Factor analysis
Factor analysis is a statistical method used to describe variability among observed, correlated variables in terms of a potentially lower number of unobserved variables called factors. For example, it is possible that variations in four observed variables mainly reflect the variations in two unobserved variables. Factor analysis searches for such joint variations in response to unobserved latent variables. The observed variables are modelled as linear combinations of the potential factors, plus "error" terms. The information gained about the interdependencies between observed variables can be used later to reduce the set of variables in a dataset. Computationally this technique is equivalent to low-rank approximation of the matrix of observed variables. Factor analysis originated in psychometrics and is used in behavioral sciences, social sciences, marketing, product management, operations research, and other applied sciences that deal with large quantities of data.
Factor analysis is related to principal component analysis (PCA), but the two are not identical. Latent variable models, including factor analysis, use regression modelling techniques to test hypotheses producing error terms, while PCA is a descriptive statistical technique.[1] There has been significant controversy in the field over the equivalence or otherwise of the two techniques (see exploratory factor analysis versus principal components analysis).
Statistical model
Definition
Suppose we have a set of 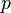 observable random variables,
observable random variables, 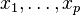 with means
with means 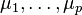 .
.
Suppose for some unknown constants 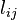 and
and 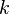 unobserved random variables
unobserved random variables 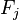 , where
, where 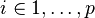 and
and 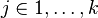 , where
, where 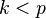 , we have
, we have
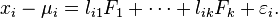
Here, the 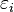 are independently distributed error terms with zero mean and finite variance, which may not be the same for all
are independently distributed error terms with zero mean and finite variance, which may not be the same for all 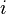 . Let
. Let 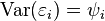 , so that we have
, so that we have
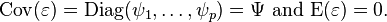
In matrix terms, we have
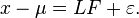
If we have  observations, then we will have the dimensions
observations, then we will have the dimensions 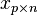 ,
, 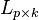 , and
, and 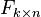 . Each column of
. Each column of 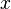 and
and 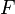 denote values for one particular observation, and matrix
denote values for one particular observation, and matrix 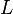 does not vary across observations.
does not vary across observations.
Also we will impose the following assumptions on :
- and
 are independent.
are independent. -
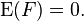
-
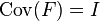 (to make sure that the factors are uncorrelated).
(to make sure that the factors are uncorrelated).
Any solution of the above set of equations following the constraints for is defined as the factors, and as the loading matrix.
Suppose 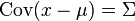 . Then note that from the conditions just imposed on , we have
. Then note that from the conditions just imposed on , we have
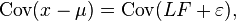
or
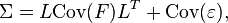
or
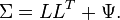
Note that for any orthogonal matrix 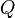 , if we set
, if we set 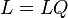 and
and 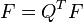 , the criteria for being factors and factor loadings still hold. Hence a set of factors and factor loadings is identical only up to orthogonal transformation.
, the criteria for being factors and factor loadings still hold. Hence a set of factors and factor loadings is identical only up to orthogonal transformation.
Example
The following example is just used hypothetically, and should not be taken as being realistic. Suppose a psychologist proposes a theory that there are two kinds of intelligence, "verbal intelligence" and "mathematical intelligence", neither of which is directly observed. Evidence for the theory is sought in the examination scores from each of 10 different academic fields of 1000 students. If each student is chosen randomly from a large population, then each student's 10 scores are random variables. The psychologist's theory may say that for each of the 10 academic fields, the score averaged over the group of all students who share some common pair of values for verbal and mathematical "intelligences" is some constant times their level of verbal intelligence plus another constant times their level of mathematical intelligence, i.e., it is a combination of those two "factors". The numbers for a particular subject, by which the two kinds of intelligence are multiplied to obtain the expected score, are posited by the theory to be the same for all intelligence level pairs, and are called "factor loadings" for this subject. For example, the theory may hold that the average student's aptitude in the field of taxonomy is
- {10 × the student's verbal intelligence} + {6 × the student's mathematical intelligence}.
The numbers 10 and 6 are the factor loadings associated with taxonomy. Other academic subjects may have different factor loadings.
Two students having identical degrees of verbal intelligence and identical degrees of mathematical intelligence may have different aptitudes in taxonomy because individual aptitudes differ from average aptitudes. That difference is called the "error" — a statistical term that means the amount by which an individual differs from what is average for his or her levels of intelligence (see errors and residuals in statistics).
The observable data that go into factor analysis would be 10 scores of each of the 1000 students, a total of 10,000 numbers. The factor loadings and levels of the two kinds of intelligence of each student must be inferred from the data.
Mathematical model of the same example
In the following, matrices will be indicated by indexed variables. "Subject" indices will be indicated using letters a,b and c, with values running from 1 to 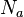 which is equal to 10 in the above example. "Factor" indices will be indicated using letters p, q and r, with values running from 1 to
which is equal to 10 in the above example. "Factor" indices will be indicated using letters p, q and r, with values running from 1 to 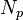 which is equal to 2 in the above example. "Instance" or "sample" indices will be indicated using letters i,j and k, with values running from 1 to
which is equal to 2 in the above example. "Instance" or "sample" indices will be indicated using letters i,j and k, with values running from 1 to 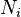 . In the example above, if a sample of
. In the example above, if a sample of 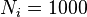 students responded to the
students responded to the 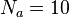 questions, the ith student's score for the ath question are given by
questions, the ith student's score for the ath question are given by 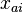 . The purpose of factor analysis is to characterize the correlations between the variables
. The purpose of factor analysis is to characterize the correlations between the variables 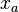 of which the are a particular instance, or set of observations. In order that the variables be on equal footing, they are standardized:
of which the are a particular instance, or set of observations. In order that the variables be on equal footing, they are standardized:
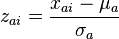
where the sample mean is:
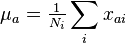
and the sample variance is given by:
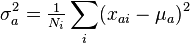
The factor analysis model for this particular sample is then:
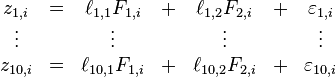
or, more succinctly:
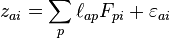
where
-
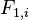 is the ith student's "verbal intelligence",
is the ith student's "verbal intelligence", -
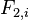 is the ith student's "mathematical intelligence",
is the ith student's "mathematical intelligence", -
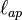 are the factor loadings for the ath subject, for p = 1, 2.
are the factor loadings for the ath subject, for p = 1, 2.
