Diversity index
A diversity index is a quantitative measure that reflects how many different types (such as species) there are in a dataset, and simultaneously takes into account how evenly the basic entities (such as individuals) are distributed among those types. The value of a diversity index increases both when the number of types increases and when evenness increases. For a given number of types, the value of a diversity index is maximized when all types are equally abundant.
When diversity indices are used in ecology, the types of interest are usually species, but they can also be other categories, such as genera, families, functional types or haplotypes. The entities of interest are usually individual plants or animals, and the measure of abundance can be, for example, number of individuals, biomass or coverage. In demography, the entities of interest can be people, and the types of interest various demographic groups. In information science, the entities can be characters and the types the different letters of the alphabet. The most commonly used diversity indices are simple transformations of the effective number of types (also known as 'true diversity'), but each diversity index can also be interpreted in its own right as a measure corresponding to some real phenomenon (but a different one for each diversity index).[1][2][3][4]
True diversity
True diversity, or the effective number of types, refers to the number of equally abundant types needed for the average proportional abundance of the types to equal that observed in the dataset of interest (where all types may not be equally abundant). The true diversity in a dataset is calculated by first taking the weighted generalized mean Mq−1 of the proportional abundances of the types in the dataset, and then taking the reciprocal of this. The equation is:[3][4]
![{}^q\!D={1 \over M_{q-1}}={1 \over \sqrt[q-1]{{\sum_{i=1}^R p_i p_i^{q-1}}}}=\left ( {\sum_{i=1}^R p_i^q} \right )^{1/(1-q)}](../I/m/d473f8fe348489beb5ff3936f7ff8b15.png)
The denominator Mq−1 equals the average proportional abundance of the types in the dataset as calculated with the weighted generalized mean with exponent q-1. In the equation, R is richness (the total number of types in the dataset), and the proportional abundance of the ith type is pi. The proportional abundances themselves are used as the nominal weights. When q=1, the above equation is undefined. However, the mathematical limit as q approaches 1 is well defined and the corresponding diversity is calculated with the following equation:
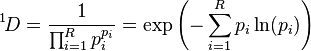
which is the exponential of the Shannon entropy calculated with natural logarithms (see below).
The value of q is often referred to as the order of the diversity. It defines the sensitivity of the diversity value to rare vs. abundant species by modifying how the weighted mean of the species proportional abundances is calculated. With some values of the parameter q, the value of Mq−1 assumes familiar kinds of weighted mean as special cases. In particular, q = 0 corresponds to the weighted harmonic mean, q = 1 to the weighted geometric mean and q = 2 to the weighted arithmetic mean. As q approaches infinity, the weighted generalized mean with exponent q−1 approaches the maximum  value, which is the proportional abundance of the most abundant species in the dataset. Generally, increasing the value of q increases the effective weight given to the most abundant species. This leads to obtaining a larger Mq−1 value and a smaller true diversity (qD) value with increasing q.
value, which is the proportional abundance of the most abundant species in the dataset. Generally, increasing the value of q increases the effective weight given to the most abundant species. This leads to obtaining a larger Mq−1 value and a smaller true diversity (qD) value with increasing q.
When q = 1, the weighted geometric mean of the values is used, and each species is exactly weighted by its proportional abundance (in the weighted geometric mean, the weights are the exponents). When q > 1, the weight given to abundant species is exaggerated, and when q < 1, the weight given to rare species is. At q = 0, the species weights exactly cancel out the species proportional abundances, such that the weighted mean of the values equals 1 / R even when all species are not equally abundant. At q = 0, the effective number of species,  , hence equals the actual number of species R. In the context of diversity, q is generally limited to non-negative values. This is because negative values of q would give rare species so much more weight than abundant ones that
, hence equals the actual number of species R. In the context of diversity, q is generally limited to non-negative values. This is because negative values of q would give rare species so much more weight than abundant ones that  would exceed R.[3][4]
would exceed R.[3][4]
The general equation of diversity is often written in the form[1][2]
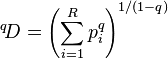
and the term inside the parentheses is called the basic sum. Some popular diversity indices correspond to the basic sum as calculated with different values of q.[2]
Richness
Richness R simply quantifies how many different types the dataset of interest contains. For example, species richness (usually notated S) of a dataset is the number of different species in the corresponding species list. Richness is a simple measure, so it has been a popular diversity index in ecology, where abundance data are often not available for the datasets of interest. Because richness does not take the abundances of the types into account, it is not the same thing as diversity, which does take abundances into account. However, if true diversity is calculated with q = 0, the effective number of types (0D) equals the actual number of types (R).[2][4]
Shannon index
The Shannon index has been a popular diversity index in the ecological literature, where it is also known as Shannon's diversity index, the Shannon–Wiener index, the Shannon–Weaver index and the Shannon entropy. The measure was originally proposed by Claude Shannon to quantify the entropy (uncertainty or information content) in strings of text.[5] The idea is that the more different letters there are, and the more equal their proportional abundances in the string of interest, the more difficult it is to correctly predict which letter will be the next one in the string. The Shannon entropy quantifies the uncertainty (entropy or degree of surprise) associated with this prediction. It is most often calculated as follows:
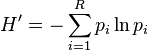
where is the proportion of characters belonging to the ith type of letter in the string of interest. In ecology, is often the proportion of individuals belonging to the ith species in the dataset of interest. Then the Shannon entropy quantifies the uncertainty in predicting the species identity of an individual that is taken at random from the dataset.
