Context-free language
In formal language theory, a context-free language (CFL) is a language generated by some context-free grammar (CFG). Different CF grammars can generate the same CF language. It is important to distinguish properties of the language (intrinsic properties) from properties of a particular grammar (extrinsic properties).
The set of all context-free languages is identical to the set of languages accepted by pushdown automata, which makes these languages amenable to parsing. Indeed, given a CFG, there is a direct way to produce a pushdown automaton for the grammar (and corresponding language), though going the other way (producing a grammar given an automaton) is not as direct.
Context-free languages have many applications in programming languages; for example, the language of all properly matched parentheses is generated by the grammar 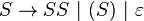 . Also, most arithmetic expressions are generated by context-free grammars.
. Also, most arithmetic expressions are generated by context-free grammars.
Examples
An archetypal context-free language is 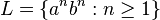 , the language of all non-empty even-length strings, the entire first halves of which are
, the language of all non-empty even-length strings, the entire first halves of which are 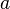 's, and the entire second halves of which are
's, and the entire second halves of which are 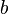 's.
's. 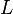 is generated by the grammar
is generated by the grammar 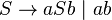 .
This language is not regular.
It is accepted by the pushdown automaton
.
This language is not regular.
It is accepted by the pushdown automaton 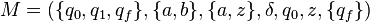 where
where 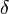 is defined as follows:[note 1]
is defined as follows:[note 1]
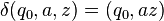
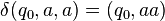
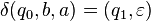
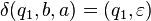
Unambiguous CFLs are a proper subset of all CFLs: there are inherently ambiguous CFLs. An example of an inherently ambiguous CFL is the union of 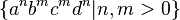 with
with 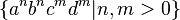 . This set is context-free, since the union of two context-free languages is always context-free. But there is no way to unambiguously parse strings in the (non-context-free) subset
. This set is context-free, since the union of two context-free languages is always context-free. But there is no way to unambiguously parse strings in the (non-context-free) subset 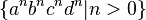 which is the intersection of these two languages.[1]
which is the intersection of these two languages.[1]
Languages that are not context-free
The set is a context-sensitive language, but there does not exist a context-free grammar generating this language.[2] So there exist context-sensitive languages which are not context-free. To prove that a given language is not context-free, one may employ the pumping lemma for context-free languages[3] or a number of other methods, such as Ogden's lemma or Parikh's theorem.[4]
Closure properties
Context-free languages are closed under the following operations. That is, if L and P are context-free languages, the following languages are context-free as well:
- the union
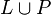 of L and P
of L and P - the reversal of L
- the concatenation
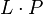 of L and P
of L and P - the Kleene star
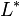 of L
of L - the image
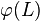 of L under a homomorphism
of L under a homomorphism 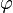
- the image
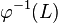 of L under an inverse homomorphism
of L under an inverse homomorphism 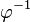
- the cyclic shift of L (the language
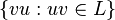 )
)
Context-free languages are not closed under complement, intersection, or difference. However, if L is a context-free language and D is a regular language then both their intersection 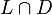 and their difference
and their difference 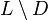 are context-free languages.
are context-free languages.
Nonclosure under intersection, complement, and difference
The context-free languages are not closed under intersection. This can be seen by taking the languages 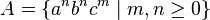 and
and 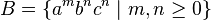 , which are both context-free.[note 2] Their intersection is
, which are both context-free.[note 2] Their intersection is 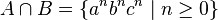 , which can be shown to be non-context-free by the pumping lemma for context-free languages.
, which can be shown to be non-context-free by the pumping lemma for context-free languages.
Context-free languages are also not closed under complementation, as for any languages A and B: 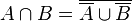 .
.
Context-free language are also not closed under difference: LC = Σ* \ L
Decidability properties
The following problems are undecidable for arbitrary context-free grammars A and B:
- Equivalence: Given two context-free grammars A and B, is
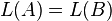 ?
? - Intersection Emptiness: Given two context-free grammars A and B, is
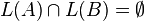 ? However, the intersection of a context-free language and a regular language is context-free,[5] and the variant of the problem where B is a regular grammar is decidable.
? However, the intersection of a context-free language and a regular language is context-free,[5] and the variant of the problem where B is a regular grammar is decidable. - Containment: Given a context-free grammar A, is
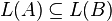 ? Again, the variant of the problem where B is a regular grammar is decidable.
? Again, the variant of the problem where B is a regular grammar is decidable. - Universality: Given a context-free grammar A, is
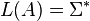 ?
?
The following problems are decidable for arbitrary context-free languages:
- Emptiness: Given a context-free grammar A, is
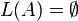 ?
? - Finiteness: Given a context-free grammar A, is
 finite?
finite? - Membership: Given a context-free grammar G, and a word
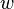 , does
, does 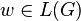 ? Efficient polynomial-time algorithms for the membership problem are the CYK algorithm and Earley's Algorithm.