In matrix notation, we have
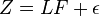
Observe that by doubling the scale on which "verbal intelligence"—the first component in each column of F—is measured, and simultaneously halving the factor loadings for verbal intelligence makes no difference to the model. Thus, no generality is lost by assuming that the standard deviation of verbal intelligence is 1. Likewise for mathematical intelligence. Moreover, for similar reasons, no generality is lost by assuming the two factors are uncorrelated with each other. In other words:
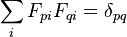
where 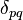 is the Kronecker delta (0 when
is the Kronecker delta (0 when 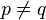 and 1 when
and 1 when 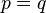 ).The errors are assumed to be independent of the factors:
).The errors are assumed to be independent of the factors:
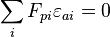
Note that, since any rotation of a solution is also a solution, this makes interpreting the factors difficult. See disadvantages below. In this particular example, if we do not know beforehand that the two types of intelligence are uncorrelated, then we cannot interpret the two factors as the two different types of intelligence. Even if they are uncorrelated, we cannot tell which factor corresponds to verbal intelligence and which corresponds to mathematical intelligence without an outside argument.
The values of the loadings L, the averages μ, and the variances of the "errors" ε must be estimated given the observed data X and F (the assumption about the levels of the factors is fixed for a given F). The "fundamental theorem" may be derived from the above conditions:
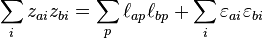
The term on the left is just the correlation matrix of the observed data, and its diagonal elements will be 1's. The last term on the right will be a diagonal matrix with terms less than unity. The first term on the right is the "reduced correlation matrix" and will be equal to the correlation matrix except for its diagonal values which will be less than unity. These diagonal elements of the reduced correlation matrix are called "communalities":

The sample data 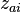 will not, of course, exactly obey the fundamental equation given above due to sampling errors, inadequacy of the model, etc. The goal of any analysis of the above model is to find the factors
will not, of course, exactly obey the fundamental equation given above due to sampling errors, inadequacy of the model, etc. The goal of any analysis of the above model is to find the factors 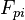 and loadings which, in some sense, give a "best fit" to the data. In factor analysis, the best fit is defined as the minimum of the mean square error in the off-diagonal residuals of the correlation matrix:[2]
and loadings which, in some sense, give a "best fit" to the data. In factor analysis, the best fit is defined as the minimum of the mean square error in the off-diagonal residuals of the correlation matrix:[2]
![\varepsilon^2 = \sum_{ab,a\ne b} \left[\sum_i z_{ai}z_{bi}-\sum_p \ell_{ap}\ell_{bp}\right]^2](../I/m/013645bbc36fbf50fe7d56879eef37c6.png)
This is equivalent to minimizing the off-diagonal components of the error covariance which, in the model equations have expected values of zero. This is to be contrasted with principal component analysis which seeks to minimize the mean square error of all residuals.[2] Before the advent of high speed computers, considerable effort was devoted to finding approximate solutions to the problem, particularly in estimating the communalities by other means, which then simplifies the problem considerably by yielding a known reduced correlation matrix. This was then used to estimate the factors and the loadings. With the advent of high-speed computers, the minimization problem can be solved quickly and directly, and the communalities are calculated in the process, rather than being needed beforehand. The MinRes algorithm is particularly suited to this problem, but is hardly the only means of finding an exact solution.
Geometric interpretation

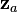 , which is projected onto a plane defined by two orthonormal vectors
, which is projected onto a plane defined by two orthonormal vectors 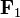 and
and 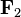 . The projection vector is
. The projection vector is 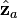 and the error
and the error 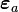 is perpendicular to the plane, so that
is perpendicular to the plane, so that 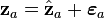 . The projection vector may be represented in terms of the factor vectors as
. The projection vector may be represented in terms of the factor vectors as 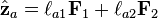 . The square of the length of the projection vector is the communality:
. The square of the length of the projection vector is the communality: 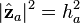 . If another data vector
. If another data vector 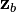 were plotted, the cosine of the angle between and would be
were plotted, the cosine of the angle between and would be 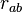 : the (a,b) entry in the correlation matrix. (Adapted from Harman Fig. 4.3)[2]
: the (a,b) entry in the correlation matrix. (Adapted from Harman Fig. 4.3)[2]The parameters and variables of factor analysis can be given a geometrical interpretation. The data (), the factors () and the errors (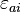 ) can be viewed as vectors in an -dimensional Euclidean space (sample space), represented as ,
) can be viewed as vectors in an -dimensional Euclidean space (sample space), represented as , 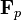 and respectively. Since the data is standardized, the data vectors are of unit length (
and respectively. Since the data is standardized, the data vectors are of unit length (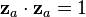 ). The factor vectors define an -dimensional linear subspace (i.e. a hyperplane) in this space, upon which the data vectors are projected orthogonally. This follows from the model equation
). The factor vectors define an -dimensional linear subspace (i.e. a hyperplane) in this space, upon which the data vectors are projected orthogonally. This follows from the model equation
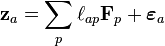
and the independence of the factors and the errors: 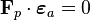 . In the above example, the hyperplane is just a 2-dimensional plane defined by the two factor vectors. The projection of the data vectors onto the hyperplane is given by
. In the above example, the hyperplane is just a 2-dimensional plane defined by the two factor vectors. The projection of the data vectors onto the hyperplane is given by
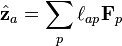
and the errors are vectors from that projected point to the data point and are perpendicular to the hyperplane. The goal of factor analysis is to find a hyperplane which is a "best fit" to the data in some sense, so it doesn't matter how the factor vectors which define this hyperplane are chosen, as long as they are independent and lie in the hyperplane. We are free to specify them as both orthogonal and normal (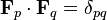 ) with no loss of generality. After a suitable set of factors are found, they may also be arbitrarily rotated within the hyperplane, so that any rotation of the factor vectors will define the same hyperplane, and also be a solution. As a result, in the above example, in which the fitting hyperplane is two dimensional, if we do not know beforehand that the two types of intelligence are uncorrelated, then we cannot interpret the two factors as the two different types of intelligence. Even if they are uncorrelated, we cannot tell which factor corresponds to verbal intelligence and which corresponds to mathematical intelligence, or whether the factors are linear combinations of both, without an outside argument.
