Compositional data
In statistics, compositional data are quantitative descriptions of the parts of some whole, conveying exclusively relative information.
This definition, given by John Aitchison (1986) has several consequences:
- A compositional data point, or composition for short, can be represented by a positive real vector with as many parts as considered. Sometimes, if the total amount is fixed and known, one component of the vector can be omitted.
- As compositions only carry relative information, the only information is given by the ratios between components. Consequently, a composition multiplied by any positive constant contains the same information as the former. Therefore, proportional positive vectors are equivalent when considered as compositions.
- As usual in mathematics, equivalent classes are represented by some element of the class, called a representative. Thus, equivalent compositions can be represented by positive vectors whose components add to a given constant
 . The vector operation assigning the constant sum representative is called closure and is denoted by
. The vector operation assigning the constant sum representative is called closure and is denoted by ![\scriptstyle\mathcal{C}[\cdot]](../I/m/cbbb2d3ca3b877a2e047514ed05b6963.png) :
:
![\mathcal{C}[x_1,x_2,\dots,x_D]=\left[\frac{x_1}{\sum_{i=1}^D x_i},\frac{x_2}{\sum_{i=1}^D x_i}, \dots,\frac{x_D}{\sum_{i=1}^D x_i}\right],\](../I/m/a66434f1bb18610a04d017fd115bf612.png)
where D is the number of parts (components) and ![[\cdot]](../I/m/49ea69f2b45ae27658d8b27c5e006d68.png) denotes a row vector.
denotes a row vector.
- Compositional data can be represented by constant sum real vectors with positive components, and this vectors span a simplex, defined as
![\mathcal{S}^D=\left\{\mathbf{x}=[x_1,x_2,\dots,x_D]\in\mathbb{R}^D \left| x_i>0,i=1,2,\dots,D; \sum_{i=1}^D x_i=\kappa \right. \right\}. \](../I/m/cb14555a04cd601de1c24bdef9339245.png)
This is the reason why 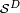 is considered to be the sample space of compositional data. The positive constant is arbitrary. Frequent values for are 1 (per unit), 100 (percent, %), 1000, 106 (ppm), 109 (ppb), ...
is considered to be the sample space of compositional data. The positive constant is arbitrary. Frequent values for are 1 (per unit), 100 (percent, %), 1000, 106 (ppm), 109 (ppb), ...
- In statistics, compositional data is frequently considered to be data in which each data point is an D-tuple of nonnegative numbers whose sum is 1. Typically each of the D components xi of each data point [x1, ..., xD] says what proportion (or "percentage") of a statistical unit falls into the ith category in a list of D categories. Very often ternary plots are used in analysis of compositional data to represent a three part composition.
- An alternative nomenclature for compositional analysis is simplicial analysis, motivated by the concept of simplicial sets.
Remarks on the definition of the simplex:
- In mathematical frameworks, the superscript of , accounting for the number of parts, is often changed to D − 1, describing the dimension.
- The components of the vector are assumed to be positive. However, in some definitions of the simplex, non-negative components are admitted. Here null components are avoided, because ratios between components of which some are zero are meaningless.
Examples
- Each data point may correspond to a rock composed of three different minerals; a rock of which 10% is the first mineral, 30% is the second, and the remaining 60% is the third would correspond to the triple [0.1, 0.3, 0.6]; a data set would contain one such triple for each rock in a sample of rocks.
- Each data point may correspond to a town; a town in which 35% of the people are Christians, 55% are Muslims, 6% are Jews, and the remaining 4% are others would correspond to the quadruple [0.35, 0.55, 0.06, 0.04]; a data set would correspond to a list of towns.
- In chemistry, compositions can be expressed as molar concentrations of each component. As the sum of all concentrations is not determined, the whole composition of D parts is needed and thus expressed as a vector of D molar concentrations. These compositions can be translated into weight per cent multiplying each component by the appropriated constant.
- In a survey, the proportions of people positively answering some different items can be expressed as percentages. As the total amount is identified as 100, the compositional vector of D components can be defined using only D − 1 components, assuming that the remaining component is the percentage needed for the whole vector to add to 100.
- In probability and statistics, a partition of the sampling space into disjoint events is described by the probabilities assigned to such events. The vector of D probabilities can be considered as a composition of D parts. As they add to one, one probability can be suppressed and the composition is completely determined.
External links
- CoDaWeb - Compositional Data Website
- Pawlowsky-Glahn, V., Egozcue, J.J., Tolosana-Delgado, R. (2007), Lecture Notes on Compositional Data Analysis.
- Why, and How, Should Geologists Use Compositional Data Analysis (wikibook)
References
- J. Aitchison, 1986: The Statistical Analysis of Compositional Data, Chapman & Hall, reprinted in 2003 with additional material by The Blackburn Press