Conditional mutual information
In probability theory, and in particular, information theory, the conditional mutual information[1][2] is, in its most basic form, the expected value of the mutual information of two random variables given the value of a third.
Definition
For discrete random variables 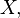
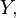 and
and 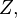 we define
we define
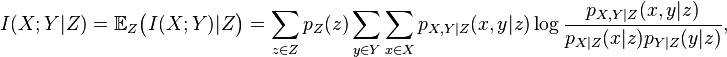
where the marginal, joint, and/or conditional probability mass functions are denoted by 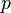 with the appropriate subscript. This can be simplified as
with the appropriate subscript. This can be simplified as
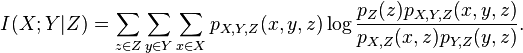
Alternatively, we may write[3] in terms of joint and conditional entropies as
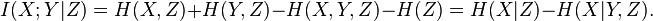
This can be rewritten to show its relationship to mutual information
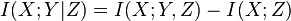
usually rearranged as the chain rule for mutual information
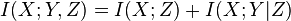
Another equivalent form of the above is
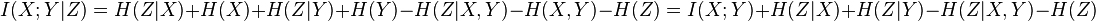
Conditioning on a third random variable may either increase or decrease the mutual information: that is, the difference 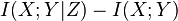 , called the interaction information, may be positive, negative, or zero, but it is always true that
, called the interaction information, may be positive, negative, or zero, but it is always true that
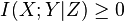
for discrete, jointly distributed random variables X, Y, Z. This result has been used as a basic building block for proving other inequalities in information theory, in particular, those known as Shannon-type inequalities.
Like mutual information, conditional mutual information can be expressed as a Kullback–Leibler divergence:
![I(X;Y|Z) = D_{\mathrm{KL}}[ p(X,Y,Z) \| p(X|Z)p(Y|Z)p(Z) ].](../I/m/545f1e5ef74381f119c5aa3d869238e2.png)
Or as an expected value of simpler Kullback–Leibler divergences:
![I(X;Y|Z) = \sum_{z \in Z} p( Z=z ) D_{\mathrm{KL}}[ p(X,Y|z) \| p(X|z)p(Y|z) ],](../I/m/be756eb0ca70d1e219e23da6843465c8.png)
![I(X;Y|Z) = \sum_{y \in Y} p( Y=y ) D_{\mathrm{KL}}[ p(X,Z|y) \| p(X|Z)p(Z|y) ].](../I/m/f9671b745ece135ca3d279f758095d99.png)
More general definition
A more general definition of conditional mutual information, applicable to random variables with continuous or other arbitrary distributions, will depend on the concept of regular conditional probability. (See also.[4][5])
Let 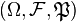 be a probability space, and let the random variables X, Y, and Z each be defined as a Borel-measurable function from
be a probability space, and let the random variables X, Y, and Z each be defined as a Borel-measurable function from 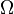 to some state space endowed with a topological structure.
to some state space endowed with a topological structure.
Consider the Borel measure (on the σ-algebra generated by the open sets) in the state space of each random variable defined by assigning each Borel set the 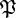 -measure of its preimage in
-measure of its preimage in 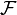 . This is called the pushforward measure
. This is called the pushforward measure 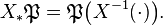 The support of a random variable is defined to be the topological support of this measure, i.e.
The support of a random variable is defined to be the topological support of this measure, i.e. 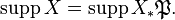
Now we can formally define the conditional probability measure given the value of one (or, via the product topology, more) of the random variables. Let 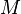 be a measurable subset of
be a measurable subset of 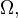 (i.e.
(i.e. 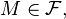 ) and let
) and let 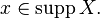 Then, using the disintegration theorem:
Then, using the disintegration theorem:
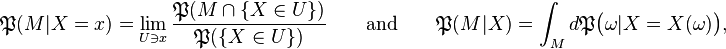
where the limit is taken over the open neighborhoods 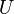 of
of 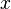 , as they are allowed to become arbitrarily smaller with respect to set inclusion.
, as they are allowed to become arbitrarily smaller with respect to set inclusion.
Finally we can define the conditional mutual information via Lebesgue integration:
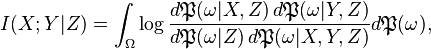
where the integrand is the logarithm of a Radon–Nikodym derivative involving some of the conditional probability measures we have just defined.
Note on notation
In an expression such as 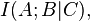
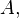
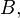 and
and 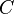 need not necessarily be restricted to representing individual random variables, but could also represent the joint distribution of any collection of random variables defined on the same probability space. As is common in probability theory, we may use the comma to denote such a joint distribution, e.g.
need not necessarily be restricted to representing individual random variables, but could also represent the joint distribution of any collection of random variables defined on the same probability space. As is common in probability theory, we may use the comma to denote such a joint distribution, e.g. 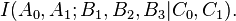 Hence the use of the semicolon (or occasionally a colon or even a wedge
Hence the use of the semicolon (or occasionally a colon or even a wedge 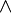 ) to separate the principal arguments of the mutual information symbol. (No such distinction is necessary in the symbol for joint entropy, since the joint entropy of any number of random variables is the same as the entropy of their joint distribution.)
) to separate the principal arguments of the mutual information symbol. (No such distinction is necessary in the symbol for joint entropy, since the joint entropy of any number of random variables is the same as the entropy of their joint distribution.)
Multivariate mutual information
The conditional mutual information can be used to inductively define a multivariate mutual information in a set- or measure-theoretic sense in the context of information diagrams. In this sense we define the multivariate mutual information as follows:
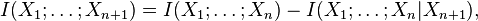
where
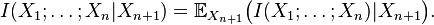
This definition is identical to that of interaction information except for a change in sign in the case of an odd number of random variables. A complication is that this multivariate mutual information (as well as the interaction information) can be positive, negative, or zero, which makes this quantity difficult to interpret intuitively. In fact, for n random variables, there are 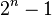 degrees of freedom for how they might be correlated in an information-theoretic sense, corresponding to each non-empty subset of these variables. These degrees of freedom are bounded by various Shannon- and non-Shannon-type inequalities in information theory.
degrees of freedom for how they might be correlated in an information-theoretic sense, corresponding to each non-empty subset of these variables. These degrees of freedom are bounded by various Shannon- and non-Shannon-type inequalities in information theory.
References
- ↑ Wyner, A. D. (1978). "A definition of conditional mutual information for arbitrary ensembles". Information and Control 38 (1): 51–59. doi:10.1016/s0019-9958(78)90026-8.
- ↑ Dobrushin, R. L. (1959). "General formulation of Shannon's main theorem in information theory". Ushepi Mat. Nauk. 14: 3–104.
- ↑ K. Makarychev et al. A new class of non-Shannon-type inequalities for entropies. Communications in Information and Systems, Vol. 2, No. 2, pp. 147–166, December 2002 PDF
- ↑ Regular Conditional Probability on PlanetMath
- ↑ D. Leao, Jr. et al. Regular conditional probability, disintegration of probability and Radon spaces. Proyecciones. Vol. 23, No. 1, pp. 15–29, May 2004, Universidad Católica del Norte, Antofagasta, Chile PDF