) with no loss of generality. After a suitable set of factors are found, they may also be arbitrarily rotated within the hyperplane, so that any rotation of the factor vectors will define the same hyperplane, and also be a solution. As a result, in the above example, in which the fitting hyperplane is two dimensional, if we do not know beforehand that the two types of intelligence are uncorrelated, then we cannot interpret the two factors as the two different types of intelligence. Even if they are uncorrelated, we cannot tell which factor corresponds to verbal intelligence and which corresponds to mathematical intelligence, or whether the factors are linear combinations of both, without an outside argument.
The data vectors have unit length. The correlation matrix for the data is given by 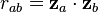 . The correlation matrix can be geometrically interpreted as the cosine of the angle between the two data vectors and . The diagonal elements will clearly be 1's and the off diagonal elements will have absolute values less than or equal to unity. The "reduced correlation matrix" is defined as
. The correlation matrix can be geometrically interpreted as the cosine of the angle between the two data vectors and . The diagonal elements will clearly be 1's and the off diagonal elements will have absolute values less than or equal to unity. The "reduced correlation matrix" is defined as
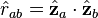 .
.
The goal of factor analysis is to choose the fitting hyperplane such that the reduced correlation matrix reproduces the correlation matrix as nearly as possible, except for the diagonal elements of the correlation matrix which are known to have unit value. In other words, the goal is to reproduce as accurately as possible the cross-correlations in the data. Specifically, for the fitting hyperplane, the mean square error in the off-diagonal components
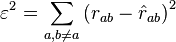
is to be minimized, and this is accomplished by minimizing it with respect to a set of orthonormal factor vectors. It can be seen that
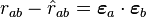
The term on the right is just the covariance of the errors. In the model, the error covariance is stated to be a diagonal matrix and so the above minimization problem will in fact yield a "best fit" to the model: It will yield a sample estimate of the error covariance which has its off-diagonal components minimized in the mean square sense. It can be seen that since the 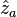 are orthogonal projections of the data vectors, their length will be less than or equal to the length of the projected data vector, which is unity. The square of these lengths are just the diagonal elements of the reduced correlation matrix. These diagonal elements of the reduced correlation matrix are known as "communalities":
are orthogonal projections of the data vectors, their length will be less than or equal to the length of the projected data vector, which is unity. The square of these lengths are just the diagonal elements of the reduced correlation matrix. These diagonal elements of the reduced correlation matrix are known as "communalities":
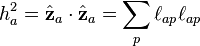
Large values of the communalities will indicate that the fitting hyperplane is rather accurately reproducing the correlation matrix. It should be noted that the mean values of the factors must also be constrained to be zero, from which it follows that the mean values of the errors will also be zero.
Practical implementation
Type of factor analysis
Exploratory factor analysis (EFA) is used to identify complex interrelationships among items and group items that are part of unified concepts.[3] The researcher makes no "a priori" assumptions about relationships among factors.[3]
Confirmatory factor analysis (CFA) is a more complex approach that tests the hypothesis that the items are associated with specific factors.[3] CFA uses structural equation modeling to test a measurement model whereby loading on the factors allows for evaluation of relationships between observed variables and unobserved variables.[3] Structural equation modeling approaches can accommodate measurement error, and are less restrictive than least-squares estimation.[3] Hypothesized models are tested against actual data, and the analysis would demonstrate loadings of observed variables on the latent variables (factors), as well as the correlation between the latent variables.[3]
Types of factoring
Principal component analysis (PCA): PCA is a widely used method for factor extraction, which is the first phase of EFA.[3] Factor weights are computed in order to extract the maximum possible variance, with successive factoring continuing until there is no further meaningful variance left.[3] The factor model must then be rotated for analysis.[3]
Canonical factor analysis, also called Rao's canonical factoring, is a different method of computing the same model as PCA, which uses the principal axis method. Canonical factor analysis seeks factors which have the highest canonical correlation with the observed variables. Canonical factor analysis is unaffected by arbitrary rescaling of the data.
Common factor analysis, also called principal factor analysis (PFA) or principal axis factoring (PAF), seeks the least number of factors which can account for the common variance (correlation) of a set of variables.
Image factoring: based on the correlation matrix of predicted variables rather than actual variables, where each variable is predicted from the others using multiple regression.
Alpha factoring: based on maximizing the reliability of factors, assuming variables are randomly sampled from a universe of variables. All other methods assume cases to be sampled and variables fixed.
