f_1;c),\ldots, I(f_n;c)]^T](../I/m/f9392fbba212b104d67810b7e13cc599.png) is the vector of feature relevancy assuming there are
is the vector of feature relevancy assuming there are  features in total,
features in total, ![H_{n\times n}=[I(f_i;f_j)]_{i,j=1\ldots n}](../I/m/55dc34232f56b0e2e4f49510d29cddb3.png) is the matrix of feature pairwise redundancy, and
is the matrix of feature pairwise redundancy, and  represents relative feature weights. QPFS is solved via quadratic programming. It is recently shown that QFPS is biased towards features with smaller entropy,[14] due to its placement of the feature self redundancy term
represents relative feature weights. QPFS is solved via quadratic programming. It is recently shown that QFPS is biased towards features with smaller entropy,[14] due to its placement of the feature self redundancy term  on the diagonal of
on the diagonal of 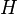 .
.
Another global formulation for the mutual information based feature selection problem is based on the conditional relevancy:[14]

where 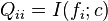 and
and 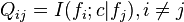 .
.
An advantage of  is that it can be solved simply via finding the dominant eigenvector of
is that it can be solved simply via finding the dominant eigenvector of 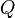 , thus is very scalable. also handles second-order feature interaction.
, thus is very scalable. also handles second-order feature interaction.
Correlation feature selection
The Correlation Feature Selection (CFS) measure evaluates subsets of features on the basis of the following hypothesis: "Good feature subsets contain features highly correlated with the classification, yet uncorrelated to each other".[15][16] The following equation gives the merit of a feature subset S consisting of k features:
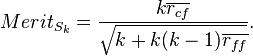
Here, 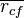 is the average value of all feature-classification correlations, and
is the average value of all feature-classification correlations, and  is the average value of all feature-feature correlations. The CFS criterion is defined as follows:
is the average value of all feature-feature correlations. The CFS criterion is defined as follows:
![\mathrm{CFS} = \max_{S_k}
\left[\frac{r_{c f_1}+r_{c f_2}+\cdots+r_{c f_k}}
{\sqrt{k+2(r_{f_1 f_2}+\cdots+r_{f_i f_j}+ \cdots
+ r_{f_k f_1 })}}\right].](../I/m/0b01c8f5a4f04c980aaf068f7d093f22.png)
The  and
and 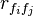 variables are referred to as correlations, but are not necessarily Pearson's correlation coefficient or Spearman's ρ. Dr. Mark Hall's dissertation uses neither of these, but uses three different measures of relatedness, minimum description length (MDL), symmetrical uncertainty, and relief.
variables are referred to as correlations, but are not necessarily Pearson's correlation coefficient or Spearman's ρ. Dr. Mark Hall's dissertation uses neither of these, but uses three different measures of relatedness, minimum description length (MDL), symmetrical uncertainty, and relief.
Let xi be the set membership indicator function for feature fi; then the above can be rewritten as an optimization problem:
![\mathrm{CFS} = \max_{x\in \{0,1\}^{n}}
\left[\frac{(\sum^{n}_{i=1}a_{i}x_{i})^{2}}
{\sum^{n}_{i=1}x_i + \sum_{i\neq j} 2b_{ij} x_i x_j }\right].](../I/m/470906caccc384e21c788dfd9b2def0d.png)
The combinatorial problems above are, in fact, mixed 0–1 linear programming problems that can be solved by using branch-and-bound algorithms.[17]
Regularized trees
The features from a decision tree or a tree ensemble are shown to be redundant. A recent method called regularized tree[18] can be used for feature subset selection. Regularized trees penalize using a variable similar to the variables selected at previous tree nodes for splitting the current node. Regularized trees only need build one tree model (or one tree ensemble model) and thus are computationally efficient.