Although the equation is here written with natural logarithms, the base of the logarithm used when calculating the Shannon entropy can be chosen freely. Shannon himself discussed logarithm bases 2, 10 and e, and these have since become the most popular bases in applications that use the Shannon entropy. Each log base corresponds to a different measurement unit, which have been called binary digits (bits), decimal digits (decits) and natural digits (nats) for the bases 2, 10 and e, respectively. Comparing Shannon entropy values that were originally calculated with different log bases requires converting them to the same log base: change from the base a to base b is obtained with multiplication by logba.[5]
It has been shown that the Shannon index is based on the weighted geometric mean of the proportional abundances of the types, and that it equals the logarithm of true diversity as calculated with q = 1:[3]
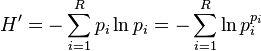
This can also be written
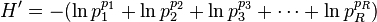
which equals
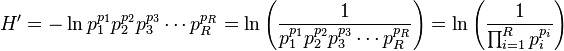
Since the sum of the values equals unity by definition, the denominator equals the weighted geometric mean of the values, with the values themselves being used as the weights (exponents in the equation). The term within the parentheses hence equals true diversity 1D, and H' equals ln(1D).[1][3][4]
When all types in the dataset of interest are equally common, all values equal 1/R, and the Shannon index hence takes the value ln(R). The more unequal the abundances of the types, the larger the weighted geometric mean of the values, and the smaller the corresponding Shannon entropy. If practically all abundance is concentrated to one type, and the other types are very rare (even if there are many of them), Shannon entropy approaches zero. When there is only one type in the dataset, Shannon entropy exactly equals zero (there is no uncertainty in predicting the type of the next randomly chosen entity).
Rényi entropy
The Rényi entropy is a generalization of the Shannon entropy to other values of q than unity. It can be expressed:
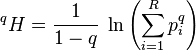
which equals
![{}^qH = \ln\left ( {1 \over \sqrt[q-1]{{\sum_{i=1}^R p_i p_i^{q-1}}}} \right ) = \ln({}^q\!D)](../I/m/fe79da5e6b7cc020b36ba60cd32b0331.png)
This means that taking the logarithm of true diversity based on any value of q gives the Rényi entropy corresponding to the same value of q.
Simpson index
The Simpson index was introduced in 1949 by Edward H. Simpson to measure the degree of concentration when individuals are classified into types.[6] The same index was rediscovered by Orris C. Herfindahl in 1950.[7] The square root of the index had already been introduced in 1945 by the economist Albert O. Hirschman.[8] As a result, the same measure is usually known as the Simpson index in ecology, and as the Herfindahl index or the Herfindahl–Hirschman index (HHI) in economics.
The measure equals the probability that two entities taken at random from the dataset of interest represent the same type.[6] It equals:
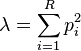
This also equals the weighted arithmetic mean of the proportional abundances of the types of interest, with the proportional abundances themselves being used as the weights.[1] Proportional abundances are by definition constrained to values between zero and unity, but their weighted arithmetic mean, and hence 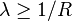 , which is reached when all types are equally abundant.
, which is reached when all types are equally abundant.
By comparing the equation used to calculate λ with the equations used to calculate true diversity, it can be seen that 1/λ equals 2D, i.e. true diversity as calculated with q = 2. The original Simpson's index hence equals the corresponding basic sum.[2]
The interpretation of λ as the probability that two entities taken at random from the dataset of interest represent the same type assumes that the first entity is replaced to the dataset before taking the second entity. If the dataset is very large, sampling without replacement gives approximately the same result, but in small datasets the difference can be substantial. If the dataset is small, and sampling without replacement is assumed, the probability of obtaining the same type with both random draws is:
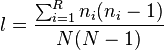
where 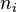 is the number of entities belonging to the ith type and N is the total number of entities in the dataset.[6] This form of the Simpson index is also known as the Hunter–Gaston index in microbiology.[9]
is the number of entities belonging to the ith type and N is the total number of entities in the dataset.[6] This form of the Simpson index is also known as the Hunter–Gaston index in microbiology.[9]
Since mean proportional abundance of the types increases with decreasing number of types and increasing abundance of the most abundant type, λ obtains small values in datasets of high diversity and large values in datasets of low diversity. This is counterintuitive behavior for a diversity index, so often such transformations of λ that increase with increasing diversity have been used instead. The most popular of such indices have been the inverse Simpson index (1/λ) and the Gini–Simpson index (1 − λ).[1][2] Both of these have also been called the Simpson index in the ecological literature, so care is needed to avoid accidentally comparing the different indices as if they were the same.
