Disjunct matrix
Disjunct and separable matrices play a pivotal role in the mathematical area of non-adaptive group testing. This area investigates efficient designs and procedures to identify 'needles in haystacks' by conducting the tests on groups of items instead of each item alone. The main concept is that if there are very few special items (needles) and the groups are constructed according to certain combinatorial guidelines, then one can test the groups and find all the needles. This can reduce the cost and the labor associated with of large scale experiments.
The grouping pattern can be represented by a 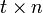 binary matrix, where each column represents an item and each row represents a pool. The symbol '1' denotes participation in the pool and '0' absence from a pool. The d-disjunctness and the d-separability of the matrix describe sufficient condition to identify d special items.
binary matrix, where each column represents an item and each row represents a pool. The symbol '1' denotes participation in the pool and '0' absence from a pool. The d-disjunctness and the d-separability of the matrix describe sufficient condition to identify d special items.
In a matrix that is d-separable, the Boolean sum of every d columns is unique. In a matrix that is d-disjunct the Boolean sum of every d columns does not contain any other column in the matrix. Theoretically, for the same number of columns (items), one can construct d-separable matrices with fewer rows (tests) than d-disjunct. However, designs that are based on d-separable are less applicable since the decoding time to identify the special items is exponential. In contrast, the decoding time for d-disjunct matrices is polynomial.
d-separable
Definition: A matrix 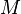 is
is 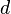 -separable if and only if
-separable if and only if ![\forall S_1 \neq S_2 \subseteq [n]](../I/m/3ffb1d28f6899a4dee0bc888648bcacd.png) where
where 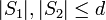 such that
such that 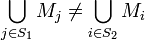
Decoding algorithm
First we will describe another way to look at the problem of group testing and how to decode it from a different notation. We can give a new interpretation of how group testing works as follows:
Group testing: Given input and 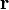 such that
such that 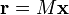 output
output 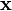
- Take
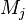 to be the
to be the 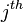 column of
column of - Define
![S_{M_j} \subseteq [t]](../I/m/9bfbeaea54c67a30fa615fe51f2e6986.png) so that
so that 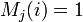 if and only if
if and only if 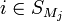
- This gives that
![S_\mathbf{r} = \bigcup_{j \in [n], \mathbf{x}_j = 1} S_{M_j}](../I/m/3b0b8b7c72b0d5706b8fd051d45514fa.png)
This formalizes the relation between and the columns of and in a way more suitable to the thinking of -separable and -disjunct matrices. The algorithm to decode a -separable matrix is as follows:
Given a matrix such that is -separable:
- For each
![T \subseteq [n]](../I/m/d1d2ce2bf4cb0445494a804b2075a360.png) such that
such that 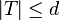 check if
check if 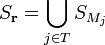
This algorithm runs in time 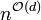 .
.
d-disjunct
In literature disjunct matrices are also called super-imposed codes and d-cover-free families.
Definition: A 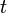 x
x  matrix is d-disjunct if
matrix is d-disjunct if ![\forall S \subseteq [n]](../I/m/6869e632c0be33499721c4226ccf7a26.png) such that
such that 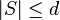 ,
, 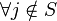
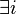 such that
such that 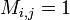 but
but 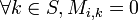 .
Denoting
.
Denoting 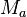 is the
is the 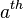 column of and
column of and ![S_{M_a} \subseteq [t]](../I/m/a9aa8a74763de78ec9b6bdf323c790ec.png) where
where 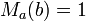 if and only if
if and only if 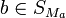 gives that is -disjunct if and only if
gives that is -disjunct if and only if 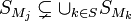
Claim: is -disjunct implies is -separable
Proof: (by contradiction) Let be a x -disjunct matrix. Assume for contradiction that is not -separable. Then there exists ![T_1, T_2 \in [n]](../I/m/d82b44c66a1f46c4cf1adcbd88bfe39e.png) and
and 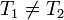 with
with 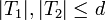 such that
such that 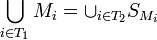 . This implies that
. This implies that 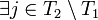 such that
such that 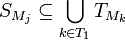 . This contradicts the fact that is -disjunct. Therefore is -separable.
