Deep belief network
| Machine learning and data mining |
|---|
 |
| Problems |
| Clustering |
|
| Dimensionality reduction |
| Structured prediction |
| Anomaly detection |
|
| Neural nets |
| Theory |
|
|
In machine learning, a deep belief network (DBN) is a generative graphical model, or alternatively a type of deep neural network, composed of multiple layers of latent variables ("hidden units"), with connections between the layers but not between units within each layer.[1]
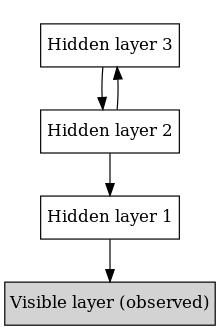
When trained on a set of examples in an unsupervised way, a DBN can learn to probabilistically reconstruct its inputs. The layers then act as feature detectors on inputs.[1] After this learning step, a DBN can be further trained in a supervised way to perform classification.[2]
DBNs can be viewed as a composition of simple, unsupervised networks such as restricted Boltzmann machines (RBMs)[1] or autoencoders,[3] where each sub-network's hidden layer serves as the visible layer for the next. This also leads to a fast, layer-by-layer unsupervised training procedure, where contrastive divergence is applied to each sub-network in turn, starting from the "lowest" pair of layers (the lowest visible layer being a training set).
The observation, due to Geoffrey Hinton's student Yee-Whye Teh,[2] that DBNs can be trained greedily, one layer at a time, has been called a breakthrough in deep learning.[4]:6
Training algorithm
The training algorithm for DBNs proceeds as follows. Let X be a matrix of inputs, regarded as a set of feature vectors.[2]
- Train a restricted Boltzmann machine on X to obtain its weight matrix, W. Use this as the weight matrix for between the lower two layers of the network.
- Transform X by the RBM to produce new data X', either by sampling or by computing the mean activation of the hidden units.
- Repeat this procedure with X ← X' for the next pair of layers, until the top two layers of the network are reached.
See also
References
- ↑ 1.0 1.1 1.2 Hinton, G. (2009). "Deep belief networks". Scholarpedia 4 (5): 5947. doi:10.4249/scholarpedia.5947.
- ↑ 2.0 2.1 2.2 Hinton, G. E.; Osindero, S.; Teh, Y. W. (2006). "A Fast Learning Algorithm for Deep Belief Nets". Neural Computation 18 (7): 1527–1554. doi:10.1162/neco.2006.18.7.1527. PMID 16764513.
- ↑ Yoshua Bengio; Pascal Lamblin; Dan Popovici; Hugh Larochelle (2007). Greedy Layer-Wise Training of Deep Networks. NIPS.
- ↑ Bengio, Y. (2009). "Learning Deep Architectures for AI". Foundations and Trends in Machine Learning 2. doi:10.1561/2200000006.
External links
- "Deep Belief Networks". Deep Learning Tutorials.
- "Deep Belief Network Example". Deeplearning4j Tutorials.