Inverse Simpson index
The inverse Simpson index equals:
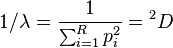
This simply equals true diversity of order 2, i.e. the effective number of types that is obtained when the weighted arithmetic mean is used to quantify average proportional abundance of types in the dataset of interest.
Gini–Simpson index
The original Simpson index λ equals the probability that two entities taken at random from the dataset of interest (with replacement) represent the same type. Its transformation 1 − λ therefore equals the probability that the two entities represent different types. This measure is also known in ecology as the probability of interspecific encounter (PIE)[10] and the Gini–Simpson index.[2] It can be expressed as a transformation of true diversity of order 2:
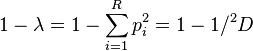
The Gibbs–Martin index of sociology, psychology and management studies,[11] which is also known as the Blau index, is the same measure as the Gini–Simpson index.
Berger–Parker index
The Berger–Parker[12] index equals the maximum value in the dataset, i.e. the proportional abundance of the most abundant type. This corresponds to the weighted generalized mean of the values when q approaches infinity, and hence equals the inverse of true diversity of order infinity (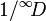 ).
).
See also
References
- ↑ 1.0 1.1 1.2 1.3 1.4 Hill, M. O. (1973). "Diversity and evenness: a unifying notation and its consequences". Ecology 54: 427–432. doi:10.2307/1934352].
- ↑ 2.0 2.1 2.2 2.3 2.4 2.5 2.6 Jost, L (2006). "Entropy and diversity". Oikos 113: 363–375. doi:10.1111/j.2006.0030-1299.14714.x.
- ↑ 3.0 3.1 3.2 3.3 3.4 Tuomisto, H (2010). "A diversity of beta diversities: straightening up a concept gone awry. Part 1. Defining beta diversity as a function of alpha and gamma diversity". Ecography 33: 2–22. doi:10.1111/j.1600-0587.2009.05880.x.
- ↑ 4.0 4.1 4.2 4.3 4.4 Tuomisto, H (2010). "A consistent terminology for quantifying species diversity? Yes, it does exist". Oecologia 4: 853–860. doi:10.1007/s00442-010-1812-0.
- ↑ 5.0 5.1 Shannon, C. E. and Weaver W. (1948) A mathematical theory of communication. The Bell System Technical Journal, 27, 379–423 and 623–656.
- ↑ 6.0 6.1 6.2 Simpson, E. H. (1949). "Measurement of diversity". Nature 163: 688. doi:10.1038/163688a0.
- ↑ Herfindahl, O. C. (1950) Concentration in the U.S. Steel Industry. Unpublished doctoral dissertation, Columbia University.
- ↑ Hirschman, A. O. (1945) National power and the structure of foreign trade. Berkeley.
- ↑ Hunter, PR; Gaston, MA (1988). "Numerical index of the discriminatory ability of typing systems: an application of Simpson's index of diversity". J Clin Microbiol 26 (11): 2465–2466. PMID 3069867.
- ↑ Hurlbert, S.H. (1971). "The nonconcept of species diversity: A critique and alternative parameters". Ecology 52: 577–586. doi:10.2307/1934145.
- ↑ Gibbs, Jack P., and William T. Martin (1962). "Urbanization, technology and the division of labor". American Sociological Review 27: 667–677. JSTOR 2089624.
- ↑ Berger, Wolfgang H.; Parker, Frances L. (June 1970). "Diversity of Planktonic Foraminifera in Deep-Sea Sediments". Science 168 (3937): 1345–1347. doi:10.1126/science.168.3937.1345.
Further reading
- Colinvaux, Paul A. (1973). Introduction to Ecology. Wiley. ISBN 0-471-16498-4.
- Cover, Thomas M.; Thomas, Joy A. (1991). Elements of Information Theory. Wiley. ISBN 0-471-06259-6. See chapter 5 for an elaboration of coding procedures described informally above.
- Chao, A.; Shen, T-J. (2003). "Nonparametric estimation of Shannon's index of diversity when there are unseen species in sample" (PDF). Environmental and Ecological Statistics 10 (4): 429–443. doi:10.1023/A:1026096204727.
External links
- Simpson's Diversity index
- Diversity indices gives some examples of estimates of Simpson's index for real ecosystems.