Regularized trees naturally handle numerical and categorical features, interactions and nonlinearities. They are invariant to attribute scales (units) and insensitive to outliers, and thus, require little data preprocessing such as normalization. Regularized random forest (RRF) (RRF) is one type of regularized trees. The guided RRF is an enhanced RRF which is guided by the importance scores from an ordinary random forest.
Overview on metaheuristics methods
A metaheuristic is a general description of an algorithm dedicated to solve difficult (typically NP-hard problem) optimisation problems for which there is no classical solving methods. Generally, a metaheuristic is a stochastics algorithm tending to reach a global optima. There are many metaheuristics, from a simple local search to a complex global search algorithm.
Main principles
The feature selection methods are typically presented in three classes based on how they combine the selection algorithm and the model building
Filter Method
Filter type methods select variables regardless of the model. They are based only on general features like the correlation with the variable to predict. Filter methods suppress the least interesting variables. The others variables will be part of a the model classification, a regression used to classify or a data prediction. These methods are particularly effective in computation time and robust to overfitting.[19]
However, filter methods tend to select redundant variables because they does not consider the relationships between variables. Therefore, they are mainly used as a pre-process method.
Wrapper Method
Methods wrapper evaluate subsets of variables which allows, unlike filter approaches, to detect the possible interactions between variables.[20] The two main disadvantages of these methods are :
- The increasing overfitting risk when the number of observations is insufficient.
- The significant computation time when the number of variables is large.

Embedded Method
Recently, embedded methods have been proposed to reduce the classification of learning. They try to combine the advantages of both previous methods. The learning algorithm takes advantage of its own variable selection algorithm. So, it needs to know preliminary what a good selection is, which limits their exploitation.[21]

Application of feature selection metaheuristics
This is a survey of the application of feature selection metaheuristics lately used in the literature. This survey was realized by J. Hammon in her thesis.[19]
| Application | Algorithm | Approach | classifier | Evaluation Function | Ref |
|---|---|---|---|---|---|
| SNPs | Feature Selection Feature Similarity | Filter | r2 | Phuong 2005 [20] | |
| SNPs | Genetic Algorithm | Wrapper | Decision Tree | Classification accuracy (10-fold) | Shah 2004 [22] |
| SNPs | HillClimbing | Filter + Wrapper | Naive Bayesian | Predicted residual sum of squares | Long 2007 [23] |
| SNPs | Simuleating Annealing | Naive bayesian | Classification accuracy (5-fols) | Ustunkar 2011 [24] | |
| Segments parole | Ants colony | Wrapper | Artificial Neural Network | MSE | Al-ani 2005 [25] |
| Marketing | Simulated Annealing | Wrapper | Regression | AIC, r2 | Meiri 2006 [26] |
| Economy | Simulated Annealing, Genetic Algorithm | Wrapper | Regression | BIC | Kapetanios 2005 [27] |
| Spectral Mass | Genectic Algorithm | Wrapper | Multiple Regression Linear, Partial Least Square | root-mean-square error of prediction | Broadhurst 2007 [28] |
| Microarray | Tabu Search + PSO | Wrapper | Support Vector Machine, K Nearest Neighbor | Euclidian Distance | Chuang 2009 [29] |
| Microarray | PSO + Genetic Algorithm | Wrapper | Support Vector Machine | Classification accuracy (10-fold) | Alba 2007 [30] |
| Microarray | Genetic Algorithm + Iterated Local Search | Embedded | Support Vector Machine | Classification accuracy (10-fold) | Duval 2009 [21] |
