Edit distance
In computer science, edit distance is a way of quantifying how dissimilar two strings (e.g., words) are to one another by counting the minimum number of operations required to transform one string into the other. Edit distances find applications in natural language processing, where automatic spelling correction can determine candidate corrections for a misspelled word by selecting words from a dictionary that have a low distance to the word in question. In bioinformatics, it can be used to quantify the similarity of macromolecules such as DNA, which can be viewed as strings of the letters A, C, G and T.
Several definitions of edit distance exist, using different sets of string operations. One of the most common variants is called Levenshtein distance, named after the Soviet Russian computer scientist Vladimir Levenshtein. In this version, the allowed operations are the removal or insertion of a single character, or the substitution of one character for another. Levenshtein distance may also simply be called "edit distance", although several variants exist.[1]
Formal definition and properties
Given two strings a and b on an alphabet Σ (e.g. the set of ASCII characters, the set of bytes [0..255], etc.), the edit distance d(a, b) is the minimum-weight series of edit operations that transforms a into b. One of the simplest sets of edit operations is that defined by Levenshtein in 1966:[2]
- Insertion of a single symbol. If a = uv, then inserting the symbol x produces uxv. This can also be denoted ε→x, using ε to denote the empty string.
- Deletion of a single symbol changes uxv to uv (x→ε).
- Substitution of a single symbol x for a symbol y ≠ x changes uxv to uyv (x→y).
In Levenshtein's original definition, each of these operations has unit cost (except that substitution of a character by itself has zero cost), so the Levenshtein distance is equal to the minimum number of operations required to transform a to b. A more general definition associates non-negative weight functions wins(x), wdel(x) and wsub(x y) with the operations.[2]
Additional primitive operations have been suggested. A common mistake when typing text is transposition of two adjacent characters commonly occur, formally characterized by an operation that changes uxyv into uyxv where x, y ∈ Σ.[3][4] For the task of correcting OCR output, merge and split operations have been used which replace a single character into a pair of them or vice versa.[4]
Other variants of edit distance are obtained by restricting the set of operations. Longest common subsequence (LCS) distance is edit distance with insertion and deletion as the only two edit operations, both at unit cost.[1]:37 Similarly, by only allowing substitutions (again at unit cost), Hamming distance is obtained; this must be restricted to equal-length strings.[1] Jaro–Winkler distance can be obtained from an edit distance where only transpositions are allowed.
Example
The Levenshtein distance between "kitten" and "sitting" is 3. The minimal edit script that transforms the former into the latter is:
- kitten → sitten (substitution of "s" for "k")
- sitten → sittin (substitution of "i" for "e")
- sittin → sitting (insertion of "g" at the end).
LCS distance (insertions and deletions only) gives a different distance and minimal edit script:
- delete k at 0
- insert s at 0
- delete e at 4
- insert i at 4
- insert g at 6
for a total cost/distance of 5 operations.
Properties
Edit distance with non-negative cost satisfies the axioms of a metric, giving rise to a metric space of strings, when the following conditions are met:[1]:37
- Every edit operation has positive cost;
- for every operation, there is an inverse operation with equal cost.
With these properties, the metric axioms are satisfied as follows:
- d(a, a) = 0, since each string can be trivially transformed to itself using exactly zero operations.
- d(a, b) > 0 when a ≠ b, since this would require at least one operation at non-zero cost.
- d(a, b) = d(b, a) by equality of the cost of each operation and its inverse.
- Triangle inequality: d(a, c) ≤ d(a, b) + d(b, c).[5]
Levenshtein distance and LCS distance with unit cost satisfy the above conditions, and therefore the metric axioms. Variants of edit distance that are not proper metrics have also been considered in the literature.[1]
Other useful properties of unit-cost edit distances include:
- LCS distance is bounded above by the sum of lengths of a pair of strings.[1]:37
- LCS distance is an upper bound on Levenshtein distance.
- For strings of the same length, Hamming distance is an upper bound on Levenshtein distance.[1]
Regardless of cost/weights, the following property holds of all edit distances:
- When a and b share a common prefix, this prefix has no effect on the distance. Formally, when a = uv and b = uw, then d(a, b) = d(v, w).[4] This allows speeding up many computations involving edit distance and edit scripts, since common prefixes and suffixes can be skipped in linear time.
