Differential privacy
In cryptography, differential privacy aims to provide means to maximize the accuracy of queries from statistical databases while minimizing the chances of identifying its records.
Situation
Consider a trusted party that holds a dataset of sensitive information (e.g. medical records, voter registration information, email usage) with the goal of providing global, statistical information about the data publicly available, while preserving the privacy of the users whose information the data set contains. Such a system is called a statistical database. The notion of indistinguishability,[1] later termed Differential Privacy,[2] formalizes the notion of "privacy" in statistical databases.
ε-differential privacy
The actions of the trusted server are modeled via a randomized
algorithm  .
A randomized algorithm is
.
A randomized algorithm is
 -differentially private if for all datasets
-differentially private if for all datasets
 and
and
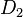 that differ on a single element (i.e., data of one person), and all
that differ on a single element (i.e., data of one person), and all
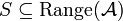 ,
,
![\Pr[\mathcal{A}(D_{1})\in S]\leq
e^{\epsilon}\times\Pr[\mathcal{A}(D_{2})\in S]\,\!](../I/m/15caef5ef69abbd9eaf52b3b9943448b.png)
where the probability is taken over the coins of the algorithm and  denotes the output range of the algorithm .
denotes the output range of the algorithm .
N.B.: Differential Privacy is a condition on the release mechanism and not on the dataset.
This means that for any two datasets which are close to one another (that is, which differ on a single element) a given differentially private algorithm will behave approximately the same on both data sets. The definition gives a strong guarantee that presence or absence of an individual will not affect the final output of the query significantly.
For example, assume we have a database of medical records where each record is a pair (Name,X), where 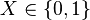 denotes whether a person has diabetes or not. For example:
denotes whether a person has diabetes or not. For example:
| Name | Has Diabetes (X) |
|---|---|
| Ross | 1 |
| Monica | 1 |
| Joey | 0 |
| Phoebe | 0 |
| Chandler | 1 |
Now suppose a malicious user (often termed an adversary) wants to find whether Chandler has diabetes or not. As a side information he knows in which row of the database Chandler resides. Now suppose the adversary is only allowed to use a particular form of query 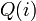 which returns the partial sum of first
which returns the partial sum of first 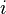 rows of column
rows of column  in the database. In order to find Chandler's diabetes status the adversary simply executes
in the database. In order to find Chandler's diabetes status the adversary simply executes 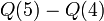 . One striking feature this example highlights is: individual information can be compromised even without explicitly querying for the specific individual information.
. One striking feature this example highlights is: individual information can be compromised even without explicitly querying for the specific individual information.
Let us take this example a little further. Now we construct
by replacing (Chandler,1) with (Chandler,0). Let us
call the release mechanism (which releases the output of
) . We say
is -differentially
private if it satisfies the definition, where  can be thought of as a singleton
set (something like
can be thought of as a singleton
set (something like 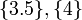 etc.) if the output
function of is a Discrete Random Variable
(i.e. has a probability mass function (pmf)); else if it is a
Continuous Random Variable (i.e. has a probability density function (pdf)), then can be thought to be a small
range of reals (something like
etc.) if the output
function of is a Discrete Random Variable
(i.e. has a probability mass function (pmf)); else if it is a
Continuous Random Variable (i.e. has a probability density function (pdf)), then can be thought to be a small
range of reals (something like
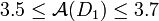 ).
).
In essence if such an exists then a particular
individual's presence or absence in the database will not alter the
distribution of the output of the query by a significant amount and
thus assures privacy of individual information in an information
theoretic sense.
Sensitivity
Getting back on the main stream discussion on Differential Privacy,
the sensitivity [1] ( ) of a function
) of a function  is
is

for all  ,
, differing in at most one element, and
differing in at most one element, and 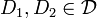 .
.
To get more intuition into this let us return to the example of the medical database and a query (which can also be seen as the function  ) to find how many people in the first rows of the database have diabetes. Clearly, if we change one of the entries in the database then the output of the query will change by at most one. So, the sensitivity of this query is one. It so happens that there are techniques (which are described below) using which we can create a differentially private algorithm for functions with low sensitivity.
) to find how many people in the first rows of the database have diabetes. Clearly, if we change one of the entries in the database then the output of the query will change by at most one. So, the sensitivity of this query is one. It so happens that there are techniques (which are described below) using which we can create a differentially private algorithm for functions with low sensitivity.
Trade-off between utility and privacy
A trade-off between the accuracy of the statistics estimated in a privacy-preserving manner, and the privacy parameter ε. This trade-off is studied in,[3][4][5] and [6]
Motivation
In the past, various ad-hoc approaches to anonymizing public records have failed when researchers managed to identify personal information by linking two or more separately innocuous databases. Two well-known instances of successful "Linkage Attacks" have been the Netflix Database and the Massachusetts Group Insurance Commission (GIC) medical encounter database.