| Microarray | Iterated Local Search | Wrapper | Regression | Posterior Probability | Hans 2007 [31] |
| Microarray | Genetic Algorithm | Wrapper | K Nearest Neighbor | Classification accuracy (Leave-one-out cross-validation) | Jirapech-Umpai 2005 [32] |
| Microarray | Hybrid Genetic Algorithm | Wrapper | K Nearest Neighbor | Classification accuracy (Leave-one-out cross-validation) | Oh 2004 [33] |
| Microarray | Genetic Algorithm | Wrapper | Support Vector Machine | Sensibility Specificity | Xuan 2011 [34] |
| Microarray | Genetic Algorithm | Wrapper | All paired, Support Vector Machine | Classification accuracy (Leave-one-out cross-validation) | Peng 2003 [35] |
| Microarray | Genetic Algorithm | Embedded | Support Vector Machine | Classification accuracy (10-fold) | Hernandez 2007 [36] |
| Microarray | Genetic Algorithm | Hybrid | Support Vector Machine | Classification accuracy (Leave-one-out cross-validation) | Huerta 2006 [37] |
| Microarray | Genetic Algorithm | Support Vector Machine | Classification accuracy (10-fold) | Muni 2006 [38] | |
| Microarray | Genetic Algorithm | Wrapper | Support Vector Machine | EH-DIALL, CLUMP | Jourdan 2004 [39] |
Feature selection embedded in learning algorithms
Some learning algorithms perform feature selection as part of their overall operation. These include:
-
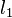 -regularisation techniques, such as sparse regression, LASSO, and -SVM
-regularisation techniques, such as sparse regression, LASSO, and -SVM - Regularized trees e.g. regularized random forest implemented in the RRF package
- Decision tree
- Memetic algorithm
- Random multinomial logit (RMNL)
- Auto-encoding networks with a bottleneck-layer
See also
References
- ↑ 1.0 1.1 Guyon, Isabelle; Elisseeff, André (2003). "An Introduction to Variable and Feature Selection". JMLR 3.
- ↑ 2.0 2.1 Yang, Yiming; Pedersen, Jan O. (1997). A comparative study on feature selection in text categorization. ICML.
- ↑ Forman, George (2003). "An extensive empirical study of feature selection metrics for text classification". Journal of Machine Learning Research 3: 1289–1305.
- ↑ Bach, Francis R (2008). "Bolasso: model consistent lasso estimation through the bootstrap". Proceedings of the 25th international conference on Machine learning: 33–40. doi:10.1145/1390156.1390161.
- ↑ Zare, Habil (2013). "Scoring relevancy of features based on combinatorial analysis of Lasso with application to lymphoma diagnosis". BMC genomics 14: S14. doi:10.1186/1471-2164-14-S1-S14.
- ↑ F.C. Garcia-Lopez, M. Garcia-Torres, B. Melian, J.A. Moreno-Perez, J.M. Moreno-Vega. Solving feature subset selection problem by a Parallel Scatter Search, European Journal of Operational Research, vol. 169, no. 2, pp. 477–489, 2006.
- ↑ F.C. Garcia-Lopez, M. Garcia-Torres, B. Melian, J.A. Moreno-Perez, J.M. Moreno-Vega. Solving Feature Subset Selection Problem by a Hybrid Metaheuristic. In First International Workshop on Hybrid Metaheuristics, pp. 59–68, 2004.
- ↑ Alexander Kraskov, Harald Stögbauer, Ralph G. Andrzejak, and Peter Grassberger, "Hierarchical Clustering Based on Mutual Information", (2003) ArXiv q-bio/0311039
- ↑ Aliferis, Constantin (2010). "Local causal and markov blanket induction for causal discovery and feature selection for classification part I: Algorithms and empirical evaluation". Journal of Machine Learning Research 11: 171–234.
- ↑ Peng, H. C.; Long, F.; Ding, C. (2005). "Feature selection based on mutual information: criteria of max-dependency, max-relevance, and min-redundancy". IEEE Transactions on Pattern Analysis and Machine Intelligence 27 (8): 1226–1238. doi:10.1109/TPAMI.2005.159. PMID 16119262. Program
- ↑ 11.0 11.1 Brown, G., Pocock, A., Zhao, M.-J., Lujan, M. (2012). "Conditional Likelihood Maximisation: A Unifying Framework for Information Theoretic Feature Selection", In the Journal of Machine Learning Research (JMLR).
