Empirical measure
In probability theory, an empirical measure is a random measure arising from a particular realization of a (usually finite) sequence of random variables. The precise definition is found below. Empirical measures are relevant to mathematical statistics.
The motivation for studying empirical measures is that it is often impossible to know the true underlying probability measure 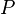 . We collect observations
. We collect observations 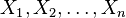 and compute relative frequencies. We can estimate , or a related distribution function
and compute relative frequencies. We can estimate , or a related distribution function 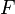 by means of the empirical measure or empirical distribution function, respectively. These are uniformly good estimates under certain conditions. Theorems in the area of empirical processes provide rates of this convergence.
by means of the empirical measure or empirical distribution function, respectively. These are uniformly good estimates under certain conditions. Theorems in the area of empirical processes provide rates of this convergence.
Definition
Let 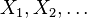 be a sequence of independent identically distributed random variables with values in the state space S with probability measure P.
be a sequence of independent identically distributed random variables with values in the state space S with probability measure P.
Definition
- The empirical measure Pn is defined for measurable subsets of S and given by
- where
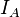 is the indicator function and
is the indicator function and 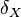 is the Dirac measure.
is the Dirac measure.
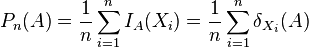
For a fixed measurable set A, nPn(A) is a binomial random variable with mean nP(A) and variance nP(A)(1 − P(A)). In particular, Pn(A) is an unbiased estimator of P(A).
Definition
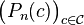 is the empirical measure indexed by
is the empirical measure indexed by 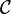 , a collection of measurable subsets of S.
, a collection of measurable subsets of S.
To generalize this notion further, observe that the empirical measure  maps measurable functions
maps measurable functions 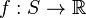 to their empirical mean,
to their empirical mean,
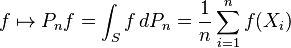
In particular, the empirical measure of A is simply the empirical mean of the indicator function, Pn(A) = Pn IA.
For a fixed measurable function 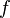 ,
, 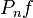 is a random variable with mean
is a random variable with mean 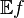 and variance
and variance 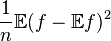 .
.
By the strong law of large numbers, Pn(A) converges to P(A) almost surely for fixed A. Similarly converges to almost surely for a fixed measurable function . The problem of uniform convergence of Pn to P was open until Vapnik and Chervonenkis solved it in 1968.[1]
If the class (or 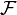 ) is Glivenko–Cantelli with respect to P then Pn converges to P uniformly over
) is Glivenko–Cantelli with respect to P then Pn converges to P uniformly over 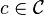 (or
(or 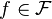 ). In other words, with probability 1 we have
). In other words, with probability 1 we have
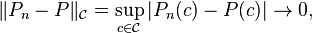
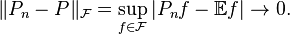
Empirical distribution function
The empirical distribution function provides an example of empirical measures. For real-valued iid random variables 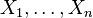 it is given by
it is given by
![F_n(x)=P_n((-\infty,x])=P_nI_{(-\infty,x]}.](../I/m/b46a6b6ef0d1c2b968194ccfba575624.png)
In this case, empirical measures are indexed by a class ![\mathcal{C}=\{(-\infty,x]:x\in\mathbb{R}\}.](../I/m/4fca1a7b215a1aa5cdbf96e6673cd628.png) It has been shown that is a uniform Glivenko–Cantelli class, in particular,
It has been shown that is a uniform Glivenko–Cantelli class, in particular,
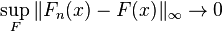
with probability 1.
See also
References
- ↑ Vapnik, V.; Chervonenkis, A (1968). "Uniform convergence of frequencies of occurrence of events to their probabilities". Dokl. Akad. Nauk SSSR 181.
Further reading
- Billingsley, P. (1995). Probability and Measure (Third ed.). New York: John Wiley and Sons. ISBN 0-471-80478-9.
- Donsker, M. D. (1952). "Justification and extension of Doob's heuristic approach to the Kolmogorov–Smirnov theorems". Annals of Mathematical Statistics 23 (2): 277–281. doi:10.1214/aoms/1177729445.
- Dudley, R. M. (1978). "Central limit theorems for empirical measures". Annals of Probability 6 (6): 899–929. doi:10.1214/aop/1176995384. JSTOR 2243028.
- Dudley, R. M. (1999). Uniform Central Limit Theorems. Cambridge Studies in Advanced Mathematics 63. Cambridge, UK: Cambridge University Press. ISBN 0-521-46102-2.
- Wolfowitz, J. (1954). "Generalization of the theorem of Glivenko–Cantelli". Annals of Mathematical Statistics 25 (1): 131–138. doi:10.1214/aoms/1177728852. JSTOR 2236518.