Netflix Prize
Netflix has offered $1,000,000 prize for a 10% improvement in its recommendation system. Netflix has also released a training dataset for the competing developers to train their systems. While releasing this dataset they had provided a disclaimer: To protect customer privacy, all personal information identifying individual customers has been removed and all customer ids have been replaced by randomly assigned ids. Netflix is not the only available movie rating portal on the web; there are many others, including IMDB. On IMDB individuals can register and rate movies and they have the option of not keeping their details anonymous. Arvind Narayanan and Vitaly Shmatikov, researchers at The University of Texas at Austin, linked the Netflix anonymized training database with the IMDB database (using the date of rating by a user) to partially de-anonymize the Netflix training database, compromising the identity of a user.[7] .
Massachusetts Group Insurance Commission (GIC) medical encounter database
Latanya Sweeney from Carnegie Mellon University linked the anonymized GIC database (which retained the birthdate, sex, and ZIP code of each patient) with voter registration records, and was able to identify the medical record of the governor of Massachusetts.[2]
Metadata and Mobility databases
De Montjoye et al. from MIT introduced the notion of unicity and showed that 4 spatio-temporal points, approximate places and times, are enough to uniquely identify 95% of 1.5M people in a mobility database.[8][9] The study further shows that these constraints hold even when the resolution of the dataset is low meaning that even coarse or blurred mobility datasets and metadata provide little anonymity.
Laplace noise
Many differentially private algorithms rely on adding controlled noise[1] to functions with low sensitivity. We will elaborate this point by taking a special kind of noise (whose kernel is a Laplace distribution i.e. the probability density function  , mean zero and standard deviation
, mean zero and standard deviation 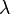 ). Now in our case we define the output function of as a real valued function (called as the transcript output by )
). Now in our case we define the output function of as a real valued function (called as the transcript output by )  , where
, where 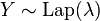 and is the original real valued query/function we plan to execute on the database. Now clearly
and is the original real valued query/function we plan to execute on the database. Now clearly  can be considered to be a continuous random variable, where
can be considered to be a continuous random variable, where

which is at most  . We can consider
. We can consider  to be the privacy factor . Thus
to be the privacy factor . Thus  follows a differentially private mechanism (as can be seen from the definition). If we try to use this concept in our diabetes example then it follows from the above derived fact that in order to have as the -differential private algorithm we need to have
follows a differentially private mechanism (as can be seen from the definition). If we try to use this concept in our diabetes example then it follows from the above derived fact that in order to have as the -differential private algorithm we need to have 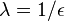 .
Though we have used Laplacian noise here but we can use other forms of noises which also allows to create a differentially private mechanism, such as the Gaussian Noise (where of course a slight relaxation of the definition of differential privacy [2] is needed).
.
Though we have used Laplacian noise here but we can use other forms of noises which also allows to create a differentially private mechanism, such as the Gaussian Noise (where of course a slight relaxation of the definition of differential privacy [2] is needed).
Composability
Sequential composition [10]
If we query an ε-differential privacy mechanism 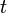 times, and the randomization of the mechanism is independent for each query, then the result would be
times, and the randomization of the mechanism is independent for each query, then the result would be 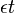 -differentially private. In the more general case, if there are
-differentially private. In the more general case, if there are  independent mechanisms:
independent mechanisms: 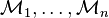 , whose privacy guarantees are
, whose privacy guarantees are 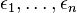 differential privacy, respectively, then any function
differential privacy, respectively, then any function 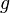 of them:
of them:  is
is  -differentially private.
-differentially private.
Parallel composition [10]
Furthermore, if the previous mechanisms are computed on disjoint subsets of the private database then the function would be  -differentially private instead.
-differentially private instead.
Group privacy
In general, ε-differential privacy is designed to protect the privacy between neighboring databases which differ only in one row. This means that no adversary with arbitrary auxiliary information can know if one particular participant submitted his information. However this is also extendable if we want to protect databases differing in  rows, which amounts to adversary with arbitrary auxiliary information can know if particular participants submitted their information. This can be achieved because if items change, the probability dilation is bounded by
rows, which amounts to adversary with arbitrary auxiliary information can know if particular participants submitted their information. This can be achieved because if items change, the probability dilation is bounded by 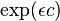 instead of
instead of 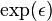 ,[2] i.e. for D1 and D2 differing on items:
,[2] i.e. for D1 and D2 differing on items:
![\Pr[\mathcal{A}(D_{1})\in S]\leq
\exp(\epsilon c)\times\Pr[\mathcal{A}(D_{2})\in S]\,\!](../I/m/ee0c032bf7cc7a26534c39689f942205.png)
Thus setting ε instead to 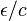 achieves the desired result (protection of items). In other words, instead of having each item ε-differentially private protected, now every group of items is ε-differentially private protected (and each item is
achieves the desired result (protection of items). In other words, instead of having each item ε-differentially private protected, now every group of items is ε-differentially private protected (and each item is  -differentially private protected).
-differentially private protected).