? Efficient polynomial-time algorithms for the membership problem are the CYK algorithm and Earley's Algorithm.
According to Hopcroft, Motwani, Ullman (2003),[6] many of the fundamental closure and (un)decidability properties of context-free languages were shown in the 1961 paper of Bar-Hillel, Perles, and Shamir[3]
Parsing
Determining an instance of the membership problem; i.e. given a string , determine whether where is the language generated by a given grammar 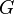 ; is also known as recognition. Context-free recognition for Chomsky normal form grammars was shown by Leslie G. Valiant to be reducible to boolean matrix multiplication, thus inheriting its complexity upper bound of O(n2.3728639).[7][8][note 3]
Conversely, Lillian Lee has shown O(n3-ε) boolean matrix multiplication to be reducible to O(n3-3ε) CFG parsing, thus establishing some kind of lower bound for the latter.[9]
; is also known as recognition. Context-free recognition for Chomsky normal form grammars was shown by Leslie G. Valiant to be reducible to boolean matrix multiplication, thus inheriting its complexity upper bound of O(n2.3728639).[7][8][note 3]
Conversely, Lillian Lee has shown O(n3-ε) boolean matrix multiplication to be reducible to O(n3-3ε) CFG parsing, thus establishing some kind of lower bound for the latter.[9]
Practical uses of context-free languages require also to produce a derivation tree that exhibits the structure that the grammar associates with the given string. The process of producing this tree is called parsing. Known parsers have a time complexity that is cubic in the size of the string that is parsed.
Formally, the set of all context-free languages is identical to the set of languages accepted by pushdown automata (PDA). Parser algorithms for context-free languages include the CYK algorithm and the Earley's Algorithm.
A special subclass of context-free languages are the deterministic context-free languages which are defined as the set of languages accepted by a deterministic pushdown automaton and can be parsed by a LR(k) parser.[10]
See also parsing expression grammar as an alternative approach to grammar and parser.
See also
Notes
- ↑ meaning of 's arguments and results:
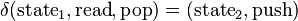
- ↑ A context-free grammar for the language A is given by the following production rules, taking S as the start symbol: S → Sc | aTb | ε; T → aTb | ε. The grammar for B is analogous.
- ↑ In Valiant's papers, O(n2.81) given, the then best known upper bound. See Matrix multiplication#Algorithms for efficient matrix multiplication and Coppersmith–Winograd algorithm for bound improvements since then.
References
- ↑ Hopcroft & Ullman 1979, p. 100, Theorem 4.7.
- ↑ Hopcroft & Ullman 1979.
- ↑ 3.0 3.1 Yehoshua Bar-Hillel, Micha Asher Perles, Eli Shamir (1961). "On Formal Properties of Simple Phrase-Structure Grammars". Zeitschrift für Phonetik, Sprachwissenschaft und Kommunikationsforschung 14 (2): 143–172.
- ↑ How to prove that a language is not context-free?
- ↑ Salomaa (1973), p. 59, Theorem 6.7
- ↑ John E. Hopcroft, Rajeev Motwani, Jeffrey D. Ullman (2003). Introduction to Automata Theory, Languages, and Computation. Addison Wesley. Here: Sect.7.6, p.304, and Sect.9.7, p.411
- ↑ Leslie Valiant (Jan 1974). General context-free recognition in less than cubic time (Technical report). Carnegie Mellon University. p. 11.
- ↑ Leslie G. Valiant (1975). "General context-free recognition in less than cubic time". Journal of Computer and System Sciences 10 (2): 308–315. doi:10.1016/s0022-0000(75)80046-8.
- ↑ Lillian Lee (2002). "Fast Context-Free Grammar Parsing Requires Fast Boolean Matrix Multiplication" (PDF). JACM 49 (1): 1–15. doi:10.1145/505241.505242.
- ↑ Knuth, D. E. (July 1965). "On the translation of languages from left to right" (PDF). Information and Control 8 (6): 607–639. doi:10.1016/S0019-9958(65)90426-2. Retrieved 29 May 2011.
- Seymour Ginsburg (1966). The Mathematical Theory of Context-Free Languages. New York, NY, USA: McGraw-Hill, Inc.
- Hopcroft, John E.; Ullman, Jeffrey D. (1979). Introduction to Automata Theory, Languages, and Computation (1st ed.). Addison-Wesley.
- Arto Salomaa (1973). Formal Languages. ACM Monograph Series.
- Michael Sipser (1997). Introduction to the Theory of Computation. PWS Publishing. ISBN 0-534-94728-X. Chapter 2: Context-Free Languages, pp. 91–122.
- Jean-Michel Autebert, Jean Berstel, Luc Boasson, Context-Free Languages and Push-Down Automata, in: G. Rozenberg, A. Salomaa (eds.), Handbook of Formal Languages, Vol. 1, Springer-Verlag, 1997, 111-174.
| |||||||||||||||||||