Factor regression model: a combinatorial model of factor model and regression model; or alternatively, it can be viewed as the hybrid factor model,[4] whose factors are partially known.
Terminology
Factor loadings: The factor loadings, also called component loadings in PCA (not sure in Factor Analysis), are the correlation coefficients between the cases (rows) and factors (columns). Analogous to Pearson's r, the squared factor loading is the percent of variance in that indicator variable explained by the factor. To get the percent of variance in all the variables accounted for by each factor, add the sum of the squared factor loadings for that factor (column) and divide by the number of variables. (Note the number of variables equals the sum of their variances as the variance of a standardized variable is 1.) This is the same as dividing the factor's eigenvalue by the number of variables.
Interpreting factor loadings: By one rule of thumb in confirmatory factor analysis, loadings should be .7 or higher to confirm that independent variables identified a priori are represented by a particular factor, on the rationale that the .7 level corresponds to about half of the variance in the indicator being explained by the factor. However, the .7 standard is a high one and real-life data may well not meet this criterion, which is why some researchers, particularly for exploratory purposes, will use a lower level such as .4 for the central factor and .25 for other factors. In any event, factor loadings must be interpreted in the light of theory, not by arbitrary cutoff levels.
In oblique rotation, one gets both a pattern matrix and a structure matrix. The structure matrix is simply the factor loading matrix as in orthogonal rotation, representing the variance in a measured variable explained by a factor on both a unique and common contributions basis. The pattern matrix, in contrast, contains coefficients which just represent unique contributions. The more factors, the lower the pattern coefficients as a rule since there will be more common contributions to variance explained. For oblique rotation, the researcher looks at both the structure and pattern coefficients when attributing a label to a factor. Principles of oblique rotation can be derived from both cross entropy and its dual entropy.[5]
Communality: The sum of the squared factor loadings for all factors for a given variable (row) is the variance in that variable accounted for by all the factors, and this is called the communality. The communality measures the percent of variance in a given variable explained by all the factors jointly and may be interpreted as the reliability of the indicator.
Spurious solutions: If the communality exceeds 1.0, there is a spurious solution, which may reflect too small a sample or the researcher has too many or too few factors.
Uniqueness of a variable: That is, uniqueness is the variability of a variable minus its communality.
Eigenvalues:/Characteristic roots: The eigenvalue for a given factor measures the variance in all the variables which is accounted for by that factor. The ratio of eigenvalues is the ratio of explanatory importance of the factors with respect to the variables. If a factor has a low eigenvalue, then it is contributing little to the explanation of variances in the variables and may be ignored as redundant with more important factors. Eigenvalues measure the amount of variation in the total sample accounted for by each factor.
Extraction sums of squared loadings: Initial eigenvalues and eigenvalues after extraction (listed by SPSS as "Extraction Sums of Squared Loadings") are the same for PCA extraction, but for other extraction methods, eigenvalues after extraction will be lower than their initial counterparts. SPSS also prints "Rotation Sums of Squared Loadings" and even for PCA, these eigenvalues will differ from initial and extraction eigenvalues, though their total will be the same.
Factor scores (also called component scores in PCA): are the scores of each case (row) on each factor (column). To compute the factor score for a given case for a given factor, one takes the case's standardized score on each variable, multiplies by the corresponding loadings of the variable for the given factor, and sums these products. Computing factor scores allows one to look for factor outliers. Also, factor scores may be used as variables in subsequent modeling. (Explained from PCA not from Factor Analysis perspective).
Criteria for determining the number of factors
Using one or more of the methods below, the researcher determines an appropriate range of solutions to investigate. Methods may not agree. For instance, the Kaiser criterion may suggest five factors and the scree test may suggest two, so the researcher may request 3-, 4-, and 5-factor solutions discuss each in terms of their relation to external data and theory.
Comprehensibility: A purely subjective criterion would be to retain those factors whose meaning is comprehensible to the researcher. This is not recommended .
Kaiser criterion: The Kaiser rule is to drop all components with eigenvalues under 1.0 – this being the eigenvalue equal to the information accounted for by an average single item. The Kaiser criterion is the default in SPSS and most statistical software but is not recommended when used as the sole cut-off criterion for estimating the number of factors as it tends to overextract factors.[6] A variation of this method has been created where a researcher calculates confidence intervals for each eigenvalue and retains only factors which have the entire confidence interval greater than 1.0.[7][8]
Variance explained criteria: Some researchers simply use the rule of keeping enough factors to account for 90% (sometimes 80%) of the variation. Where the researcher's goal emphasizes parsimony (explaining variance with as few factors as possible), the criterion could be as low as 50%
Scree plot: The Cattell scree test plots the components as the X axis and the corresponding eigenvalues as the Y-axis. As one moves to the right, toward later components, the eigenvalues drop. When the drop ceases and the curve makes an elbow toward less steep decline, Cattell's scree test says to drop all further components after the one starting the elbow. This rule is sometimes criticised for being amenable to researcher-controlled "fudging". That is, as picking the "elbow" can be subjective because the curve has multiple elbows or is a smooth curve, the researcher may be tempted to set the cut-off at the number of factors desired by their research agenda.
Horn's Parallel Analysis (PA): A Monte-Carlo based simulation method that compares the observed eigenvalues with those obtained from uncorrelated normal variables. A factor or component is retained if the associated eigenvalue is bigger than the 95th of the distribution of eigenvalues derived from the random data. PA is one of the most recommendable rules for determining the number of components to retain, but only few programs include this option.[9]
However, before dropping a factor below one's cutoff, the analyst(s) should create a data set based on the factor loadings and check the scores' correlation with any given dependent variable(s) of interest. Scores based on a factor with a very small eigenvalue can correlate strongly with dependent variables, in which case dropping such a factor from a theoretical model may reduce its predictive validity.