. This contradicts the fact that is -disjunct. Therefore is -separable. 
Decoding algorithm
The algorithm for -separable matrices was still a polynomial in . The following will give a nicer algorithm for -disjunct matrices which will be a multiple instead of raised to the power of given our bounds for . The algorithm is as follows in the proof of the following lemma:
Lemma 1: There exists an 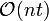 time decoding for any -disjunct x matrix.
time decoding for any -disjunct x matrix.
- Observation 1: For any matrix and given
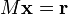 if
if 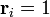 it implies
it implies 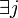 such that and
such that and 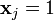 where
where 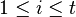 and
and 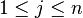 . The opposite is also true. If
. The opposite is also true. If 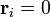 it implies
it implies 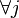 if then
if then 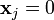 . This is the case because is generated by taking all of the logical or of the
. This is the case because is generated by taking all of the logical or of the 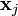 's where .
's where . - Observation 2: For any -disjunct matrix and every set
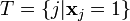 where and for each
where and for each 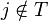 where there exists some
where there exists some 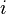 where such that but
where such that but 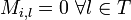 . Thus, if then .
. Thus, if then .
Proof of Lemma 1: Given as input 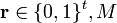 use the following algorithm:
use the following algorithm:
- For each
![j \in [n]](../I/m/bc32adae7f9887f90e1047c7a651e412.png) set
set - For
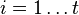 , if then for all , if set
, if then for all , if set
By Observation 1 we get that any position where the appropriate 's will be set to 0 by step 2 of the algorithm. By Observation 2 we have that there is at least one such that if is supposed to be 1 then and, if is supposed to be 1, it can only be the case that as well. Therefore step 2 will never assign the value 0 leaving it as a 1 and solving for . This takes time overall.
d^e-disjunct
Definition:A matrix is 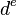 -disjunct if for any
-disjunct if for any 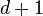 columns
columns 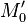 ,
, 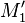 ,
,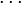 ,
, 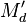 of there are at least
of there are at least 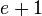 elements
elements 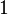 in
in 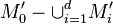 .
.
Definition:Let be a -disjunct matrix. The output 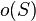 of
of 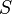 in is the union of those columns indexed by , where is a subset of
in is the union of those columns indexed by , where is a subset of 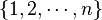 with at most size .
with at most size .
Proposition: Let be a -disjunct matrix. Let 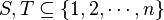 be two distinct subsets with each at most elements. Then the Hamming distance of the outputs and
be two distinct subsets with each at most elements. Then the Hamming distance of the outputs and 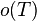 is at least .
is at least .
Proof: Without loss of generality, we may assume s.t. 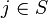 and . We consider the
and . We consider the 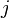 -th column of and those columns of indexed by
-th column of and those columns of indexed by 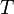 , then we can find different
, then we can find different 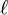 such that
such that 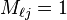 and
and 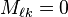 for all
for all 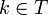 , because the definition of -disjunct. Hence we complete the proof.
, because the definition of -disjunct. Hence we complete the proof.
Then we have the following corollary.
Corollary We can detect  errors and correct
errors and correct 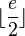 errors on the outcome of -disjunct matrix.
errors on the outcome of -disjunct matrix.
Upper bounds for non-adaptive group testing
The results for these upper bounds rely mostly on the properties of -disjunct matrices. Not only are the upper bounds nice, but from Lemma 1 we know that there is also a nice decoding algorithm for these bounds. First the following lemma will be proved since it is relied upon for both constructions:
Lemma 2: Given 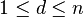 let be a matrix and:
let be a matrix and:
![\forall j \in [n] \text{, } |S_{M_j}| \geq w_\min](../I/m/3f0d8ca747d3c5be1f740f5e53e261bc.png)
![\forall i \neq j \in [n], |S_{M_i} \cap S_{M_j}| \leq a_\max](../I/m/19acd7a0f1862da99d7f500604bd2632.png)
for some integers 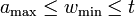 then is
then is 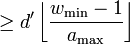 -disjunct.
-disjunct.
Note: these conditions are stronger than simply having a subset of size but rather applies to any pair of columns in a matrix. Therefore no matter what column that is chosen in the matrix, that column will contain at least 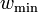 1's and the total number of shared 1's by any two columns is
1's and the total number of shared 1's by any two columns is 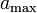 .
