Deviance information criterion
The deviance information criterion (DIC) is a hierarchical modeling generalization of the AIC (Akaike information criterion) and BIC (Bayesian information criterion, also known as the Schwarz criterion). It is particularly useful in Bayesian model selection problems where the posterior distributions of the models have been obtained by Markov chain Monte Carlo (MCMC) simulation. Like AIC and BIC it is an asymptotic approximation as the sample size becomes large. It is only valid when the posterior distribution is approximately multivariate normal.
Define the deviance as 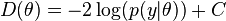 , where
, where 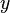 are the data,
are the data, 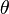 are the unknown parameters of the model and
are the unknown parameters of the model and 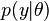 is the likelihood function.
is the likelihood function. 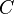 is a constant that cancels out in all calculations that compare different models, and which therefore does not need to be known.
is a constant that cancels out in all calculations that compare different models, and which therefore does not need to be known.
The expectation ![\bar{D}=\mathbf{E}^\theta[D(\theta)]](../I/m/02ee665a387396bfde51f042fa23a56f.png) is a measure of how well the model fits the data; the larger this is, the worse the fit.
is a measure of how well the model fits the data; the larger this is, the worse the fit.
There are two calculations in common usage for the effective number of parameters of the model. The first, as described in Spiegelhalter et al. (2002, p. 587) is 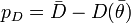 , where
, where 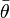 is the expectation of . The second, as described in Gelman et al. (2004, p. 182) is
is the expectation of . The second, as described in Gelman et al. (2004, p. 182) is  . The larger the effective number of parameters is, the easier it is for the model to fit the data, and so the deviance needs to be penalized.
. The larger the effective number of parameters is, the easier it is for the model to fit the data, and so the deviance needs to be penalized.
The deviance information criterion is calculated as

or equivalently as
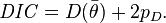
From this later form, the connection with Akaike's information criterion is evident.
The idea is that models with smaller DIC should be preferred to models with larger DIC. Models are penalized both by the value of  , which favors a good fit, but also (in common with AIC and BIC) by the effective number of parameters
, which favors a good fit, but also (in common with AIC and BIC) by the effective number of parameters 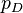 . Since
. Since  will decrease as the number of parameters in a model increases, the term compensates for this effect by favoring models with a smaller number of parameters.
will decrease as the number of parameters in a model increases, the term compensates for this effect by favoring models with a smaller number of parameters.
The advantage of DIC over other criteria in the case of Bayesian model selection is that the DIC is easily calculated from the samples generated by a Markov chain Monte Carlo simulation. AIC and BIC require calculating the likelihood at its maximum over , which is not readily available from the MCMC simulation. But to calculate DIC, simply compute as the average of 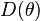 over the samples of , and
over the samples of , and  as the value of
as the value of 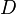 evaluated at the average of the samples of . Then the DIC follows directly from these approximations. Claeskens and Hjort (2008, Ch. 3.5) show that the DIC is large-sample equivalent to the natural model-robust version of the AIC.
evaluated at the average of the samples of . Then the DIC follows directly from these approximations. Claeskens and Hjort (2008, Ch. 3.5) show that the DIC is large-sample equivalent to the natural model-robust version of the AIC.
In the derivation of DIC, it is assumed that the specified parametric family of probability distributions that generate future observations encompasses the true model. This assumption does not always hold, and it is desirable to consider model assessment procedures in that scenario. Also, the observed data are used both to construct the posterior distribution and to evaluate the estimated models. Therefore, DIC tends to select over-fitted models. Recently, these issues are resolved by Ando (2007), Bayesian predictive information criterion, BPIC. Ando (2010, Ch. 8) provided a discussion of various Bayesian model selection cariteria. To avoid the over-fitting problems of DIC, Ando (2011) developed Bayesian model selection criteria from a predictive view point. The criterion is calculated as
![\mathit{IC} =\bar{D}+2p_D=-2\mathbf{E}^\theta[ \log(p(y|\theta))]+2p_D.](../I/m/e201abaf0407e5fd549729a4e17fa6c5.png)
The first term is a measure of how well the model fits the data, while the second term is a penalty on the model complexity. Note, that the p in this expression is the predictive distribution rather than the likelihood above.
See also
- Akaike information criterion (AIC)
- Bayesian information criterion (BIC)
- Bayesian predictive information criterion (BPIC)
- Focused information criterion (FIC)
- Hannan-Quinn information criterion
- Kullback–Leibler divergence
- Jensen–Shannon divergence
References
- Ando, Tomohiro (2007). "Bayesian predictive information criterion for the evaluation of hierarchical Bayesian and empirical Bayes models". Biometrika 94 (2): 443–458. doi:10.1093/biomet/asm017.
- Ando, T. (2010). Bayesian Model Selection and Statistical Modeling, CRC Press. Chapter 7.
- Ando, Tomohiro (2011). "Predictive Bayesian Model Selection". American Journal of Mathematical and Management Sciences 31 (1-2): 13–38. doi:10.1080/01966324.2011.10737798.
- Claeskens, G, and Hjort, N.L. (2008). Model Selection and Model Averaging, Cambridge. Section 3.5.
- Gelman, Andrew; Carlin, John B.; Stern, Hal S.; Rubin, Donald B. (2004). Bayesian Data Analysis: Second Edition. Texts in Statistical Science. CRC Press. ISBN 1-58488-388-X. LCCN 2003051474. MR 2027492.
- van der Linde, A. (2005). "DIC in variable selection", Statistica Neerlandica, 59: 45-56. doi:10.1111/j.1467-9574.2005.00278.x
- Spiegelhalter, David J.; Best, Nicola G.; Carlin, Bradley P.; van der Linde, Angelika (2002). "Bayesian measures of model complexity and fit (with discussion)". Journal of the Royal Statistical Society, Series B 64 (4): 583–639. doi:10.1111/1467-9868.00353. JSTOR 3088806. MR 1979380.
- Spiegelhalter, David J.; Best, Nicola G.; Carlin, Bradley P.; van der Linde, Angelika (2014). "The deviance information criterion: 12 years on (with discussion)". Journal of the Royal Statistical Society, Series B 76 (3): 485–493.