Velicer’s (1976) MAP test[10] “involves a complete principal components analysis followed by the examination of a series of matrices of partial correlations” (p. 397). The squared correlation for Step “0” (see Figure 4) is the average squared off-diagonal correlation for the unpartialed correlation matrix. On Step 1, the first principal component and its associated items are partialed out. Thereafter, the average squared off-diagonal correlation for the subsequent correlation matrix is then computed for Step 1. On Step 2, the first two principal components are partialed out and the resultant average squared off-diagonal correlation is again computed. The computations are carried out for k minus one step (k representing the total number of variables in the matrix). Thereafter, all of the average squared correlations for each step are lined up and the step number in the analyses that resulted in the lowest average squared partial correlation determines the number of components or factors to retain (Velicer, 1976). By this method, components are maintained as long as the variance in the correlation matrix represents systematic variance, as opposed to residual or error variance. Although methodologically akin to principal components analysis, the MAP technique has been shown to perform quite well in determining the number of factors to retain in multiple simulation studies.[8][11][12] This procedure is made available through SPSS's user interface. See Courtney (2013)[13] for guidance.
Rotation methods
The unrotated output maximises variance accounted for by the first and subsequent factors, and forcing the factors to be orthogonal. This data-compression comes at the cost of having most items load on the early factors, and usually, of having many items load substantially on more than one factor. Rotation serves to make the output more understandable, by seeking so-called "Simple Structure": A pattern of loadings where items load most strongly on one factor, and much more weakly on the other factors. Rotations can be orthogonal or oblique (allowing the factors to correlate).
Varimax rotation is an orthogonal rotation of the factor axes to maximize the variance of the squared loadings of a factor (column) on all the variables (rows) in a factor matrix, which has the effect of differentiating the original variables by extracted factor. Each factor will tend to have either large or small loadings of any particular variable. A varimax solution yields results which make it as easy as possible to identify each variable with a single factor. This is the most common rotation option. However, the orthogonality (i.e., independence) of factors is often an unrealistic assumption. Oblique rotations are inclusive of orthogonal rotation, and for that reason, oblique rotations are a preferred method.[14]
Quartimax rotation is an orthogonal alternative which minimizes the number of factors needed to explain each variable. This type of rotation often generates a general factor on which most variables are loaded to a high or medium degree. Such a factor structure is usually not helpful to the research purpose.
Equimax rotation is a compromise between Varimax and Quartimax criteria.
Direct oblimin rotation is the standard method when one wishes a non-orthogonal (oblique) solution – that is, one in which the factors are allowed to be correlated. This will result in higher eigenvalues but diminished interpretability of the factors. See below.
Promax rotation is an alternative non-orthogonal (oblique) rotation method which is computationally faster than the direct oblimin method and therefore is sometimes used for very large datasets.
Factor analysis in psychometrics
History
Charles Spearman pioneered the use of factor analysis in the field of psychology and is sometimes credited with the invention of factor analysis. He discovered that school children's scores on a wide variety of seemingly unrelated subjects were positively correlated, which led him to postulate that a general mental ability, or g, underlies and shapes human cognitive performance. His postulate now enjoys broad support in the field of intelligence research, where it is known as the g theory.
Raymond Cattell expanded on Spearman's idea of a two-factor theory of intelligence after performing his own tests and factor analysis. He used a multi-factor theory to explain intelligence. Cattell's theory addressed alternate factors in intellectual development, including motivation and psychology. Cattell also developed several mathematical methods for adjusting psychometric graphs, such as his "scree" test and similarity coefficients. His research led to the development of his theory of fluid and crystallized intelligence, as well as his 16 Personality Factors theory of personality. Cattell was a strong advocate of factor analysis and psychometrics. He believed that all theory should be derived from research, which supports the continued use of empirical observation and objective testing to study human intelligence.
Applications in psychology
Factor analysis is used to identify "factors" that explain a variety of results on different tests. For example, intelligence research found that people who get a high score on a test of verbal ability are also good on other tests that require verbal abilities. Researchers explained this by using factor analysis to isolate one factor, often called crystallized intelligence or verbal intelligence, which represents the degree to which someone is able to solve problems involving verbal skills.
Factor analysis in psychology is most often associated with intelligence research. However, it also has been used to find factors in a broad range of domains such as personality, attitudes, beliefs, etc. It is linked to psychometrics, as it can assess the validity of an instrument by finding if the instrument indeed measures the postulated factors.
Advantages
- Reduction of number of variables, by combining two or more variables into a single factor. For example, performance at running, ball throwing, batting, jumping and weight lifting could be combined into a single factor such as general athletic ability. Usually, in an item by people matrix, factors are selected by grouping related items. In the Q factor analysis technique, the matrix is transposed and factors are created by grouping related people: For example, liberals, libertarians, conservatives and socialists, could form separate groups.
- Identification of groups of inter-related variables, to see how they are related to each other. For example, Carroll used factor analysis to build his Three Stratum Theory. He found that a factor called "broad visual perception" relates to how good an individual is at visual tasks. He also found a "broad auditory perception" factor, relating to auditory task capability. Furthermore, he found a global factor, called "g" or general intelligence, that relates to both "broad visual perception" and "broad auditory perception". This means someone with a high "g" is likely to have both a high "visual perception" capability and a high "auditory perception" capability, and that "g" therefore explains a good part of why someone is good or bad in both of those domains.