.
Proof of Lemma 2: Fix an arbitrary ![S \subseteq [n], |S| \leq d, j \notin S](../I/m/6b4d508910ac787464ddea662938d8e1.png) and a matrix . There exists a match between
and a matrix . There exists a match between 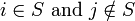 if column has a 1 in the same row position as in column . Then the total number of matches is
if column has a 1 in the same row position as in column . Then the total number of matches is 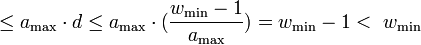 , i.e. a column has a fewer number of matches than the number of ones in it. Therefore there must be a row with all 0s in but a 1 in .
, i.e. a column has a fewer number of matches than the number of ones in it. Therefore there must be a row with all 0s in but a 1 in .
We will now generate constructions for the bounds.
Constructions can be either randomized (brute-force), explicit or strongly explicit. This concerns the time in which the incidence matrix can be generated. An explicit construction for a 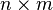 matrix has a complexity
matrix has a complexity 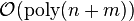 , whereas a randomized construction takes more than that. For a strongly explicit construction, one can find a single entry of the matrix in
, whereas a randomized construction takes more than that. For a strongly explicit construction, one can find a single entry of the matrix in 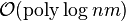 time.
time.
Randomized construction
This first construction will use a probabilistic argument to show the property wanted, in particular the Chernoff bound. Using this randomized construction gives that 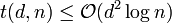 . The following lemma will give the result needed.
. The following lemma will give the result needed.
Theorem 1: There exists a random -disjunct matrix with 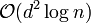 rows.
rows.
Proof of Theorem 1: Begin by building a random matrix with 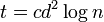 (where
(where  will be picked later). It will be shown that is
will be picked later). It will be shown that is 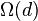 -disjunct. First note that
-disjunct. First note that 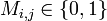 and let independently with probability
and let independently with probability  for
for ![i \in [t]](../I/m/bf0c5ce9970ef2a12460f33058a2332a.png) and . Now fix . Denote the column of as
and . Now fix . Denote the column of as ![T_j \subseteq [t]](../I/m/1f9e738de6c3635a7848b621de940196.png) . Then the expectancy is
. Then the expectancy is ![\mathbb{E}[|T_j|] = \frac{t}{d}](../I/m/a4c17eeb1fcd2509b3be9e691a1ba885.png) . Using the Chernoff bound, with
. Using the Chernoff bound, with 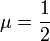 , gives
, gives ![\mathrm{Pr}[ |T_j| < \frac{t}{2d}] \leq e^{\frac{-t}{12d}} = e^{\frac{-cd\log n}{12}} \leq n^{-2d} [](../I/m/b92182e2fb4ac895a0afdf3366842d96.png) if
if ![c \geq 24 ]](../I/m/ae2d5d452435da08f02d2055fba91b31.png) . Taking the union bound over all columns gives
. Taking the union bound over all columns gives 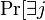 ,
, ![|T_j| < \frac{t}{2d}] \leq n \cdot n^{-2d} \leq n^{-d}](../I/m/946c8f9ad6fb91fcb1f17be0daf28318.png) . This gives
. This gives 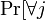 ,
, ![|T_j| \geq \frac{t}{2d}] \geq 1 - n^{-d}](../I/m/a5105001b03f5d67732b3131c862231b.png) . Therefore
. Therefore 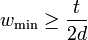 with probability
with probability 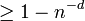 .
.
