Confusion matrix
In the field of machine learning, a confusion matrix, also known as a contingency table or an error matrix [1] , is a specific table layout that allows visualization of the performance of an algorithm, typically a supervised learning one (in unsupervised learning it is usually called a matching matrix). Each column of the matrix represents the instances in a predicted class, while each row represents the instances in an actual class. The name stems from the fact that it makes it easy to see if the system is confusing two classes (i.e. commonly mislabeling one as another).
Example
If a classification system has been trained to distinguish between cats, dogs and rabbits, a confusion matrix will summarize the results of testing the algorithm for further inspection. Assuming a sample of 27 animals — 8 cats, 6 dogs, and 13 rabbits, the resulting confusion matrix could look like the table below:
| |||||||||||||||||||||
| In this confusion matrix, of the 8 actual cats, the system predicted that three were dogs, and of the six dogs, it predicted that one was a rabbit and two were cats. We can see from the matrix that the system in question has trouble distinguishing between cats and dogs, but can make the distinction between rabbits and other types of animals pretty well. All correct guesses are located in the diagonal of the table, so it's easy to visually inspect the table for errors, as they will be represented by values outside the diagonal. | |||||||||||||||||||||
Table of confusion
In predictive analytics, a table of confusion (sometimes also called a confusion matrix), is a table with two rows and two columns that reports the number of false positives, false negatives, true positives, and true negatives. This allows more detailed analysis than mere proportion of correct guesses (accuracy). Accuracy is not a reliable metric for the real performance of a classifier, because it will yield misleading results if the data set is unbalanced (that is, when the number of samples in different classes vary greatly). For example, if there were 95 cats and only 5 dogs in the data set, the classifier could easily be biased into classifying all the samples as cats. The overall accuracy would be 95%, but in practice the classifier would have a 100% recognition rate for the cat class but a 0% recognition rate for the dog class.
Assuming the confusion matrix above, its corresponding table of confusion, for the cat class, would be:
| 5 true positives (actual cats that were correctly classified as cats) |
2 false positives (dogs that were incorrectly labeled as cats) |
| 3 false negatives (cats that were incorrectly marked as dogs) |
17 true negatives (all the remaining animals, correctly classified as non-cats) |
The final table of confusion would contain the average values for all classes combined.
|
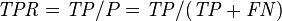
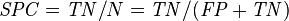
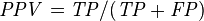
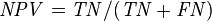
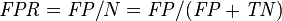
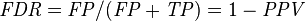
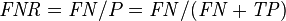
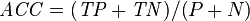
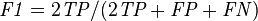
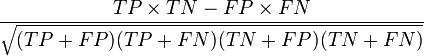
Let us define an experiment from P positive instances and N negative instances for some condition. The four outcomes can be formulated in a 2×2 contingency table or confusion matrix, as follows:
| Condition (as determined by "Gold standard") | |||||
| Total population | Condition positive | Condition negative | Prevalence = Σ Condition positive/Σ Total population | ||
| Test outcome |
Test outcome positive |
True positive | False positive (Type I error) |
Positive predictive value (PPV), Precision = Σ True positive/Σ Test outcome positive | False discovery rate (FDR) = Σ False positive/Σ Test outcome positive |
| Test outcome negative |
False negative (Type II error) |
True negative | False omission rate (FOR) = Σ False negative/Σ Test outcome negative | Negative predictive value (NPV) = Σ True negative/Σ Test outcome negative | |
| Accuracy (ACC) = Σ True positive + Σ True negative/Σ Total population | True positive rate (TPR), Sensitivity, Recall = Σ True positive/Σ Condition positive | False positive rate (FPR), Fall-out = Σ False positive/Σ Condition negative | Positive likelihood ratio (LR+) = TPR/FPR | Diagnostic odds ratio (DOR) = LR+/LR− | |
| False negative rate (FNR) = Σ False negative/Σ Condition positive | True negative rate (TNR), Specificity (SPC) = Σ True negative/Σ Condition negative | Negative likelihood ratio (LR−) = FNR/TNR | |||
See also
- Binary classification
- Sensitivity and specificity
- Signal detection theory
- Type I and type II errors
References
- ↑ Stehman, Stephen V. (1997). "Selecting and interpreting measures of thematic classification accuracy". Remote Sensing of Environment 62 (1): 77–89. doi:10.1016/S0034-4257(97)00083-7.
- ↑ Fawcett, Tom (2006). "An Introduction to ROC Analysis". Pattern Recognition Letters 27 (8): 861 – 874. doi:10.1016/j.patrec.2005.10.010.
- ↑ Powers, David M W (2011). "Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation" (PDF). Journal of Machine Learning Technologies 2 (1): 37–63.