Disadvantages
- "...each orientation is equally acceptable mathematically. But different factorial theories proved to differ as much in terms of the orientations of factorial axes for a given solution as in terms of anything else, so that model fitting did not prove to be useful in distinguishing among theories." (Sternberg, 1977[15]). This means all rotations represent different underlying processes, but all rotations are equally valid outcomes of standard factor analysis optimization. Therefore, it is impossible to pick the proper rotation using factor analysis alone.
- Factor analysis can be only as good as the data allows. In psychology, where researchers often have to rely on less valid and reliable measures such as self-reports, this can be problematic.
- Interpreting factor analysis is based on using a "heuristic", which is a solution that is "convenient even if not absolutely true".[16] More than one interpretation can be made of the same data factored the same way, and factor analysis cannot identify causality.
Exploratory factor analysis versus principal components analysis
While exploratory factor analysis and principal component analysis are treated as synonymous techniques in some fields of statistics, this has been criticised (e.g. Fabrigar et al., 1999;[17] Suhr, 2009[18]). In factor analysis, the researcher makes the assumption that an underlying causal model exists, whereas PCA is simply a variable reduction technique.[19] Researchers have argued that the distinctions between the two techniques may mean that there are objective benefits for preferring one over the other based on the analytic goal. If the factor model is incorrectly formulated or the assumptions are not met, then factor analysis will give erroneous results. Factor analysis has been used successfully where adequate understanding of the system permits good initial model formulations. Principal component analysis employs a mathematical transformation to the original data with no assumptions about the form of the covariance matrix. The aim of PCA is to determine a few linear combinations of the original variables that can be used to summarize the data set without losing much information.[20]
Arguments contrasting PCA and EFA
Fabrigar et al. (1999)[17] address a number of reasons used to suggest that principal components analysis is not equivalent to factor analysis:
- It is sometimes suggested that principal components analysis is computationally quicker and requires fewer resources than factor analysis. Fabrigar et al. suggest that the ready availability of computer resources have rendered this practical concern irrelevant.
- PCA and factor analysis can produce similar results. This point is also addressed by Fabrigar et al.; in certain cases, whereby the communalities are low (e.g., .40), the two techniques produce divergent results. In fact, Fabrigar et al. argue that in cases where the data correspond to assumptions of the common factor model, the results of PCA are inaccurate results.
- There are certain cases where factor analysis leads to 'Heywood cases'. These encompass situations whereby 100% or more of the variance in a measured variable is estimated to be accounted for by the model. Fabrigar et al. suggest that these cases are actually informative to the researcher, indicating a misspecified model or a violation of the common factor model. The lack of Heywood cases in the PCA approach may mean that such issues pass unnoticed.
- Researchers gain extra information from a PCA approach, such as an individual’s score on a certain component – such information is not yielded from factor analysis. However, as Fabrigar et al. contend, the typical aim of factor analysis – i.e. to determine the factors accounting for the structure of the correlations between measured variables – does not require knowledge of factor scores and thus this advantage is negated. It is also possible to compute factor scores from a factor analysis.
Variance versus covariance
Factor analysis takes into account the random error that is inherent in measurement, whereas PCA fails to do so. This point is exemplified by Brown (2009),[21] who indicated that, in respect to the correlation matrices involved in the calculations:
"In PCA, 1.00s are put in the diagonal meaning that all of the variance in the matrix is to be accounted for (including variance unique to each variable, variance common among variables, and error variance). That would, therefore, by definition, include all of the variance in the variables. In contrast, in EFA, the communalities are put in the diagonal meaning that only the variance shared with other variables is to be accounted for (excluding variance unique to each variable and error variance). That would, therefore, by definition, include only variance that is common among the variables."— Brown (2009), Principal components analysis and exploratory factor analysis – Definitions, differences and choices
For this reason, Brown (2009) recommends using factor analysis when theoretical ideas about relationships between variables exist, whereas PCA should be used if the goal of the researcher is to explore patterns in their data.
Differences in procedure and results
The differences between principal components analysis and factor analysis are further illustrated by Suhr (2009):
- PCA results in principal components that account for a maximal amount of variance for observed variables; FA account for common variance in the data.[18]
- PCA inserts ones on the diagonals of the correlation matrix; FA adjusts the diagonals of the correlation matrix with the unique factors.[18]
- PCA minimizes the sum of squared perpendicular distance to the component axis; FA estimates factors which influence responses on observed variables.[18]
- The component scores in PCA represent a linear combination of the observed variables weighted by eigenvectors; the observed variables in FA are linear combinations of the underlying and unique factors.[18]
- In PCA, the components yielded are uninterpretable, i.e. they do not represent underlying ‘constructs’; in FA, the underlying constructs can be labeled and readily interpreted, given an accurate model specification.[18]
Factor analysis in marketing
The basic steps are:
- Identify the salient attributes consumers use to evaluate products in this category.
- Use quantitative marketing research techniques (such as surveys) to collect data from a sample of potential customers concerning their ratings of all the product attributes.
- Input the data into a statistical program and run the factor analysis procedure. The computer will yield a set of underlying attributes (or factors).
- Use these factors to construct perceptual maps and other product positioning devices.
Information collection
The data collection stage is usually done by marketing research professionals. Survey questions ask the respondent to rate a product sample or descriptions of product concepts on a range of attributes. Anywhere from five to twenty attributes are chosen. They could include things like: ease of use, weight, accuracy, durability, colourfulness, price, or size. The attributes chosen will vary depending on the product being studied. The same question is asked about all the products in the study. The data for multiple products is coded and input into a statistical program such as R, SPSS, SAS, Stata, STATISTICA, JMP, and SYSTAT.