Proof idea
For three datasets D1, D2, and D3, such that D1 and D2 differ on one item, and D2 and D3 differ on one item (implicitly D1 and D3 differ on at most 2 items), the following holds for an ε-differentially private mechanism 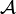 :
:
![\Pr[\mathcal{A}(D_{1})\in S] \leq \exp(\epsilon)\times\Pr[\mathcal{A}(D_{2})\in S]\,\!](../I/m/6d817057e5226ca2e79abb4968d39ac1.png) ,
and
,
and
![\Pr[\mathcal{A}(D_{2})\in S] \leq \exp(\epsilon)\times\Pr[\mathcal{A}(D_{3})\in S]\,\!](../I/m/53a588e63982a301498625e624ed1ae9.png)
hence:
![\Pr[\mathcal{A}(D_{1})\in S] \leq \exp(\epsilon)\times ( \exp(\epsilon)\times\Pr[\mathcal{A}(D_{3})\in S]) = \exp(2 \epsilon)\times\Pr[\mathcal{A}(D_{3})\in S] \,\!](../I/m/a59ae709de43f151b8cca6f0c5b7437d.png)
The proof can be extended to instead of 2.
Stable transformations
A transformation 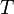 is -stable if the hamming distance between
is -stable if the hamming distance between  and
and 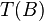 is at most -times the hamming distance between
is at most -times the hamming distance between 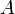 and
and 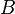 for any two databases
for any two databases 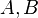 . Theorem 2 in [10] asserts that if there is a mechanism
. Theorem 2 in [10] asserts that if there is a mechanism 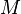 that is
that is  -differentially private, then the composite mechanism
-differentially private, then the composite mechanism  is
is  -differentially private.
-differentially private.
This could be generalized to group privacy, as the group size could be thought of as the hamming distance 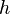 between
and (where contains the group and doesn't). In this case is
between
and (where contains the group and doesn't). In this case is  -differentially private.
-differentially private.
See also
- Quasi-identifier
- Exponential mechanism (differential privacy) – a technique for designing differentially private algorithms
- k-anonymity
Notes
- ↑ 1.0 1.1 1.2 Dwork, McSherry, Nissim and Smith, 2006.
- ↑ 2.0 2.1 2.2 2.3 Dwork, ICALP 2006.
- ↑ A. Ghosh, T. Roughgarden, and M. Sundararajan. Universally utility-maximizing privacy mechanisms. In Proceedings of the 41st annual ACM Symposium on Theory of Computing, pages 351–360. ACM New York, NY, USA, 2009.
- ↑ H. Brenner and K. Nissim. Impossibility of Differentially Private Universally Optimal Mechanisms. In Proceedings of the 51st Annual IEEE Symposium on Foundations of Computer Science (FOCS), 2010.
- ↑ R. Chen, N. Mohammed, B. C. M. Fung, B. C. Desai, and L. Xiong. Publishing set-valued data via differential privacy. The Proceedings of the VLDB Endowment (PVLDB), 4(11):1087-1098, August 2011. VLDB Endowment.
- ↑ N. Mohammed, R. Chen, B. C. M. Fung, and P. S. Yu. Differentially private data release for data mining. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (SIGKDD), pages 493-501, San Diego, CA: ACM Press, August 2011.
- ↑ Arvind Narayanan, Vitaly Shmatikov (2008). Robust De-anonymization of Large Sparse Datasets (PDF). IEEE Symposium on Security and Privacy. pp. 111–125.
- ↑ de Montjoye, Yves-Alexandre; César A. Hidalgo; Michel Verleysen; Vincent D. Blondel (March 25, 2013). "Unique in the Crowd: The privacy bounds of human mobility". Nature srep. doi:10.1038/srep01376. Retrieved 12 April 2013.
- ↑ Palmer, Jason (March 25, 2013). "Mobile location data 'present anonymity risk'". BBC News. Retrieved 12 April 2013.
- ↑ 10.0 10.1 10.2 McSherry, SIGMOD 2009 (Theorem 3 and 4).
References
- The Algorithmic Foundations of Differential Privacy by Cynthia Dwork and Aaron Roth. Foundations and Trends in Theoretical Computer Science. Vol. 9, no. 3–4, pp. 211‐407, Aug. 2014. DOI=10.1561/0400000042
- Calibrating Noise to Sensitivity in Private Data Analysis by Cynthia Dwork, Frank McSherry, Kobbi Nissim, Adam Smith In Theory of Cryptography Conference (TCC), Springer, 2006.
- Differential Privacy by Cynthia Dwork, International Colloquium on Automata, Languages and Programming (ICALP) 2006, p. 1–12.
- Frank D. McSherry. 2009. Privacy integrated queries: an extensible platform for privacy-preserving data analysis. In Proceedings of the 35th SIGMOD international conference on Management of data (SIGMOD '09), Carsten Binnig and Benoit Dageville (Eds.). ACM, New York, NY, USA, 19-30. DOI= 10.1145/1559845.1559850
External links
- The Algorithmic Foundations of Differential Privacy by Cynthia Dwork and Aaron Roth, 2014.
- Differential Privacy: A Survey of Results by Cynthia Dwork, Microsoft Research April 2008
- Privacy of Dynamic Data: Continual Observation and Pan Privacy by Moni Naor, Institute for Advanced Study November 2009
- Tutorial on Differential Privacy by Katrina Ligett, California Institute of Technology, December 2013
- A Practical Beginner's Guide To Differential Privacy by Christine Task, Purdue University April 2012
- Private Map Maker v0.2 on the Common Data Project blog