Consistent hashing
Consistent hashing is a special kind of hashing such that when a hash table is resized and consistent hashing is used, only 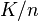 keys need to be remapped on average, where
keys need to be remapped on average, where 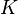 is the number of keys, and
is the number of keys, and  is the number of slots. In contrast, in most traditional hash tables, a change in the number of array slots causes nearly all keys to be remapped.
is the number of slots. In contrast, in most traditional hash tables, a change in the number of array slots causes nearly all keys to be remapped.
Consistent hashing achieves some of the same goals as Rendezvous hashing (also called HRW Hashing). The two techniques use different algorithms, and were devised independently and contemporaneously.
History
Originally devised by Karger et al. at MIT for use in distributed caching, the idea has now been expanded to other areas also.
An academic paper from 1997 introduced the term "consistent hashing" as a way of distributing requests among a changing population of Web servers. Each slot is then represented by a node in a distributed system. The addition (joins) and removal (leaves/failures) of nodes only requires items to be re-shuffled when the number of slots/nodes change.[1]
Consistent hashing has also been used to reduce the impact of partial system failures in large Web applications as to allow for robust caches without incurring the system wide fallout of a failure.[2]
The consistent hashing concept also applies to the design of distributed hash tables (DHTs). DHTs use consistent hashing to partition a keyspace among a distributed set of nodes, and additionally provide an overlay network that connects nodes such that the node responsible for any key can be efficiently located.
Rendezvous hashing, designed at the same time as consistent hashing, achieves the same goals using the very different Highest Random Weight (HRW) algorithm.
Need for consistent hashing
While running collections of caching machines some limitations are experienced. A common way of load balancing cache machines is to put object 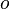 in cache machine number
in cache machine number 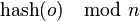 . But this will not work if a cache machine is added or removed because changes and every object is hashed to a new location. This can be disastrous since the originating content servers are flooded with requests from the cache machines. Hence consistent hashing is needed to avoid swamping of servers.
. But this will not work if a cache machine is added or removed because changes and every object is hashed to a new location. This can be disastrous since the originating content servers are flooded with requests from the cache machines. Hence consistent hashing is needed to avoid swamping of servers.
Consistent hashing maps objects to the same cache machine, as far as possible. It means when a cache machine is added, it takes its share of objects from all the other cache machines and when it is removed, its objects are shared between the remaining machines.
The main idea behind the consistent hashing algorithm is to associate each cache with one or more hash value intervals where the interval boundaries are determined by calculating the hash of each cache identifier. (The hash function used to define the intervals does not have to be the same function used to hash the cached values. Only the range of the two functions need match.) If the cache is removed its interval is taken over by a cache with an adjacent interval. All the remaining caches are unchanged.
Technique
Consistent hashing is based on mapping each object to a point on the edge of a circle (or equivalently, mapping each object to a real angle). The system maps each available machine (or other storage bucket) to many pseudo-randomly distributed points on the edge of the same circle.
To find where an object should be placed, the system finds the location of that object's key on the edge of the circle; then walks around the circle until falling into the first bucket it encounters (or equivalently, the first available bucket with a higher angle). The result is that each bucket contains all the resources located between its point and the previous bucket point.
If a bucket becomes unavailable (for example because the computer it resides on is not reachable), then the angles it maps to will be removed. Requests for resources that would have mapped to each of those points now map to the next highest point. Since each bucket is associated with many pseudo-randomly distributed points, the resources that were held by that bucket will now map to many different buckets. The items that mapped to the lost bucket must be redistributed among the remaining ones, but values mapping to other buckets will still do so and do not need to be moved.
A similar process occurs when a bucket is added. By adding a bucket point, we make any resources between that and the next smaller angle map to the new bucket. These resources will no longer be associated with the previous bucket, and any value previously stored there will not be found by the selection method described above.
The portion of the keys associated with each bucket can be altered by altering the number of angles that bucket maps to.
Monotonic keys
If it is known that key values will always increase monotonically, an alternative approach to consistent hashing is possible.
Properties
David Karger et al. list several properties of consistent hashing that make it useful for distributed caching protocols on the Internet:[1]
- "spread"
- "load"
- "smoothness"
- "balance"
- "monotonicity"
Examples of use
Some known instances where consistent hashing is used are:
- Openstack's Object Storage Service Swift[3]
- Partitioning component of Amazon's storage system Dynamo[4][5]
- Data partitioning in Apache Cassandra[6]
- Data Partitioning in Voldemort[7]
- Akka's consistent hashing router[8]
- Riak, a distributed key-value database[9]
- GlusterFS, a network-attached storage file system[10]
- Skylable, an open-source distributed object-storage system [11]
References
- ↑ 1.0 1.1 Karger, D.; Lehman, E.; Leighton, T.; Panigrahy, R.; Levine, M.; Lewin, D. (1997). Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web. Proceedings of the Twenty-ninth Annual ACM Symposium on Theory of Computing. ACM Press New York, NY, USA. pp. 654–663. doi:10.1145/258533.258660.
- ↑ Karger, D.; Sherman, A.; Berkheimer, A.; Bogstad, B.; Dhanidina, R.; Iwamoto, K.; Kim, B.; Matkins, L.; Yerushalmi, Y. (1999). "Web Caching with Consistent Hashing". Computer Networks 31 (11): 1203–1213. doi:10.1016/S1389-1286(99)00055-9.
- ↑ http://docs.openstack.org/developer/swift/ring.html
- ↑ DeCandia, G.; Hastorun, D.; Jampani, M.; Kakulapati, G.; Lakshman, A.; Pilchin, A.; Sivasubramanian, S.; Vosshall, P.; Vogels, W. (2007). "Dynamo: Amazon's Highly Available Key-Value Store". Proceedings of the 21st ACM Symposium on Operating Systems Principles.
- ↑ http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
- ↑ Lakshman, Avinash; Malik, Prashant (2010). "Cassandra: a decentralized structured storage system". ACM SIGOPS Operating Systems Review.
- ↑ "Design -- Voldemort". http://www.project-voldemort.com/''. Archived from the original on 9 February 2015. Retrieved 9 February 2015.
Consistent hashing is a technique that avoids these problems, and we use it to compute the location of each key on the cluster.
- ↑ Akka Routing
- ↑ "Riak Concepts".
- ↑ http://www.gluster.org/2012/03/glusterfs-algorithms-distribution/
- ↑ "Skylable architecture".