Analysis
The analysis will isolate the underlying factors that explain the data using a matrix of associations.[22] Factor analysis is an interdependence technique. The complete set of interdependent relationships is examined. There is no specification of dependent variables, independent variables, or causality. Factor analysis assumes that all the rating data on different attributes can be reduced down to a few important dimensions. This reduction is possible because some attributes may be related to each other. The rating given to any one attribute is partially the result of the influence of other attributes. The statistical algorithm deconstructs the rating (called a raw score) into its various components, and reconstructs the partial scores into underlying factor scores. The degree of correlation between the initial raw score and the final factor score is called a factor loading.
Advantages
- Both objective and subjective attributes can be used provided the subjective attributes can be converted into scores.
- Factor analysis can identify latent dimensions or constructs that direct analysis may not.
- It is easy and inexpensive.
Disadvantages
- Usefulness depends on the researchers' ability to collect a sufficient set of product attributes. If important attributes are excluded or neglected, the value of the procedure is reduced.
- If sets of observed variables are highly similar to each other and distinct from other items, factor analysis will assign a single factor to them. This may obscure factors that represent more interesting relationships.
- Naming factors may require knowledge of theory because seemingly dissimilar attributes can correlate strongly for unknown reasons.
Factor analysis in physical and biological sciences
Factor analysis has also been widely used in physical sciences such as geochemistry, ecology, hydrochemistry.,[23] astrophysics, cosmology, as well as biological sciences such as molecular biology and biochemistry.
In groundwater quality management, it is important to relate the spatial distribution of different chemical parameters to different possible sources, which have different chemical signatures. For example, a sulfide mine is likely to be associated with high levels of acidity, dissolved sulfates and transition metals. These signatures can be identified as factors through R-mode factor analysis, and the location of possible sources can be suggested by contouring the factor scores.[24]
In geochemistry, different factors can correspond to different mineral associations, and thus to mineralisation.[25]
Factor analysis in microarray analysis
Factor analysis can be used for summarizing high-density oligonucleotide DNA microarrays data at probe level for Affymetrix GeneChips. In this case, the latent variable corresponds to the RNA concentration in a sample.[26]
Implementation
Factor analysis has been implemented in several statistical analysis programs since the 1980s: SAS, BMDP and SPSS.[27] It is also implemented in the R programming language (with the factanal function), OpenOpt, and the statistical software package Stata. Rotations are implemented in the GPArotation R package.
See also
| Wikimedia Commons has media related to Factor analysis. |
- Design of experiments
- Formal concept analysis
- Higher-order factor analysis
- Independent component analysis
- Non-negative matrix factorization
- Perceptual mapping
- Product management
- Q methodology
- Recommendation system
- Root cause analysis
- Varimax rotation
- Generalized Structured Component Analysis
References
- ↑ Bartholomew, D.J.; Steele, F.; Galbraith, J.; Moustaki, I. (2008). Analysis of Multivariate Social Science Data. Statistics in the Social and Behavioral Sciences Series (2nd ed.). Taylor & Francis. ISBN 1584889608.
- ↑ 2.0 2.1 2.2 Harman, Harry H. (1976). Modern Factor Analysis. University of Chicago Press. pp. 175, 176. ISBN 0-226-31652-1.
- ↑ 3.0 3.1 3.2 3.3 3.4 3.5 3.6 3.7 3.8 Polit DF Beck CT (2012). Nursing Research: Generating and Assessing Evidence for Nursing Practice, 9th ed. Philadelphia, USA: Wolters Klower Health, Lippincott Williams & Wilkins.
- ↑ Meng, J. (2011). "Uncover cooperative gene regulations by microRNAs and transcription factors in glioblastoma using a nonnegative hybrid factor model". International Conference on Acoustics, Speech and Signal Processing.
- ↑ Liou, C.-Y.; Musicus, B.R. (2008). "Cross Entropy Approximation of Structured Gaussian Covariance Matrices". IEEE Transactions on Signal Processing 56 (7): 3362–3367. doi:10.1109/TSP.2008.917878.
- ↑ Bandalos, D.L.; Boehm-Kaufman, M.R. (2008). "Four common misconceptions in exploratory factor analysis". In Lance, Charles E.; Vandenberg, Robert J. Statistical and Methodological Myths and Urban Legends: Doctrine, Verity and Fable in the Organizational and Social Sciences. Taylor & Francis. pp. 61–87. ISBN 978-0-8058-6237-9.
- ↑ Larsen, R., & Warne, R. T. (2010). Estimating confidence intervals for eigenvalues in exploratory factor analysis. Behavior Research Methods, 42, 871-876. doi:10.3758/BRM.42.3.871
- ↑ 8.0 8.1 Warne, R. T., & Larsen, R. (2014). Evaluating a proposed modification of the Guttman rule for determining the number of factors in an exploratory factor analysis. Psychological Test and Assessment Modeling, 56, 104-123.
- ↑
- Ledesma, R.D.; Valero-Mora, P. (2007). "Determining the Number of Factors to Retain in EFA: An easy-to-use computer program for carrying out Parallel Analysis". Practical Assessment Research & Evaluation 12 (2): 1–11.
- ↑ Velicer, W.F. (1976). "Determining the number of components from the matrix of partial correlations". Psychometrika 41: 321–327. doi:10.1007/bf02293557.
- ↑ Ruscio, John; Roche, B. (2012). "Determining the number of factors to retain in an exploratory factor analysis using comparison data of known factorial structure". Psychological Assessment 24: 282–292. doi:10.1037/a0025697.