Now suppose ![j \neq k \in [n]](../I/m/14973932e66461aa04dfea8ade69ce5b.png) and then
and then ![\mathrm{Pr} [M_{i,j} = M_{i,k} = 1] = \frac{1}{d^2}](../I/m/0371b535cc19cc99e87b56c7a7b5579c.png) . So
. So ![\mathbb{E}[|T_j \cap T_k|] = \frac{t}{d^2}](../I/m/55f87af14afcc6af9a1fc3e8a24c8188.png) . Using the Chernoff bound on this gives
. Using the Chernoff bound on this gives ![\mathrm{Pr}[ |T_j \cap T_k| > \frac{2t}{d^2}] \leq e^{\frac{-t}{3d^2}} = e^{-2\log n} \leq n^{-4} [](../I/m/88489c0015fed253cd8937ba990fb54d.png) if
if ![c \geq 12 ]](../I/m/7b3e18a11fab1ef45383d04fa9734898.png) . By the union bound over
. By the union bound over 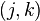 pairs
pairs 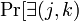 such that
such that ![|T_j \cap T_k| > \frac{2t}{d^2}] \leq n^2 \cdot n^{-4} = n^{-2}](../I/m/be2d4cd720dc99b5e427e61a04376ec5.png) . This gives that
. This gives that 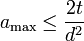 and with probability
and with probability 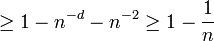 . Note that by changing the probability
. Note that by changing the probability 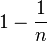 can be made to be
can be made to be 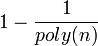 . Thus
. Thus 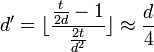 . By setting to be
. By setting to be 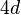 , the above argument shows that is -disjunct.
, the above argument shows that is -disjunct.
Note that in this proof 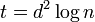 thus giving the upper bound of .
thus giving the upper bound of .
Strongly explicit construction
It is possible to prove a bound of 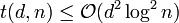 using a strongly explicit code. Although this bound is worse by a
using a strongly explicit code. Although this bound is worse by a 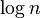 factor, it is preferable because this produces a strongly explicit construction instead of a randomized one.
factor, it is preferable because this produces a strongly explicit construction instead of a randomized one.
Theorem 2: There exists a strongly explicit -disjunct matrix with 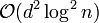 rows.
rows.
This proof will use the properties of concatenated codes along with the properties of disjunct matrices to construct a code that will satisfy the bound we are after.
Proof of Theorem 2:
Let 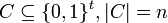 such that
such that 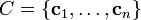 . Denote
. Denote 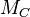 as the matrix with its
as the matrix with its 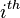 column being
column being 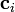 . If
. If 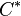 can be found such that
can be found such that
-
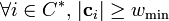
-
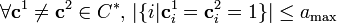 ,
,
then  is
is  -disjunct. To complete the proof another concept must be introduced. This concept uses code concatenation to obtain the result we want.
-disjunct. To complete the proof another concept must be introduced. This concept uses code concatenation to obtain the result we want.
Kautz-Singleton '64
Let 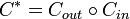 . Let
. Let 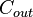 be a
be a ![[q,k]_q](../I/m/636ebf051904abd8a79f6e435cfe4991.png) -Reed–Solomon code. Let
-Reed–Solomon code. Let ![C_{in} = [q] \rightarrow \{0,1\}^q](../I/m/12c03e02a1b3e83f54a637f3d016a719.png) such that for
such that for ![i \in [q]](../I/m/2b9ddb8fab9bd9d5e479b3a6d76cd9a3.png) ,
, 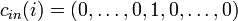 where the 1 is in the position. Then
where the 1 is in the position. Then 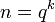 ,
, 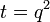 , and
, and 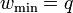 .
.
---
Example: Let 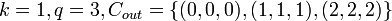 . Below, denotes the matrix of codewords for and denotes the matrix of codewords for , where each column is a codeword. The overall image shows the transition from the outer code to the concatenated code.
. Below, denotes the matrix of codewords for and denotes the matrix of codewords for , where each column is a codeword. The overall image shows the transition from the outer code to the concatenated code.
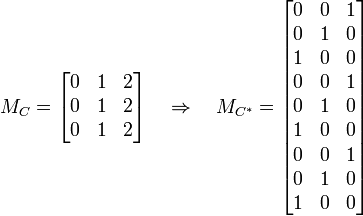
---
Divide the rows of into sets of size 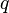 and number them as
and number them as ![(i,j) \in [q] \times [q]](../I/m/a66a27449a74ffd43f6f6f1deb519906.png) where indexes the set of rows and indexes the row in the set. If
where indexes the set of rows and indexes the row in the set. If 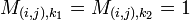 then note that
then note that 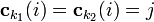 where
where 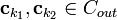 . So that means
. So that means 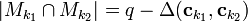 . Since
. Since 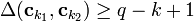 it gives that
it gives that 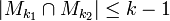 so let
so let 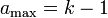 . Since , the entries in each column of can be looked at as sets of entries where only one of the entries is nonzero (by definition of
. Since , the entries in each column of can be looked at as sets of entries where only one of the entries is nonzero (by definition of 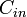 ) which gives a total of nonzero entries in each column. Therefore and
) which gives a total of nonzero entries in each column. Therefore and 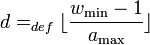 (so is -disjunct).