- ↑ Nguyen, H., Franke, K., Petrovic, S. (2010). "Towards a Generic Feature-Selection Measure for Intrusion Detection", In Proc. International Conference on Pattern Recognition (ICPR), Istanbul, Turkey.
- ↑ I. Rodriguez-Lujan, R. Huerta, C. Elkan, and C. S. Cruz. Quadratic programming feature selection. J. Mach. Learn. Res., 11:1491–1516, 2010.
- ↑ 14.0 14.1 Nguyen X. Vinh, Jeffrey Chan, Simone Romano and James Bailey, "Effective Global Approaches for Mutual Information based Feature Selection". Proceeedings of the 20th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD'14), August 24–27, New York City, 2014. ""
- ↑ M. Hall 1999, Correlation-based Feature Selection for Machine Learning
- ↑ Senliol, Baris, et al. "Fast Correlation Based Filter (FCBF) with a different search strategy." Computer and Information Sciences, 2008. ISCIS'08. 23rd International Symposium on. IEEE, 2008.
- ↑ Hai Nguyen, Katrin Franke, and Slobodan Petrovic, Optimizing a class of feature selection measures, Proceedings of the NIPS 2009 Workshop on Discrete Optimization in Machine Learning: Submodularity, Sparsity & Polyhedra (DISCML), Vancouver, Canada, December 2009.
- ↑ H. Deng, G. Runger, "Feature Selection via Regularized Trees", Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), IEEE, 2012
- ↑ 19.0 19.1 J. Hammon. Optimisation combinatoire pour la sélection de variables en régression en grande dimension : Application en génétique animale. November 2013
- ↑ 20.0 20.1 T. M. Phuong, Z. Lin et R. B. Altman. Choosing SNPs using feature selection. Proceedings / IEEE Computational Systems Bioinformatics Conference, CSB. IEEE Computational Systems Bioinformatics Conference, pages 301-309, 2005. PMID 16447987.
- ↑ 21.0 21.1 B. Duval, J.-K. Hao et J. C. Hernandez Hernandez. A memetic algorithm for gene selection and molecular classification of an cancer. In Proceedings of the 11th Annual conference on Genetic and evolutionary computation, GECCO '09, pages 201-208, New York, NY, USA, 2009. ACM.
- ↑ S. C. Shah et A. Kusiak. Data mining and genetic algorithm based gene/SNP selection. Artificial intelligence in medicine, vol. 31, no. 3, pages 183-196, July 2004. PMID 15302085.
- ↑ N. Long, D. Gianola, G. J.M Rosa et K. A Weigel. Dimension redu ction and variable selection for genomic selection : application to predicting milk yield in Holsteins. Journal of Animal Breeding and Genetics, vol. 128, no. 4, pages 247-257, August 2011.
- ↑ G. Ustunkar, S. Ozogur-Akyuz, G. W. Weber, C. M. Friedrich et Yesim Aydin Son. Selection of representative SNP sets for genome-wide association studies : a metaheuristic approach. Optimization Letters, November 2011.
- ↑ A. Al-ani. Ant Colony Optimization for Feature Subset Selection. In Proceedings of World Academy of Science, Engineering and Technology, pages 35-38, 2005.
- ↑ R. Meiri et J. Zahavi. Using simulated annealing to optimize the feature selection problem in marketing applications. European Journal of Operational Research, vol. 171, no. 3, pages 842-858, Juin 2006
- ↑ G. Kapetanios. Variable Selection using Non-Standard Optimisation of Information Criteria. Working Paper 533, Queen Mary, University of London, School of Economics and Finance, 2005.
- ↑ D. Broadhurst, R. Goodacre, A. Jones, J. J. Rowland et D. B. Kell. Genetic algorithms as a method for variable selection in multiple linear regression and partial least squares regression, with applications to pyrolysis mass spectrometry. Analytica Chimica Acta, vol. 348, no. 1-3, pages 71-86, August 1997.