- ↑ Garrido, L. E., & Abad, F. J., & Ponsoda, V. (2012). A new look at Horn's parallel analysis with ordinal variables. Psychological Methods. Advance online publication. doi:10.1037/a0030005
- ↑ Courtney, M. G. R. (2013). Determining the number of factors to retain in EFA: Using the SPSS R-Menu v2.0 to make more judicious estimations. Practical Assessment, Research and Evaluation, 18(8). Available online: http://pareonline.net/getvn.asp?v=18&n=8
- ↑ Russell, D.W. (December 2002). "In search of underlying dimensions: The use (and abuse) of factor analysis in Personality and Social Psychology Bulletin". Personality and Social Psychology Bulletin 28 (12): 1629–46. doi:10.1177/014616702237645.
- ↑ Sternberg, R. J. (1977). Metaphors of Mind: Conceptions of the Nature of Intelligence. New York: Cambridge University Press. pp. 85–111.
- ↑ Richard B. Darlington (2004) "Factor Analysis". Retrieved July 22, 2004.
- ↑ 17.0 17.1 Fabrigar et al. (1999). "Evaluating the use of exploratory factor analysis in psychological research." (PDF). Psychological Methods.
- ↑ 18.0 18.1 18.2 18.3 18.4 18.5 Suhr, Diane (2009). "Principal component analysis vs. exploratory factor analysis" (PDF). SUGI 30 Proceedings. Retrieved 5 April 2012.
- ↑ SAS Statistics. "Principal Components Analysis" (PDF). SAS Support Textbook.
- ↑ Meglen, R.R. (1991). "Examining Large Databases: A Chemometric Approach Using Principal Component Analysis". Journal of Chemometrics 5 (3): 163–179. doi:10.1002/cem.1180050305/.
- ↑ Brown, J. D. (January 2009). "Principal components analysis and exploratory factor analysis – Definitions, differences and choices." (PDF). Shiken: JALT Testing & Evaluation SIG Newsletter. Retrieved 16 April 2012.
- ↑ Ritter, N. (2012). A comparison of distribution-free and non-distribution free methods in factor analysis. Paper presented at Southwestern Educational Research Association (SERA) Conference 2012, New Orleans, LA (ED529153).
- ↑ Subbarao, C.; Subbarao, N.V.; Chandu, S.N. (December 1996). "Characterisation of groundwater contamination using factor analysis". Environmental Geology 28 (4): 175–180. doi:10.1007/s002540050091.
- ↑ Love, D.; Hallbauer, D.K.; Amos, A.; Hranova, R.K. (2004). "Factor analysis as a tool in groundwater quality management: two southern African case studies". Physics and Chemistry of the Earth 29: 1135–43. doi:10.1016/j.pce.2004.09.027.
- ↑ Barton, E.S.; Hallbauer, D.K. (1996). "Trace-element and U—Pb isotope compositions of pyrite types in the Proterozoic Black Reef, Transvaal Sequence, South Africa: Implications on genesis and age". Chemical Geology 133: 173–199. doi:10.1016/S0009-2541(96)00075-7.
- ↑ Hochreiter, Sepp; Clevert, Djork-Arné; Obermayer, Klaus (2006). "A new summarization method for affymetrix probe level data". Bioinformatics 22 (8): 943–9. doi:10.1093/bioinformatics/btl033. PMID 16473874.
- ↑ MacCallum, Robert (June 1983). "A comparison of factor analysis programs in SPSS, BMDP, and SAS". Psychometrika 48 (48). doi:10.1007/BF02294017.
- ↑ Ishida, E.E.O & de Souza, R.S.. Hubble parameter reconstruction from a principal component analysis: minimizing the bias.Astronomy & Astrophysics, Volume 527, id.A49 (2011)
Further reading
- Child, Dennis (2006). The Essentials of Factor Analysis (3rd ed.). Continuum International. ISBN 978-0-8264-8000-2.
- Fabrigar, L.R.; Wegener, D.T.; MacCallum, R.C.; Strahan, E.J. (September 1999). "Evaluating the use of exploratory factor analysis in psychological research". Psychological Methods 4 (3): 272–299. doi:10.1037/1082-989X.4.3.272.
Jennrich, Robert I., "Rotation to Simple Loadings Using Component Loss Function: The Oblique Case," Psychometrika, Vol. 71, No. 1, pp. 173–191, March 2006.
Katz, Jeffrey Owen, and Rohlf, F. James. Primary product functionplane: An oblique rotation to simple structure. Multivariate Behavioral Research, April 1975, Vol. 10, pp. 219–232.
Katz, Jeffrey Owen, and Rohlf, F. James. Functionplane: A new approach to simple structure rotation. Psychometrika, March 1974, Vol. 39, No. 1, pp. 37–51.
Katz, Jeffrey Owen, and Rohlf, F. James. Function-point cluster analysis. Systematic Zoology, September 1973, Vol. 22, No. 3, pp. 295–301.
- Thompson, B. (2004). Exploratory and confirmatory factor analysis: Understanding concepts and applications. Washington DC: American Psychological Association. ISBN 1591470935.
External links
- Factor Analysis. Retrieved July 23, 2004,
- Raymond Cattell. Retrieved July 22, 2004, from http://www.indiana.edu/~intell/rcattell.shtml
- Exploratory Factor Analysis - A Book Manuscript by Tucker, L. & MacCallum R. (1993). Retrieved June 8, 2006, from: http://www.unc.edu/~rcm/book/factornew.htm
- Garson, G. David, "Factor Analysis," from Statnotes: Topics in Multivariate Analysis. Retrieved on April 13, 2009 from http://www2.chass.ncsu.edu/garson/pa765/statnote.htm
- Factor Analysis at 100 —conference material
- FARMS - Factor Analysis for Robust Microarray Summarization, an R package —software