(so is -disjunct).
Now pick and 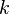 such that
such that 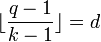 (so
(so 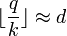 ). Since
). Since 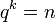 we have
we have 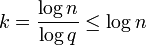 . Since
. Since 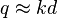 and it gives that
and it gives that 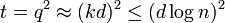 .
.
Thus we have a strongly explicit construction for a code that can be used to form a group testing matrix and so 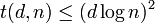 .
.
For non-adaptive testing we have shown that 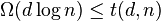 and we have that (i) (strongly explicit) and (ii) (randomized). As of recent work by Porat and Rothscheld, they presented an explicit method construction (i.e. deterministic time but not strongly explicit) for ,[1] however it is not shown here. There is also a lower bound for disjunct matrices of
and we have that (i) (strongly explicit) and (ii) (randomized). As of recent work by Porat and Rothscheld, they presented an explicit method construction (i.e. deterministic time but not strongly explicit) for ,[1] however it is not shown here. There is also a lower bound for disjunct matrices of 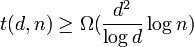 [2][3][4] which is not shown here either.
[2][3][4] which is not shown here either.
Examples
Here is the 2-disjunct matrix 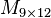 :
:
![M_{9 \times 12} = \left[
\begin{array}{cccccccccccc}
0 & 0 & 0 & 0 & 0 & 0 & 1 & 1 & 1 & 1 & 0 & 0 \\
0 & 0 & 0 & 1 & 1 & 1 & 0 & 0 & 0 & 1 & 0 & 0 \\
1 & 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0 \\
0 & 0 & 1 & 0 & 0 & 1 & 0 & 0 & 1 & 0 & 1 & 0 \\
0 & 1 & 0 & 0 & 1 & 0 & 0 & 1 & 0 & 0 & 1 & 0 \\
1 & 0 & 0 & 1 & 0 & 0 & 1 & 0 & 0 & 0 & 1 & 0 \\
0 & 1 & 0 & 1 & 0 & 0 & 0 & 0 & 1 & 0 & 0 & 1 \\
0 & 0 & 1 & 0 & 1 & 0 & 1 & 0 & 0 & 0 & 0 & 1 \\
1 & 0 & 0 & 0 & 0 & 1 & 0 & 1 & 0 & 0 & 0 & 1
\end{array}
\right]](../I/m/a39a0dd6688ce44f742a5593518270c1.png)
See also
- Group testing
- Concatenated code
- Compressed sensing
References
- ↑ Porat, E., & Rothschild, A. (2008). Explicit Non-adaptive Combinatorial Group Testing Schemes. In Proceedings of the 35th International Colloquium on Automata, Languages and Programming (ICALP) (pp. 748–759).
- ↑ Dýachkov, A. G., & Rykov, V. V. (1982). Bounds on the length of disjunctive codes. Problemy Peredachi Informatsii [Problems of Information Transmission], 18(3), 7–13.
- ↑ Dýachkov, A. G., Rashad, A. M., & Rykov, V. V. (1989). Superimposed distance codes. Problemy Upravlenija i Teorii Informacii [Problems of Control and Information Theory], 18(4), 237–250.
- ↑ Zoltan Furedi, On r-Cover-free Families, Journal of Combinatorial Theory, Series A, Volume 73, Issue 1, January 1996, Pages 172–173, ISSN 0097-3165, doi:10.1006/jcta.1996.0012. (http://www.sciencedirect.com/science/article/B6WHS-45NJMVF-39/2/172ef8c5c4aee2d85d1ddd56b107eef3)
Notes
- Atri Rudra's book on Error Correcting Codes: Combinatorics, Algorithms, and Applications (Spring 201), Chapter 17