Conditional entropy
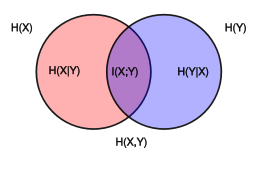
In information theory, the conditional entropy (or equivocation) quantifies the amount of information needed to describe the outcome of a random variable 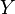 given that the value of another random variable
given that the value of another random variable 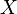 is known. Here, information is measured in shannons, nats, or hartleys. The entropy of conditioned on is written as
is known. Here, information is measured in shannons, nats, or hartleys. The entropy of conditioned on is written as 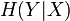 .
.
Definition
If 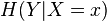 is the entropy of the variable conditioned on the variable taking a certain value
is the entropy of the variable conditioned on the variable taking a certain value 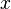 , then is the result of averaging over all possible values that may take.
, then is the result of averaging over all possible values that may take.
Given discrete random variables with domain 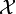 and with domain
and with domain 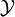 , the conditional entropy of given is defined as:[1]
, the conditional entropy of given is defined as:[1]
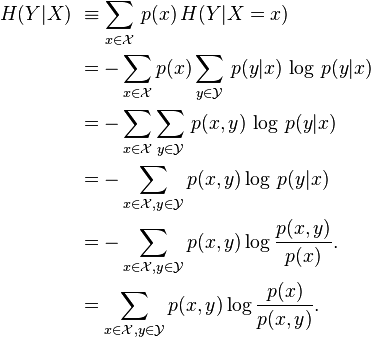
Note: It is understood that the expressions 0 log 0 and 0 log (c/0) for fixed c>0 should be treated as being equal to zero.
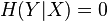 if and only if the value of is completely determined by the value of . Conversely,
if and only if the value of is completely determined by the value of . Conversely, 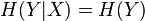 if and only if and are independent random variables.
if and only if and are independent random variables.
Chain rule
Assume that the combined system determined by two random variables X and Y has joint entropy 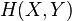 , that is, we need bits of information to describe its exact state.
Now if we first learn the value of , we have gained
, that is, we need bits of information to describe its exact state.
Now if we first learn the value of , we have gained 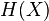 bits of information.
Once is known, we only need
bits of information.
Once is known, we only need 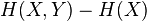 bits to describe the state of the whole system.
This quantity is exactly , which gives the chain rule of conditional entropy:
bits to describe the state of the whole system.
This quantity is exactly , which gives the chain rule of conditional entropy:
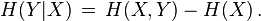
The chain rule follows from the above definition of conditional entropy:
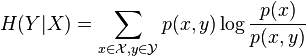
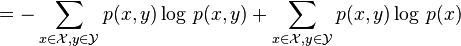
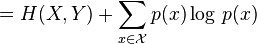
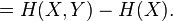
Bayes' rule
Bayes' rule for conditional entropy states
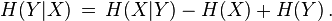
Proof. 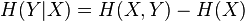 and
and 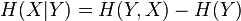 . Symmetry implies
. Symmetry implies 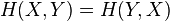 . Subtracting the two equations implies Bayes' rule.
. Subtracting the two equations implies Bayes' rule.
Generalization to quantum theory
In quantum information theory, the conditional entropy is generalized to the conditional quantum entropy. The latter can take negative values, unlike its classical counterpart.
Bayes' rule does not hold for conditional quantum entropy, since 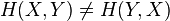 .
.
Other properties
For any and :
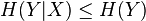
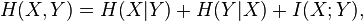
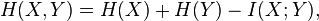
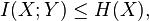
where 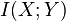 is the mutual information between and .
is the mutual information between and .
For independent and :
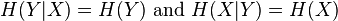
Although the specific-conditional entropy, 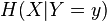 , can be either less or greater than
, can be either less or greater than 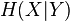 , can never exceed .
, can never exceed .