Computation
Basic algorithm
Using Levenshtein's original operations, the edit distance between 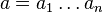 and
and 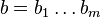 is given by
is given by 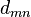 , defined by the recurrence[2]
, defined by the recurrence[2]
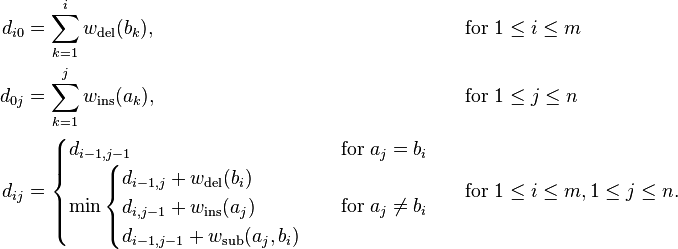
This algorithm can be generalized to handle transpositions by adding another term in the recursive clause's minimization.[3]
The straightforward, recursive way of evaluating this recurrence takes exponential time. Therefore, it is usually computed using a dynamic programming algorithm that is commonly credited to Wagner and Fischer,[6] although it has a history of multiple invention.[2][3]
After completion of the Wagner–Fischer algorithm, a minimal sequence of edit operations can be read off as a backtrace of the operations used during the dynamic programming algorithm starting at .
This algorithm has a time complexity of Θ(mn). When the full dynamic programming table is constructed, its space complexity is also Θ(mn); this can be improved to Θ(min(m,n)) by observing that at any instant, the algorithm only requires two rows (or two columns) in memory. However, this optimization makes it impossible to read off the minimal series of edit operations.[3] A linear-space solution to this problem is offered by Hirschberg's algorithm.[7]:634
Improved algorithms
Improving on the Wagner–Fisher algorithm described above, Ukkonen describes several variants,[8] one of which takes two strings and a maximum edit distance s, and returns min(s, d). It achieves this by only computing and storing a part of the dynamic programming table around its diagonal. This algorithm takes time O(s×min(m,n)), where m and n are the lengths of the strings. Space complexity is O(s²) or O(s), depending on whether the edit sequence needs to be read off.[3]
Applications
Edit distance finds applications in computational biology and natural language processing, e.g. the correction of spelling mistakes or OCR errors, and approximate string matching, where the objective is to find matches for short strings in many longer texts, in situations where a small number of differences is to be expected.
Various algorithms exist that solve problems beside the computation of distance between a pair of strings, to solve related types of problems.
- Hirschberg's algorithm computes the optimal alignment of two strings, where optimality is defined as minimizing edit distance.
- Approximate string matching can be formulated in terms of edit distance. Ukkonen's 1985 algorithm takes a string p, called the pattern, and a constant k; it then builds a deterministic finite state automaton that finds, in an arbitrary string s, a substring whose edit distance to p is at most k[9] (cf. the Aho–Corasick algorithm, which similarly constructs an automaton to search for any of a number of patterns, but without allowing edit operations). A similar algorithm for approximate string matching is the bitap algorithm, also defined in terms of edit distance.
- Levenshtein automata are finite-state machines that recognize a set of strings within bounded edit distance of a fixed reference string.[4]
References
- ↑ 2.0 2.1 2.2 2.3 Daniel Jurafsky; James H. Martin. Speech and Language Processing. Pearson Education International. pp. 107–111.
- ↑ 3.0 3.1 3.2 3.3 3.4 Esko Ukkonen (1983). On approximate string matching. Foundations of Computation Theory. Springer. pp. 487–495.
- ↑ 4.0 4.1 4.2 4.3 Schulz, Klaus U.; Mihov, Stoyan (2002). "Fast string correction with Levenshtein automata". International Journal of Document Analysis and Recognition 5 (1): 67–85. doi:10.1007/s10032-002-0082-8. CiteSeerX: 10
.1 ..1 .16 .652 - ↑ Lei Chen; Raymond Ng (2004). On the marriage of Lₚ-norms and edit distance. Proc. 30th Int'l Conf. on Very Large Databases (VLDB) 30.
- ↑ R. Wagner; M. Fischer (1974). "The string-to-string correction problem". J. ACM 21: 168–178. doi:10.1145/321796.321811.
- ↑ Skiena, Steven (2010). The Algorithm Design Manual (2nd ed.). Springer Science+Business Media. ISBN 1-849-96720-2.
- ↑ "Algorithms for approximate string matching". Information and Control 64 (1–3). 1985.
- ↑ Esko Ukkonen (1985). "Finding approximate patterns in strings". J. Algorithms 6: 132–137. doi:10.1016/0196-6774(85)90023-9.