- ↑ L.-Y. Chuang, C.-H. Yang et C.-H. Yang. Tabu search and binary particle swarm optimization for feature selection using microarray data. Journal of computational biology : a journal of computational molecular cell biology, vol. 16, no. 12, pages 1689-1703, Décembre 2009. PMID 20047491
- ↑ E. Alba, J. Garia-Nieto, L. Jourdan et E.-G. Talbi. Gene Selection in Cancer Classification using PSO-SVM and GA-SVM Hybrid Algorithms. Congress on Evolutionary Computation, Singapor : Singapore (2007), 2007
- ↑ C. Hans, A. Dobra et M. West. Shotgun stochastic search for 'large p' regression. Journal of the American Statistical Association, 2007.
- ↑ T. Jirapech-Umpai et S. Aitken. Feature selection and classification for microarray data analysis : Evolutionary methods for identifying predictive genes. BMC bioinformatics, vol. 6, no. 1, page 148, 2005.
- ↑ I. S. Oh, J. S. Lee et B. R. Moon. Hybrid genetic algorithms for feature selection. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 26, no. 11, pages 1424-1437, November 2004.
- ↑ P. Xuan, M. Z. Guo, J.Wang, C. Y.Wang, X. Y. Liu et Y. Liu. Genetic algorithm-based efficient feature selection for classification of pre-miRNAs. Genetics and Molecular Research : GMR, vol. 10, no. 2, pages 588-603, 2011. PMID 21491369.
- ↑ S. Peng. Molecular classification of cancer types from microarray data using the combination of genetic algorithms and support vector machines. FEBS Letters, vol. 555, no. 2, pages 358-362, December 2003.
- ↑ J. C. H. Hernandez, B. Duval et J.-K. Hao. A genetic embedded approach for gene selection and classification of microarray data. In Proceedings of the 5th European conference on Evolutionary computation, machine learning and data mining in bioinformatics, EvoBIO'07, pages 90-101, Berlin, Heidelberg, 2007. SpringerVerlag.
- ↑ E. B. Huerta, B. Duval et J.-K. Hao. A hybrid GA/SVM approach for gene selection and classification of microarray data. evoworkshops 2006, LNCS, vol. 3907, pages 34-44, 2006.
- ↑ D. P. Muni, N. R. Pal et J. Das. Genetic programming for simultaneous feature selection and classifier design. IEEE Transactions on Systems, Man, and Cybernetics, Part B : Cybernetics, vol. 36, no. 1, pages 106-117, February 2006.
- ↑ L. Jourdan, C. Dhaenens et E.-G. Talbi. Linkage disequilibrium study with a parallel adaptive GA. International Journal of Foundations of Computer Science, 2004.
Further reading
- Feature Selection for Classification: A Review (Survey,2014)
- Feature Selection for Clustering: A Review (Survey,2013)
- Tutorial Outlining Feature Selection Algorithms, Arizona State University
- JMLR Special Issue on Variable and Feature Selection
- Feature Selection for Knowledge Discovery and Data Mining (Book)
- An Introduction to Variable and Feature Selection (Survey)
- Toward integrating feature selection algorithms for classification and clustering (Survey)
- Efficient Feature Subset Selection and Subset Size Optimization (Survey, 2010)
- Searching for Interacting Features
- Feature Subset Selection Bias for Classification Learning
- Y. Sun, S. Todorovic, S. Goodison, Local Learning Based Feature Selection for High-dimensional Data Analysis, IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 32, no. 9, pp. 1610–1626, 2010.
External links
- A comprehensive package for Mutual Information based feature selection in Matlab
- Feature Selection Package, Arizona State University (Matlab Code)
- NIPS challenge 2003 (see also NIPS)
- Naive Bayes implementation with feature selection in Visual Basic (includes executable and source code)
- Minimum-redundancy-maximum-relevance (mRMR) feature selection program
- FEAST (Open source Feature Selection algorithms in C and MATLAB)